
In cryptography audits, we often find vulnerabilities labeled as l 2024-4-25 06:0:0 Author: blog.quarkslab.com(查看原文) 阅读量:19 收藏
In cryptography audits, we often find vulnerabilities labeled as low or informational, usually for "non-compliance"... So, what should we do with them?
As auditors, we sometimes struggle when trying to explain to our customers that it is always better to reach the maximum level of security, instead of the minimal required effort. It does not always help that we cryptographers are known to speak in the language of Mordor (we just call it mathematics) and live deep in a zero-knowledge cave.
Introduction
At Quarkslab, we conduct cryptography audits on a variety of products -- with the actual quantity of crypto inside ranging from "I think there's a key in there somewhere" to "We need two senior cryptographers on this one". We often find vulnerabilities that do not actually pose any immediate threat: for example the product may not follow the official recommendations, or be generally less secure than the state of the art. We usually propose mitigations to the vulnerabilities, even for the low-impact or informational ones, to help the vendors fix these issues. Some customers may blindly trust our judgment, but others will not want to make too many changes to their products, especially if they do not fully understand why -- and that, actually, is understandable -- for example when being asked to update to post-quantum primitives, a rather recent issue.
For audits meant to lead to a certification, we can hide behind the state agencies, as they have the last word and were the ones to issue the recommendations we base ourselves on in the first place. In other cases, it may be difficult to convince the customers to protect themselves against a very strong adversary, or against unlikely scenarios.
As auditors and cryptographers, we know and understand the importance of long-term security, and of keeping up to date; even standard and commonly used primitives might turn out to be flawed when looked at from new angles. We also know that the adequate solutions are not always the cheapest.
Moreover, currently, the recommendation guides or sources for the security parameters and what primitives to use are somewhat static, and we often have to hunt for recent benchmarks of the primitives we're studying on public GitHub repositories. Other useful initiatives are not always up to date, such as BlueKrypt's keylength website, which hasn't been updated since 2020.
Let's dive into those second-rate vulnerabilities!
Typology of vulnerabilities
We have separated the types of vulnerabilities into several sub-categories, based on past audits at Quarkslab or other public reports. This list is probably not exhaustive, but it does cover most of what we've experienced.
A note on vulnerability assessment
When evaluating the risk level of a vulnerability, we take several parameters into account. The most common way to proceed is by rating the likelihood (which depends on the required skills, the reward, attacker type, and required resources) and the impact (which depends on what type of data is disclosed/corrupted and service interruption) at either low, medium, or high, and placing them on a three-by-three alignment chart (see the Synopsys post for more details).
Low impact and low likelihood lead to informational vulnerabilities, while low impact and medium likelihood, or vice versa, lead to low risk vulnerabilities. Fixing informational vulnerabilities is considered best practice but not mandatory; as for the low ones, we recommend fixing them "if possible".
The granularity is not always perfect, and we discuss here why it might be best to always consider those vulnerabilities seriously. We first list the categories below, then discuss them in the next sections.
- Not standard.
- Non-standard usage.
- Low security, still technically secure.
- Safety net saves all.
- Crypto works, the rest doesn't.
- BONUS ROUND -- Compliance is irrelevant.
Not standard
Sometimes, the primitive used in the product is not standard, e.g. a homemade or modified primitive.
We might also put in this category primitives that were part of a competition (AES, NIST PQ) and did not make it to the final round, but that do not present known vulnerabilities, such as the MARS cipher.
For those "less-used" primitives, the main issue is that they will not have been tested and studied as extensively as the standard, which in turn makes them more likely to have hidden vulnerabilities. On the other hand, one might be tempted to use such primitives specifically for that reason.
