
阿里巴巴旗下通用人工智能研究团队目前已经推出参数高达 1100 亿的通义千问人工智能模型,和此前推出的同样相同,Qwen1.5-110B 版模型依然是开源免费提供的,任何人都可以获取该模型并根据需要进行微调和使用。
通义千问团队称近期开源社区陆续出现千亿参数规模以上的大型语言模型,这些模型都在各项评测中取得了杰出的成绩,通义千问现在也推出千亿规模参数的开源模型。

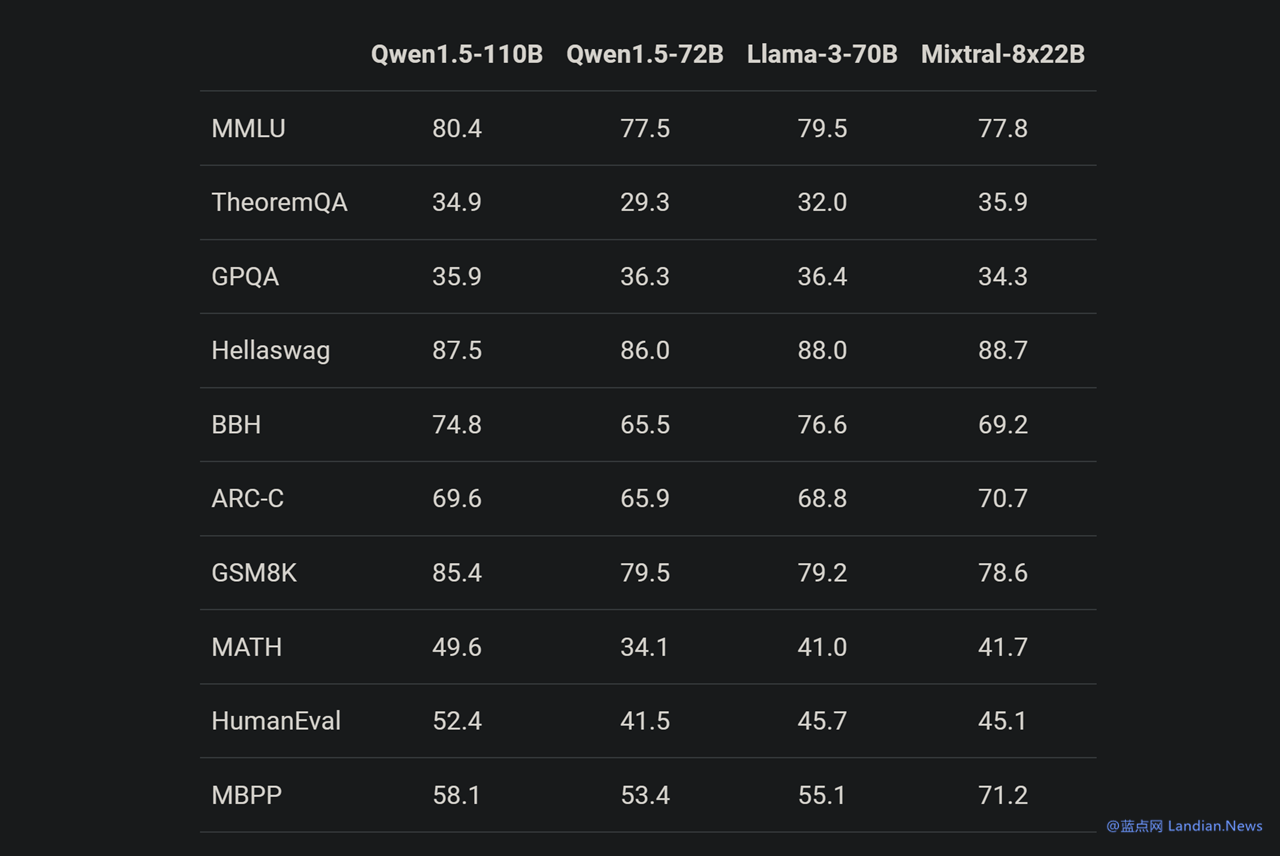
Qwen1.5-110B 是基于通义千问 1.5 系列训练的模型,在基础能力评估中与 Meta-Llama3-70B 版媲美,在 Chat 评估中表现出色,包括 MT-Bench 和 AlpacaEval 2.0 测试。
该模型采用 Transformer 解码器架构,但包含分组查询注意力 (GAQ),模型在推理时将会更加高效;110B 版模型支持 32K 上下文、支持英语、中文、法语、西班牙语、德语、俄语、日语、韩语、阿拉伯语、越南语等多种语言。
基准测试显示 Qwen1.5-110B 在基础能力方面与 Meta-Llama3-70B 版媲美,由于在这个模型中通义千问团队并没有对预训练方法进行大幅度改变,因此现在基础能力提升应该就是得益于增加模型 (参数) 规模。
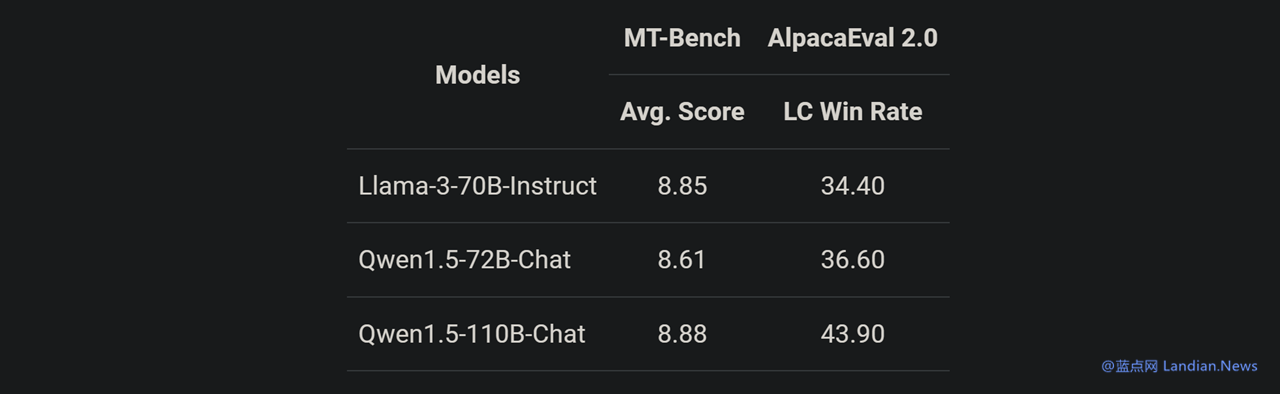
另一项测试似乎也证实这个观点,在与 Llama3-70B-Chat 以及 Qwen1.5-72B-Chat 相比,Qwen1.5-110B-Chat 能力都有提升,这表明在没有大幅度改变预训练方法的情况下,规模更大的基础语言模型也可以带来更好的 Chat 模型。
有兴趣的用户可以阅读 Qwen1.5 博客了解该系列模型使用方法,包括 Qwen1.5-110B 的下载和使用等:https://qwenlm.github.io/blog/qwen1.5/
版权声明:感谢您的阅读,除非文中已注明来源网站名称或链接,否则均为蓝点网原创内容。转载时请务必注明:来源于蓝点网、标注作者及本文完整链接,谢谢理解。