原文标题:Not One Less: Exploring Interplay between User Profiles and Items in Untargeted Attacks against Federated Recommendation
原文作者:郝玉蓉;陈喜辉;吕晓婷;刘吉强;祝咏升;万志国;Sjouke Mauw;王伟*
发表会议:ACM CCS 2024
主题类型:联邦推荐系统中的非定向投毒攻击
本次分享的论文“Not One Less: Exploring Interplay between User Profiles and Items in Untargeted Attacks against Federated Recommendation”,由北京交通大学为第一单位,卢森堡大学、之江实验室、中国铁道科学研究院为合作单位共同完成。该项研究深入探讨了联邦推荐(Federated Recommendation, FedRec)系统在抵御非定向投毒攻击方面的能力,揭示了其在先前研究中被低估的潜在威胁并提出可能的防御对策。
一. 非定向攻击通用框架
联邦推荐在用户隐私保护方面的显著优势,使其在个性化推荐领域展现出了广阔的发展前景。然而,其在安全层面的表现并未实现同等程度的强化。与定向攻击不同,非定向攻击波及范围广泛,这意味着几乎每个用户都可能遭受到不同程度的威胁。鉴于此,论文构建了第一个针对FedRec系统的非定向投毒攻击通用框架,并借助此框架识别了目前研究中尚未充分解决的挑战。
令 为理想情况下与用户 个人偏好完全匹配的推荐物品集合。FedRec的训练目标是通过模型优化,使 轮迭代训练后的预测结果 尽可能接近理想情况下的完美推荐 。令 为量化两集合间差异的任意度量函数, 和 表示由聚合器和用户维护的参数集。此时,FedRec的优化目标可以表示如下:
非定向攻击的优化目标在于通过计算所有恶意用户 的最佳梯度更新,以欺骗聚合器和正常用户对模型参数作出错误计算,从而使生成的恶意推荐结果与真实推荐结果之间的误差最大。具体地,优化目标可以表示如下:
其中, 。
值得注意的是,上述等式并不能直接参与优化。首要挑战在于正常用户𝑢在原始系统和被攻击系统中预测的推荐结果(即)不可获得,因为攻击的介入会导致正常的训练过程无法执行,同时,由于隐私保护机制,准确的用户嵌入信息也因被加入噪声或存储在用户本地设备上而无法直接访问,即不具备优化目标中所需的。
该挑战本质上在于如何获取正常用户的嵌入分布,以及获得用户嵌入分布后,如何据此设计最佳攻击样本完成模型投毒。
为此,文中为每个恶意用户准备了两个虚拟数据集。一个是虚拟用户集的用户嵌入,目的在于近似正常用户的嵌入分布;另一个是为每个虚拟用户精心构造的交互物品集,用于误导模型作出错误训练。对于实际存在的用户,执行攻击可以通过翻转其历史交互物品的标签实现,即将正样本标记为负样本,反之亦然。但对于虚拟用户,由于缺乏真实的历史交互数据,必须采用其他方法为其构建交互物品。硬采样是一种可行的解决方案,已经在相关文献中得到验证。具体来说,如果给定用户与某个物品进行交互的可能性很高,则将该物品标记为硬负样本(hard negative sample),并赋予0或最低评分;反之,则标记为硬正样本,并赋予1或最高评分。通过这种机制,非定向投毒攻击的目标可以进一步形式化为:
表示用户u对物品的真实评分r。
这一目标揭示了对非定向攻击性能至关重要的两个组件:用户抽样和交互物品抽样。用户抽样决定了攻击者是否能够有效地模拟正常用户的分布,而交互物品抽样则直接影响到恶意用户对梯度更新操作的误导程度。这两个基本组件实际上体现了攻击迭代过程中,正常用户与其交互物品之间的相互作用对投毒攻击的推动作用。进一步地,通过上述框架,可以识别出先前研究中未能妥善解决的关键挑战:
当前方法通常简单地使用单个恶意用户的嵌入表示来代表正常用户,一个直接的后果是需要大量的恶意用户来确保攻击者能逼近正常用户的分布。此外,假设攻击者控制的恶意用户总能恰当模拟正常用户的分布是困难的。
现有方法中的硬采样仅基于推荐评分进行,这种方式在模型训练的后期可能表现良好,但在模型参数尚未充分优化的早期阶段可能失效。
以往研究低估了攻击者能力。当恶意用户间共享信息并协同合谋时,与独立攻击相比,合谋可能对联邦推荐系统造成的损害更为严重。