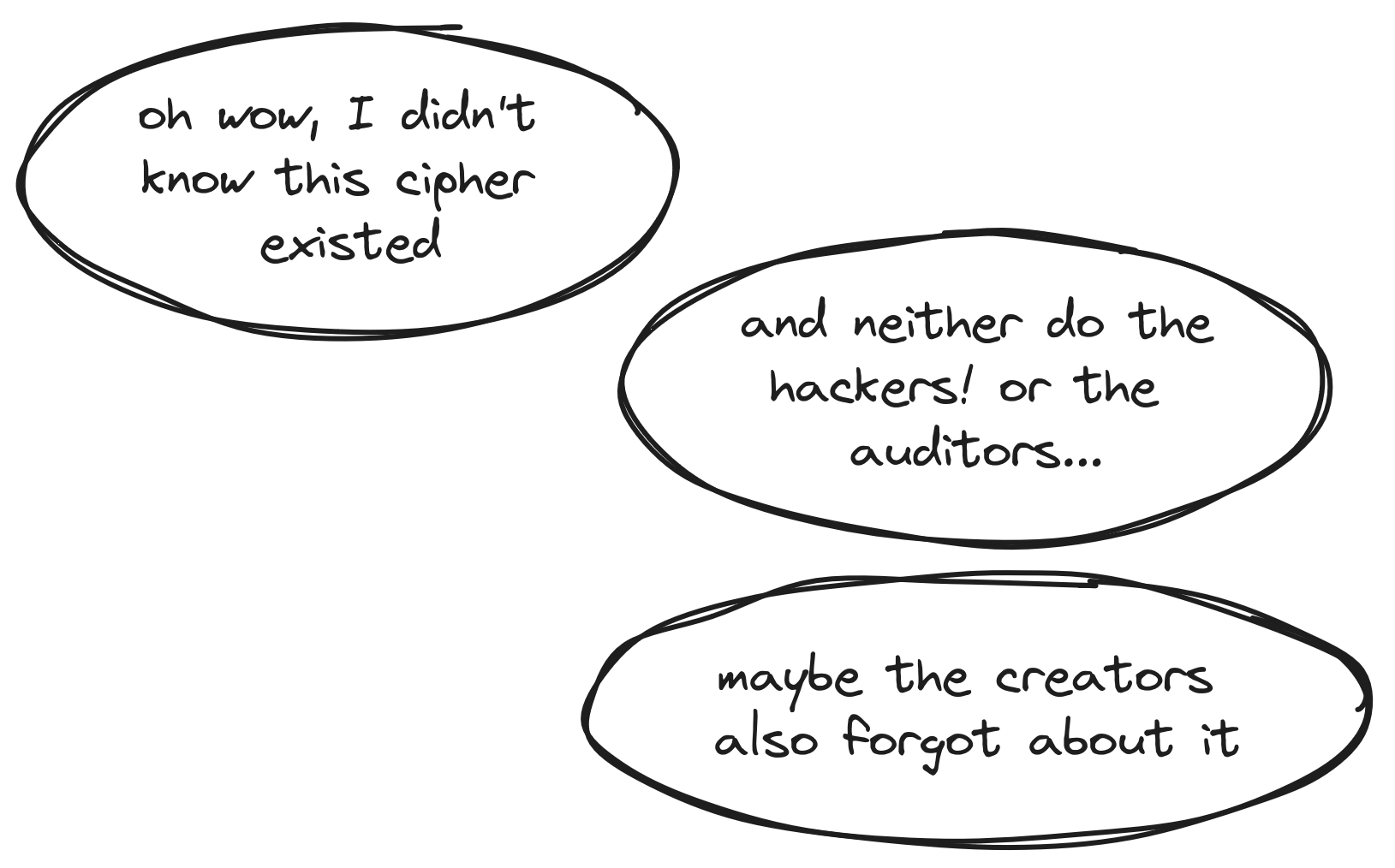
This is also the case for homemade or modified primitives, though we argue that they will still need security proofs, or a specific audit. In general, unless you are trying to solve a problem that was never solved (properly) before, there is no reason for you to roll your own crypto. Whether you need something fast, something light, etc., there is probably a well-studied primitive that fits your situation.
Non-standard usage
The primitive itself might be standard, but it is used in a non-standard way, e.g. using a UUIDv4 generator for other cryptographically random values that are not UUIDs. Some examples here might fall into the "bad coding practices" category.
