一. 文本对抗攻击
尽管自然语言处理(Natural Language Processing ,NLP)技术在文本分类、情感分析、机器翻译等任务上取得了显著进展,但文本对抗样本的出现为这一领域带来了新的挑战。经过攻击者精心设计的微小扰动,文本对抗样本能够使高准确率的模型出现预测错误,进而揭示了NLP模型的脆弱性。如图1所示,替换字符可以改变模型对句子情感倾向的判断。
图 1 文本对抗样本示例[1]
与常见的图像对抗样本相比,文本对抗样本的生成面临多重困难:一,文本是离散字符,对抗样本生成方法无法直接采纳适用于图像等连续空间中的优化算法;二,自然语言具有复杂性和多义性的特点,对抗样本不应破坏语义;三,微小的改动可能会破坏语言的语法结构,为了不影响正确理解,对抗样本需要保证语法通顺流畅。
尽管面临着上述阻碍,TEXTFOOLER在文本分类、文本蕴含两类任务上,在预训练BERT模型、卷积神经网络和循环神经网络上均实施了成功的黑盒攻击。实验表明TEXTFOOLER在攻击有效性、计算效率和语义语法完整性方面表现优异:
1、 攻击有效性:保持高攻击成功率和低扰动率,更能有效地使模型误判。
2、 计算效率:生成对抗文本的时间复杂度和文本长度呈线性关系。
3、 语义语法完整性:生成的对抗文本保留语义内容和语法正确性,确保文本能够被人类正确分类。
二. TEXTFOOLER
2.1
攻击流程
TEXTFOOLER的思路非常简单:首先识别对目标模型来说重要程度高的单词,然后用语义相似度最高、语法正确度最高的单词进行替换,直至模型预测发生变化。
图 2 TEXTFOOLER框架流程
具体地说,TEXTFOOLER通过两步实现攻击:
步骤一:词重要性排序。给定一个包含n个单词的句子X,在X中只有部分单词会影响模型F的预测,因此先筛选出对预测结果影响最大的关键词。由于黑盒场景无法获取模型F的梯度信息,TEXTFOOLER的评估机制根据删除单词后模型的预测变化进行打分。为衡量特定单词wi对预测结果F(X)=Y的影响,删除wi后得到模型对Y标签的预测分数FY(·),根据删除单词wi前后的模型预测变化计算重要性分数。遍历句子中的所有单词得到重要性分数顺序后,过滤掉“the”、“when”、 “none”等常见停用词,以避免后续出现语法被破坏的情况。
步骤二:词转换。对步骤一中的重要词wi进行词替换。根据余弦相似度,从同义词中选出语义最接近且词性与wi相同的词,构成候选词集合。用候选词集合中的词对wi进行替换得到对抗样本Xadv,利用Universal Sentence Encoder(USE)计算原句X与对抗样本Xadv之间的语义相似度,只有相似度超过设定的阈值ε才认为替换是有效的,有效候选词放入最终候选集中。若最终候选集中存在候选词能够改变目标模型的预测结果,则选择其中与原始单词语义相似度最高的作为最佳替换词;若没有则选择当前模型预测置信度最低时对应的词进行替换,并继续对原句X下一个单词的处理,直至模型预测结果发生改变。
图 3 TEXTFOOLER生成的对抗样本示例
2.2
攻击效果
为了使攻击效果的评估更加全面准确,实验中结合了自动化评估和人工评估策略。
自动化评估策略:攻击成功率(通过攻击前后模型准确率来衡量),语义相似度(通过Universal Sentence Encoder计算),迁移性(通过对抗样本在不同模型上的表现衡量)。
图 4自动化评估TEXTFOOLER在文本分类任务上的表现
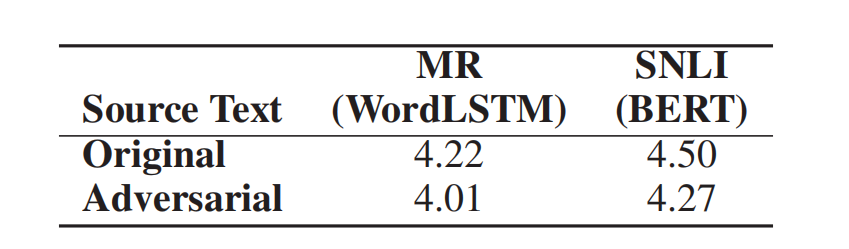
人工评估策略:随机选取100个对抗样本,与原始文本混合并打乱顺序,人工评估对抗样本的语法合理性、对抗样本与原始文本的语义相似度,并统计人工在原始文本和对抗样本上分类一致性的比率。
图 5 人工评估句子语法(分数范围1-5)
实验表明:在不到20%的词汇扰动率下,TEXTFOOLER攻击准确率基本达到90%以上,证明了攻击的有效性。另外,TEXTFOOLER生成的对抗文本在保证成功误导模型的同时,还能够维持较高的语义相似度和语法规范性,具有较高实用性。
三. 结语
随着语言模型的不断发展,文本对抗样本揭示了模型潜在的脆弱性和局限性,研究文本对抗样本的生成方法与机制有助于进一步提升模型的鲁棒性和泛化能力,改进语言模型在实际复杂场景中的表现并保障模型运营中的安全。
参考文献
[1] J. Gao, J. Lanchantin, M. L. Soffa, and Y. Qi, “Black-box generation of adversarial text sequences to evade deep learning classifiers,” in IEEE Security and Privacy Workshops (SPW). IEEE, 2018.
[2] Jin D, Jin Z, Zhou J T, et al. Is bert really robust? a strong baseline for natural language attack on text classification and entailment[C]//Proceedings of the AAAI conference on artificial intelligence. 2020, 34(05): 8018-8025.
内容编辑:创新研究院 杨鑫宜
责任编辑:创新研究院 舒展
本公众号原创文章仅代表作者观点,不代表绿盟科技立场。所有原创内容版权均属绿盟科技研究通讯。未经授权,严禁任何媒体以及微信公众号复制、转载、摘编或以其他方式使用,转载须注明来自绿盟科技研究通讯并附上本文链接。
关于我们
绿盟科技研究通讯由绿盟科技创新研究院负责运营,绿盟科技创新研究院是绿盟科技的前沿技术研究部门,包括星云实验室、天枢实验室和孵化中心。团队成员由来自清华、北大、哈工大、中科院、北邮等多所重点院校的博士和硕士组成。
绿盟科技创新研究院作为“中关村科技园区海淀园博士后工作站分站”的重要培养单位之一,与清华大学进行博士后联合培养,科研成果已涵盖各类国家课题项目、国家专利、国家标准、高水平学术论文、出版专业书籍等。
我们持续探索信息安全领域的前沿学术方向,从实践出发,结合公司资源和先进技术,实现概念级的原型系统,进而交付产品线孵化产品并创造巨大的经济价值。
长按上方二维码,即可关注我
如有侵权请联系:admin#unsafe.sh