二. 攻击策略FRecAttack2
图1展示了非定向投毒攻击FRecAttack2的攻击流程,接下来将分别对用户抽样和交互物品抽样进行详细说明。组件1:用户抽样
回想用户抽样的核心在于生成一组用户画像嵌入,以模拟近似正常用户的分布。根据FedRec系统的隐私保护机制 (如图2所示)和恶意用户是否合谋,可以确定4种不同的攻击模式。表1对本文中将使用的名称进行了标注。下面逐一介绍每种攻击模式下的虚拟用户抽样方法。
表1 FedRec中的攻击场景分类
| Attack type | Independent attack | Secret-Hiding | DP-based |
|---|---|---|---|
| IndSH | ✓ | ✓ | |
| ColSH | ✗ | ✓ | |
| IndDP | ✓ | ✓ | |
| ColDP | ✗ | ✓ |
IndSH:在此模式下,恶意用户独立进行用户抽样,不与其他恶意用户进行通信。这意味着每个参与训练的恶意用户仅能在其用户嵌入的邻域内进行虚拟用户采样。这种方法在每个恶意用户恰好位于正常用户分布的中心时效果最佳。显然,这种情况在有限先验知识下并不现实。然而,如果恶意用户的嵌入能够形成一个与正常用户真实分布相似的分布,那么与仅利用单一恶意用户嵌入的传统方法相比,IndSH能够实现更优的近似效果。
ColSH:与IndSH不同,在ColSH模式中,攻击者可以协作分析所有恶意用户的真实用户嵌入信息。尽管恶意用户数量有限,但这些嵌入仍然可以提供额外的分布信息,用以改善对正常用户嵌入分布的推断。其基本思想是对所有恶意用户的真实用户嵌入进行聚类,形成的每个类被视作一组正常用户。此时,恶意用户可以从其所属的类中按照正态分布抽样一组虚拟用户嵌入,其均值和方差由恶意用户所属类中的用户嵌入计算而得。
IndDP:与Secret-Hiding FedRec系统不同,在DP-based FedRec系统中,每个用户都能获得包括用户嵌入(X)在内的所有三类参数的带噪版本。也就是说,在IndDP模式下,用户可以使用加噪后的全局用户嵌入完成虚拟用户抽样。这里使用与ColSH中相同的聚类算法对加噪后的全局用户嵌入进行聚类。
ColDP:可以发现,在IndDP模式下,使用加噪后的全局用户嵌入计算的聚类结果通常也带有噪声。因此,在这种攻击模式下,问题转化为如何使用恶意用户的真实用户嵌入和加噪后的全局用户嵌入获得一个相对可靠的用户聚类估计。其思想是首先对服务器下发的加噪后的全局用户嵌入进行聚类,并记录距离每个类质心最近的恶意用户集。然后,利用每个类内包含的恶意用户和原始加噪的类质心,重新计算出新的校正后的类质心,形成的每个类被视作一组正常用户。
图2 联邦推荐中常用的用户隐私保护方法
组件2:交互物品抽样
至此,我们已经获得一组抽样的虚拟用户集(即)以及对应的用户嵌入。下面继续为每个虚拟用户分配一组历史交互,即。正如前面所讨论,通用思路是找到每个虚拟用户的硬样本。现有研究通常依赖于推荐评分进行选择。具体而言,评分最高的部分物品被选为硬负样本,而最低的被选为硬正样本。这种方法在推荐模型接近最优时可能效果显著。然而,在训练的初期阶段,其效果可能并不理想。
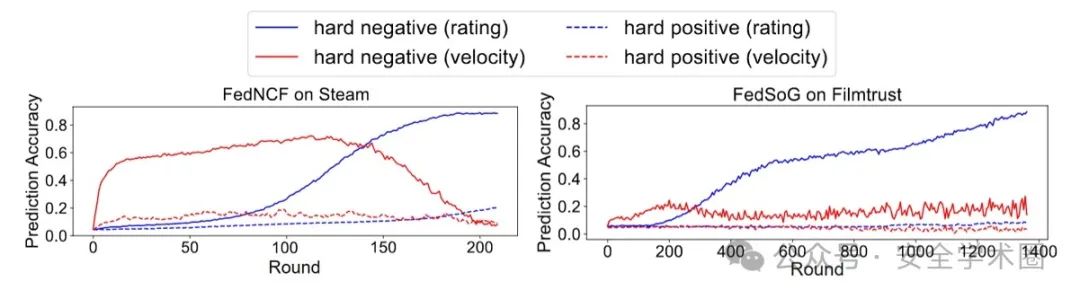
为验证这一假设,论文在两个现实世界中广泛使用的数据集Steam和Filmtrust上进行实证分析,并根据验证结果提出了相应的解决方案,见图3。具体来说,文中通过计算真实硬样本集与每一轮预测的硬样本集之间的差异来量化硬样本的预测准确率。所有用户的平均准确率作为最终的预测值。图3展示了训练过程中,仅根据推荐评分预测硬样本时的平均准确率变化(蓝色曲线)。从图中可以看出,两个模型对硬负样本的预测准确率在训练的最后阶段都能逐渐达到0.8以上,但在早期阶段却相当低,尽管算法和数据集的提高速度可能有所不同。由于推荐评分接近的硬正样本数量较多,其预测精度始终处于较低水平,但也呈现出与硬负样本相同的趋势。这一结果与之前的假设相吻合。
图3 不同硬采样方法下硬样本的预测准确率