In cryptography, randomness (the source, how it is handled, etc.) is a rather touchy subject. There are many wrong ways to work with random generation, and many languages or libraries make the distinction between "generic" randomness and cryptographically secure randomness, for example in Java with
java.util.Randomvs.java.security.SecureRandomor less explicitly in Go withmath/randvs.crypto/rand. These "misuse" cases are not the ones we are interested in here, as the related vulnerabilities are surely not low or informational.
Now, of course, you can use various cryptographic building blocks to create a pseudo-random number generator (that expands the randomness, it does not create it), but those PRNGs are, in turn, standardized as such. In the "non-standard usage" case, we are mostly talking about using a function meant to generate a specific element, used for another purpose, such as generating an IV via a key generation function (or outright using a public key as an IV), or vice versa. While it is highly likely that the same subfunctions are called under the hood for the random IV and key generation functions, weaknesses might still be introduced this way.
Other than random generation, we can find other types of misuse, like in the case of key derivation functions (KDF): for example, we have seen products using bcrypt, a password-hashing function designed for storage, as a KDF taking a password as input, instead of using PBKDF2 (whose name is rather explicit), scrypt, or Argon -- bcrypt outputs a fixed number of bytes (24), and its cost is not as customizable as the aforementioned KDFs.
Low security, still technically secure
The security level is too low, but it has no impact, e.g. the attacker won't have enough computing power and maybe "store now, decrypt later" is irrelevant.
The latter is the case for example with values that must remain confidential only for a (relatively) short amount of time, such as the output of an election (not individual votes), or documents used during some legal proceedings.
We might also put in this category implementations with parameters that are just below the recommendations, as those are defined with very strong (or even not-yet-existing) adversaries in mind. Obviously, the parameters given in the recommendations have to be stronger than what is strictly necessary at the moment, to be safe for more than a few months, but they are not exaggerated. E.g. the current modulus size for RSA is 3072, higher than current factorization records (829 bits as of this writing), but considered to be safe at least up until 2030, and probably beyond, while not incurring a slow key generation like choosing 16384 would.
In this kind of situation, it does feel a bit silly to write "This product uses 200,000 iterations for PBKDF2-HMAC-SHA512 instead of 210,000" in a vulnerability report. One might also wonder how this close-but-not-quite number was picked by the developers in the first place -- perhaps to thwart rainbow tables computed for the correct value, or by forgetting their glasses.

In some cases where products do have limited storage or computation power, such as IoT devices or older hardware, trade-offs must be considered, though as mentioned above, specific primitives exist for these situations, but the hardware may not be so flexible. Realistic, precise attacker models are especially important in those cases to help us make the best choices.
Safety net saves all
This type of vulnerability can stem from a moderate or higher version of any of the above but there is a "second layer" of security that saves it, e.g. not using the maximum possible number of iterations for PBKDF2, but having a long, random input instead of a human-generated password.
This category does not include the case where several weak layers are used instead of a single strong one, as, once again, resulting weaknesses will usually not be just low or informational.
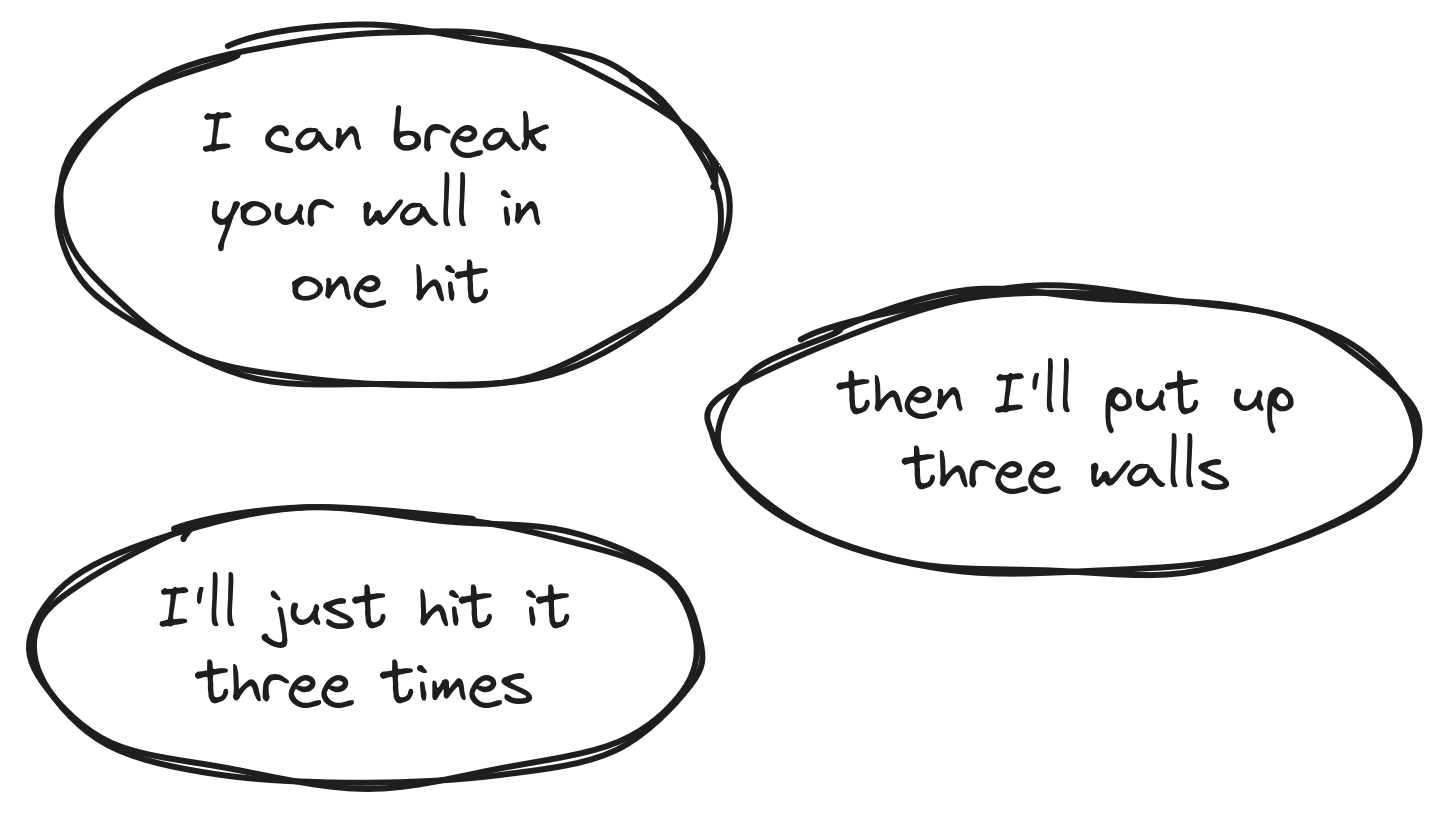
In general, it is the use of a primitive presenting a given weakness that is somehow thwarted by another mechanism, or by the specific situation, like a cipher that reveals recurring patterns in a plaintext but is used on a random input (which should, by definition, not present any repeating patterns unless it is very long). It is still important in this case to use a (version of the) primitive that does not present this weakness, to lower the burden on the other mechanism(s), to respect the best practices, and to ensure that, should the situation or the input change within the protocol, it does not result into a weakness, or is less impactful. We might also consider the possibility that someone would reuse this part of the code in another context where there is no "safety net".
Convincing our customers to fix this kind of vulnerability is usually difficult, as we are basically asking someone to get a stronger belt, when they're already wearing sturdy suspenders.
Crypto works, the rest doesn't
This is more of a corner case: the crypto is okay, but the architecture is not. The most common example would be a situation where the server is a Single Point of Failure, i.e. it is too trusted, or it would result in a very high impact if compromised.
Quite often, this case depends more on the attacker model as well as the scope of the audit, hence the vulnerability often being counted as informational because there was no time allotted to fully study it, but the auditors still wished to inform the vendors.
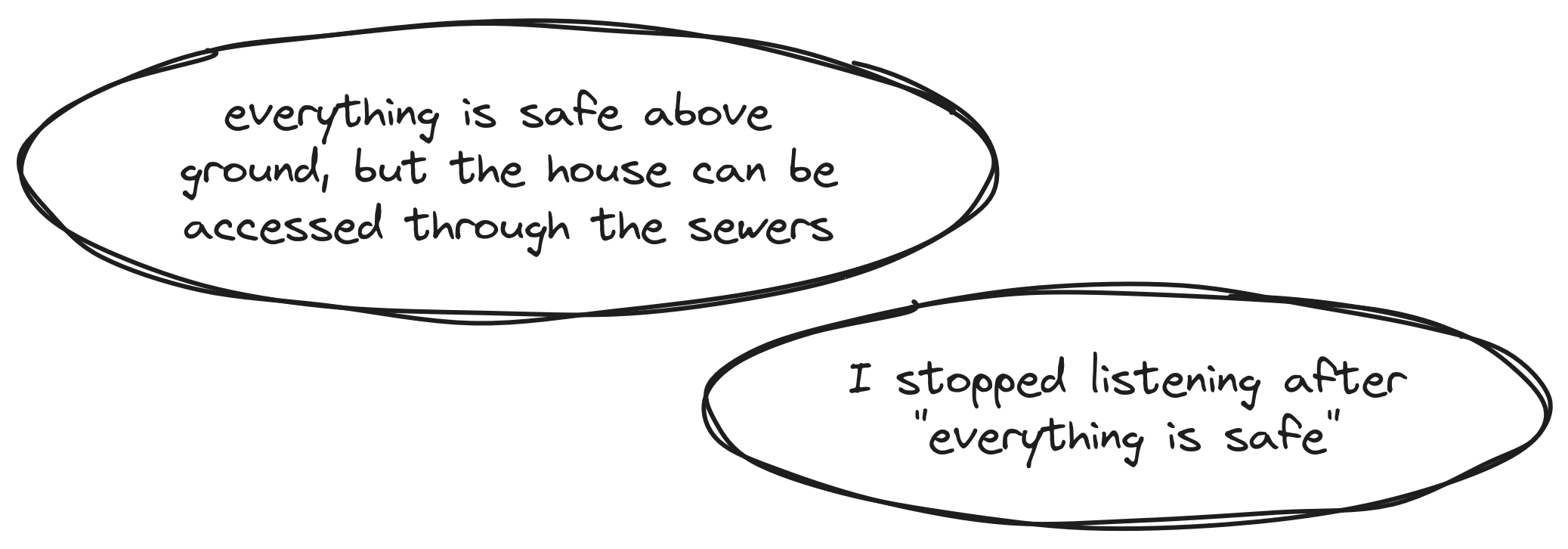
Servers are not the only possible examples here. This category will generally concern situations where a weak link, such as a user's smartphone or a third-party application, is given a lot of trust. There obviously cannot be a situation where nothing and no one is trusted, but reasonable choices must be made.
In any case, the attacker model should (1) be defined during the theoretical part of the creation of the product, and used at that point, and (2) be disclosed to the product's users.
BONUS ROUND -- Compliance is irrelevant
We also have some (rare) cases where compliance with the standards is irrelevant, or judged differently.
The most prominent example can be found in white-box cryptography, where external encodings are specifically meant to obfuscate the underlying implementation, thus making it look different from the standards.
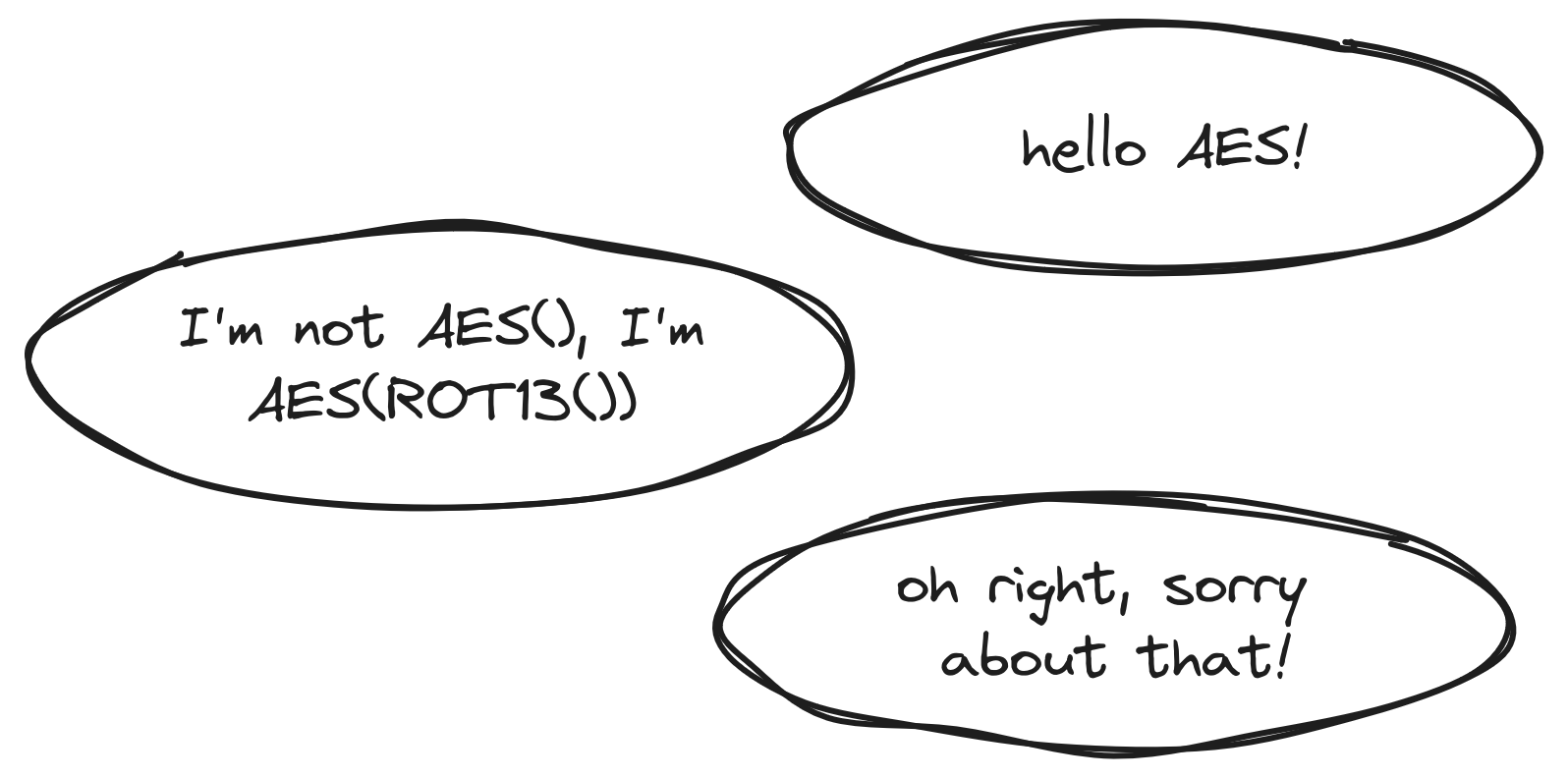
In this case, the vulnerabilities found could be the opposite of the others, where the implementation is too compliant, which would be a weakness.
Vendor reactions
We have already hinted at the possible reactions in the previous sections, but we will discuss them more specifically here. Let it be noted that we do not blame anyone, and the whole point of this blogpost is to talk about these -- often uncomfortable -- situations.
In an ideal case, the vendor has complete trust in us, they have the time and resources necessary to fully implement our proposed mitigations.
Usually, though, we are faced with a hybrid situation: the easiest mitigations are accepted, as well as those for the vulnerabilities deemed critical or high, but those moderate and below that are too costly may not be fixed without lengthy discussions.
The audit report
We have also sometimes been asked to rewrite the attacker model in the final report to artificially lower the severity of some vulnerabilities, or remove them entirely.
- Perhaps we could consider that the server is fully trusted and secure?
- We use a third-party solution for this-and-that, why is this vulnerability our problem?
- Production is scheduled for tomorrow, so, how can you rewrite this to make it sound less severe?

Understanding the situation
Obviously, and as we've said, it is perfectly understandable that vendors would not want to start some long and potentially difficult modifications to their product without the assurance that it will be worth it, and would protect them from actually harmful weaknesses now. That being said, it can still be frustrating when we do not manage to get our point across. We can also see how this highlights the importance of conducting an audit before implementing (yes, yes, it's not an audit, it's consulting), to avoid the most glaring issues.
These issues are easier to deal with in the context of a certification -- dura lex, sed lex, not choice but to address them. Again, to avoid the frustration of "missing" the certification for seemingly minor vulnerabilities, it is generally possible to conduct a pre-evaluation audit to make sure that everything is pristine when the real one comes.
At this point, it is important to work together and propose possible fixes for the low or informational vulnerabilities, as we do for those with higher ranking.
Angles for the discussions
The vulnerabilities that we are dealing with here should definitely not be ignored, and should at the very least be added to the product's roadmap.
A possible angle with the vendor is the comparison with the state of the art: if the competitors are reaching better security, it is a great argument! For instance, Signal and Apple recently added post-quantum cryptography to their messaging protocols, which seems to have motivated other messaging apps to place this topic higher up on their to-do list.
We might also insist on the facts that low-impact vulnerabilities can sometimes stack-up and lead to a bigger issue, which is why solving them as they come up is important. On the topic of "long-term preparation", we can also add that a vulnerability counted as low now, because it requires a very strong adversary for example (see the previous subsection on low-but-not-low security), may be re-qualified as moderate and then high in the coming years, so the update might as well be done now -- again, we've seen that the current security parameters are chosen to be valid for several years.
Underlying issue
We joked at the beginning of this post about cryptographers speaking a different language, and it is unfortunately how it feels on both sides. Cryptography is often seen as being too theoretical, left for the magicians to decipher (pun intended), and -- because it is nice to keep on using fantasy and myths to talk about ourselves -- we also sometimes feel like Cassandra prophesizing the arrival of stronger attackers... and no one believes us.
It is not realistic to ask our customers to follow a crash course on every cryptographic topic relevant to their product, but we do try to give short (re)freshers in our reports or in the restitution meetings.
The gap between theory and practice is still rather long but progressively not quite as wide thanks to the creation of conferences such as Real World Crypto, and the works of many wonderful people on the internet with accessible blogs and newsletters, and everyone else who manages to sprinkle bits of cryptography everywhere.
It is sad to say though that very impactful cyber-attacks are usually what helps the "general public" care more about cybersecurity as a whole (and cryptography when it applies), as it is (almost) invisible the rest of the time. Still, we now like to start academic articles by talking about how the Paper Topic is now everywhere and should therefore be considered very seriously, and we have seen some buzzwords make their ways outside the cybersecurity circles, with "end-to-end encryption" being a good recent example.
Let's keep up the good work and spread the love and understanding of cryptography as best as we can.
Takeaway
The conclusion of this blogpost is not necessarily groundbreaking, but it bears repeating: theory and practice can and should work hand-in-hand. While we understand the constraints on the vendors' side, monetary restrictions should not take precedence over security and privacy, especially if those are selling points for the product. On the other hand, we know part of our job is to educate on the issues to ensure that they are addressed and prevent them from recurring in other products in the future.
To help us make our point, benchmarks and comparisons of existing protocols, primitives, and every possible option for those protocols and primitives should be more accessible and updated more often -- or, well, should actually exist in the first place. That would make it easier, for example, to show that increasing a parameter to reach the recommended value does not necessarily make it more costly on the product's side, or to explain why we suggest using this or that primitive instead of another to increase security/efficiency/resilience.
Keep in mind, however, that in the situations mentioned in this blogpost, the vendors themselves made the choice to ask for an audit, meaning the discussion has already started, and cases where vulnerabilities are found outside of official evaluations and responsibly disclosed may be more complicated, as the vendors were not expecting such a result to come in. On that matter, we recommend reading the recent piece by Albrecht and Paterson, "Analysing Cryptography in the Wild".
If you are curious, you can have a look at our other cryptography blogposts, or our audit reports.
Acknowledgements
Many thanks to Dahmun, Philippe, and Marion for the fruitful discussions, even back when this post was just an idea for an extended abstract, and thank you also to the reviewers for their time.
If you would like to learn more about our security audits and explore how we can help you, get in touch with us!
如有侵权请联系:admin#unsafe.sh