为此,文中提出一种基于推荐评分变化速度的硬采样方法,即充分利用推荐评分在不同训练轮次间的变化速度。沿用相同的数据集和推荐模型,在图2展示了基于推荐分数变化速度的硬采样方法的预测准确率(红色曲线)。可以看到,与蓝色曲线相比,在训练的早期阶段,利用变化速度可以显著提高预测准确率,但随着训练的进行,这种优势逐渐减弱。这一现象是合理的,因为当训练接近收敛时,推荐评分逐渐稳定,变化速度趋近于0,此时无法通过变化速度有效识别硬正样本和硬负样本。
一种可行的办法是将两种采样方法(推荐评分及其变化速度)结合起来,各取长处以实现更准确的抽样。鉴于基于变化速度的预测在早期训练阶段有更好的表现,文中的思路是从训练开始时依赖变化速度,并在“适当的时机”切换到基于推荐评分的预测。具体而言,当预测准确率提高时,连续轮次之间将有更多的硬样本共享,也就是说,的大小随着训练轮次的增加而增大。然而,由于预测准确率在训练过程中是波动的,这种连续的增加不可能在每一轮都发生。因此,考虑一个包含M轮的滑动窗口,如果在连续轮次间,的交集逐渐减少的轮数高于某个阈值,则认为基于评分变化速度方法的预测性能已经到达峰值并开始下降,此时应将预测方法由基于变化速度切换为基于推荐评分,即抽样的交互物品由转为。
三. 防御机制GuardCQ
值得注意的是,非定向投毒攻击通用框架同样揭示了用户画像与物品之间的相互作用在保护联邦推荐系统中的关键作用。因此,文中进一步提出一种基于贡献量化的防御机制,该机制通过量化不同用户对物品-用户间正确交互作用的贡献来检测和识别恶意用户。文中将“正确交互作用”定义为与全局模型一致的评分行为,并选择在最有可能被恶意用户利用进行攻击的流行物品上量化贡献。由于不受欢迎的物品预测精度较低,因此不予考虑(如图3所示)。
下面使用ML-1M和Filmtrust数据集为例,展示了攻击条件下,正常用户和恶意用户在真实流行物品上的评分行为与全局模型的一致性程度。较高的一致性表明对正确交互作用有更大的贡献。如图4所示,蓝色框和红色框分别表示正常用户和恶意用户的行为。可以观察到,随着模型的训练,正常用户对流行物品的评分行为与全局模型越来越趋于一致,即其贡献度逐渐上升;而恶意用户呈现出相反的趋势,这一现象与直觉相一致。GuardCQ机制正是通过这种贡献差异实现了潜在恶意用户的识别和剔除。
图4 不同模型训练轮中正常用户与恶意用户的评分行为
四. 论文主要贡献:
首次构建针对FedRec系统非定向投毒攻击的通用框架。该框架揭示了用户画像(user profile)与物品(item)间的相互作用在决定攻击性能上发挥的关键作用,并由此刻画出实施攻击的两个关键组件:用户抽样与交互物品抽样。
提出一种非定向投毒攻击策略FRecAttack2,该策略在不同攻击模式下实现了多种细粒度用户抽样方法,以近似正常用户嵌入(user embeding)的分布。在此基础上,通过监测模型优化过程中物品评分及其变化速度的模式,快速识别可破坏这一相互作用的最佳攻击样本,从而实现交互物品抽样。
为增强FedRec对非定向投毒攻击的抵御能力,进一步提出一种名为GuardCQ的防御机制,该机制通过实时量化每个用户对正确相互作用的贡献程度,实现对恶意用户的动态剔除。进一步地,GuardCQ能够与现有的多数拜占庭鲁棒聚合方法结合使用,为FedRec系统提供更强大的保护。
五. 作者团队:
论文第一作者为北京交通大学信息安全团队的博士生郝玉蓉,通讯作者为团队王伟教授,作者还包括团队博士生吕晓婷和刘吉强教授等。北京交通大学信息安全团队建有“区块链研究中心”和“智能交通数据安全与隐私保护技术北京市重点实验室”等平台。团队主持了数据安全相关的国家自然科学基金联合基金重点项目、国家重点研发计划项目和课题等多个重大重点项目。其中由王伟教授主持的“基于区块链的Web3.0前沿技术”是首个Web3.0共性关键技术类国家重点研发计划项目。王伟教授还主持了数据安全相关的国家自然科学基金联合基金重点项目。团队联合编制相关的国际、国家和行业标准 23 项。团队以第一作者和第一单位获CCS 2023杰出论文奖,团队作为第一完成人获中国自动化学会科技进步一等奖1项。团队研发了强隐私保护的数据聚合平台、商品溯源平台和银行业务系统。研究成果在京东达达和中国铁道科学研究院等大型公司及金融和政府行业得到了应用。目前团队正在与优势单位合作,开展数据要素高效安全流通等方面的研究工作。
团队公众号如下:
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh