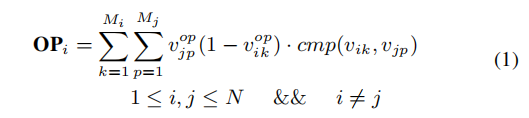
基本信息
原文名称:Rethinking Smart Contract Fuzzing:
Fuzzing With Invocation Ordering and Important Branch Revisiting
原文作者:Zhenguang Liu; Peng Qian; Jiaxu Yang;
原文链接:https://arxiv.org/pdf/2301.03943.pdf
发表期刊:IEEE Transactions on Information
Forensics and Security, 2023
开源代码:https://github.com/Messi-Q/IR-Fuzz
一、引言
作者针对当前智能合约模糊测试技术中存在的问题,提出了一种包含了调用序列和重要分支重新访问的全自动模糊测试技术的框架IR-Fuzz,包含了三个关键组件:
(1) 序列生成:通过数据流依赖分析计算每个函数的调用顺序优先级;
(2) 种子优化:采用基于分支距离的度量选择测试用例;
(3) 能量分配:采用分支搜索算法,制定对应的规则指导fuzz的能量调度。
二、研究动机
本文展示了一个真实世界的智能合约GuessNum(图1展示了一个简化的代码),这个合约在以太坊上实现了一个猜数字的赌博游戏,用户通过提交他们的猜测和参与费用来参与游戏。每次参与费用固定为50 finney,并且注入到奖池(prizePool)。函数constructor()旨在合约创建时运行一次,将合约所有者的资金注入到奖池中。想要猜测的玩家可以调用函数guess(),该函数将接收到的猜测数字与随机生成的幸运数字(luckyNum,11行)进行比较。如果猜测数字与luckyNum完全匹配,玩家将获得40倍的参与费用作为回报(13行),玩家可以通过调用函数getReward()来提取自己账户余额中的奖励。
漏洞:GuessNum合约中包含了经典的重入漏洞。图1中的18行的getReward()函数中调用了call.value向用户转移资金。然而,由于智能合约的默认设置,转账操作将自动触发接受合约的fallback函数。因此,攻击者可以在他的fallback函数中对getReward()进行恶意的二次调用,从而窃取额外的资金,由于getReward()等待第一次转账完成,攻击者的余额还未减少(即19行的用户余额减少操作在call.value之后,并且尚未执行)。因此,函数getReward()会错误地认为攻击者仍然有你足够的余额,并且再次向攻击者转账。
现有fuzzer的局限:
(1) 函数调用顺序。在该示例合约中,如果11行和13行的条件没有被满足,则不会触发17行的第二条件,从而不会触发18-20行的then分支;
(2) 自动生成能够满足1行的第二个条件的测试用例非常困难(msg.value == 50 finney);
(3) 可能包含漏洞的分支只占据程序的一小部分,例如,18-20行是易受攻击的代码,但当前的fuzzer倾向于平等的对待每个分支,可能会导致fuzz资源分配不足而无法发现漏洞。
图 1 Solidity编写的真实世界智能合约GuessNum
而针对上述的问题,作者设计了IR-Fuzz:
(1) IR-Fuzz利用函数间读写依赖关系生成特定的函数调用序列,同时进一步对生成的序列进行延长探索更多的合约状态。图1的合约中包括两个全局变量:userBalance和prizePool,同时出现在guess()和getReward()函数中。通过分析全局变量userBalance的读写依赖关系,IR-Fuzz识别得到getReward()依赖于函数guess(),因此guess()函数应该先于getReward()函数调用。
(2) IR-Fuzz使用了一个基于分支距离的模式来选择更加合适的测试用例。例如图1中13行的then分支,其距离就计算为|msg.value - 50|。
(3) IR-Fuzz增加了分支搜索算法对罕见分支(rare branches)和可能存在漏洞的分支(vulnerable branches)进行挑选,利用能量分配调度对这些更加重要的分支进行进一步测试。
三、概述
(1)序列生成(Sequence Generation)IR-Fuzz通过分析函数间数据流依赖分析,计算每个函数的顺序优先级,生成函数调用序列,同时使用了序列延长技术扩展序列,对更深层次的状态进行探索。
(2)种子进化(Seed Evolution)IR-Fuzz利用基于分支距离的测量算法选择和对测试用例进行迭代,使得测试用例更加靠近目标分支。
(3)能量分配(Energy Allocation)IR-Fuzz使用了一个分支搜索算法来分析探索过的分支并且挑选出重要的分支,同时使用一个能量调度来指导fuzz的方向朝着关键分支方向测试。
(4)漏洞分析和报告(Vulnerability Analysis and Report)IR-Fuzz分析生成的日志并参考了预定义的漏洞模式进行漏洞分析。
图 2 IR-Fuzz的完整流程图
1.序列生成(Sequence Generation)
真实世界智能合约通过全局变量存储当前的合约状态,不同的合约函数对全局变量会进行不同的读写操作。IR-Fuzz通过函数中针对全局变量的读写操作生成函数调用序列,对实行了写操作的函数赋予更高的顺序优先级,以探索更多的合约状态空间。
序列顺序:本文作者通过全局变量在函数之间的读写依赖关系构造函数调用序列。将智能合约的源代码转换为抽象语法树,从中提取可达性操作(例如分配和比较),再利用一个数据流分析器捕获函数之间针对全局变量的读写依赖关系。最终通过计算得到每个函数的顺序优先级(order priority,OP),根据函数的OP生成对应的函数调用序列。
形式化定义:将智能合约中的函数集合定义为F={F1,F2,……,FN},函数Fi中出现的全局变量定义为V={Vi1,Vi2,……,ViN},M为函数Fi中出现的所有全局变量的个数,Vik代表函数Fi中的第k个全局变量。特别的,每一个变量有一个独特的ID,定义为VikID。为了进一步标识函数中针对全局变量的操作,作者使用了Vikop=1代表函数Fi对变量Vik进行了读操作;Vikop=0代表函数Fi对变量Vik进行了写操作。
函数的OP计算规则如下:
规则1:读写依赖关系。当一个全局变量出现在两个不同的函数中时,对变量进行写操作的函数应当在对变量进行读操作的函数之前被调用。即如公式(1)所示,若某个函数对一全局变量进行写入操作,同时还有别的函数对这个全局变量进行了读取操作,则这个函数的顺序优先分数加一。若函数对更多的全局变量进行了写入的操作,则会获得更高的优先级,并且会在生成调用序列的前列。
其中cmp用以确定两个不同函数中出现的相同的变量:
序列延长:作者通过不同的测试用例来运行函数调用序列S,得到合约的多种状态,后再次调用和序列S,从这些不同的状态开始执行,即在S之后附加延长一个新的序列S。通过这样延长函数序列的方式增加能够探索到合约的状态空间。
规则2:序列配对选择。(1)当序列中所需的函数输入参数数量不少于2时,当且仅当两个序列之间至少有一个输入参数不同选择序列对。例如,给定三个序列S1: F1(x1) → F2(),S2: F1(x2) → F2(),和S3: F1(x2) → F2(),选择序列对P1(S1, S2)和P2(S1, S3)。相反,由于S2和S3具有相同的参数,因此不选择序列对P3(S2, S3)。(2)当所需的函数输入参数数量大于2时,我们选择序列对,当且仅当两个序列之间至少有两个输入参数不同。例如,给定三个序列S1: F1(x1, y1) → F2(z1),S2: F1(x1, y2) → F2(z1),和S3: F1(x2, y2) → F2(z2),我们选择序列对P1(S1, S3)和P2(S2, S3)。
2.种子进化(Seed Evolution)
IR-Fuzz使用自定义的种子进化范式优化迭代测试用例,如算法1所示。IR-Fuzz首先初始化一个空的test suite和一组测试用例(第1-2行),随后执行第一个循环(6-8行)进行种子选择,每当一个测试用例覆盖一个新的分支,就被添加到test suite中。接下来,循环迭代优化测试用例(9-15行),作者提出了一种基于分支距离的度量(branch distance-based measure)选择更接近满足新分支条件的测试用例。18-24行代码中循环进行种子变异,利用mutation()函数从test suite中选择测试用例进行突变。最后采用种子验证策略来确保突变后的测试用例的有效性(第21行),直到达到突变能量上限。最后,形成了包含高质量测试用例的新test suite。
种子选择:IR-Fuzz监控测试用例的执行过程同时记录每个测试用例遍历的分支,当一个测试用例覆盖了一个suite中没有用例到达过的分支时,这个测试用例被加入到suite中。同时,为了解决复杂分支更加严格的条件限制这一问题,IR-Fuzz提出了一种新的种子选择策略,作者采用了一种距离函数dist(T, br)计算某一测试用例与错过的分支之间的距离,如下所示。
种子变异:IR-Fuzz设计了两个变异原则:(1)通过使用位验证方法来检查突变的测试用例的有效性和完整性,该方法将给定种子的随机位设置为随机值,同时保持种子的其他位不变。IR-Fuzz保存能够检测到新的分支的测试用例,同时丢弃无效的测试用例。(2) IR-Fuzz通过将突变的用例与test suite中的测试用例进行比较来删除重复的测试用例。
同时,IR-Fuzz使用了启发式方法来分配测试用例的变异能量(对在一轮突变中没有发现新的分支的种子分配较低的能量)。IR-Fuzz根据模糊测试过程中生成的日志更新能量(算法1中23-24行),当达到突变能量上限的时候突变阶段停止。每个种子都被分配一个优先级分数用来衡量后续变异过程中检测新的分支的能力。
3.种子分配(Seed Allocation)
作者提出在程序中可能含有漏洞的代码分支仅占全部代码的一部分,因此提出在模糊测试过程中针对那些含有漏洞的分支进行更进一步的测试,设计了一种能量分配机制。具体来说,该机制包括两个模块:分支分析和能源调度。
分支分析:作者提出了一种分支搜索算法(算法2)来分析在测试过程中遍历的所有分支,关注于两类分支:稀有分支(rare)和漏洞分支(vulnerable)。将包含两个及以上嵌套的条件语句的分支定义为稀有分支,同时嵌套的条件语句数量定义为该分支的稀有因子R。作者设定了一个可能导致bug的漏洞语句集合T,如果某一分支包含了该集合中的语句,则将该分支认定为漏洞分支。
IR-Fuzz应用了抽象解释器A挑选出重要分支,通过A对测试过程中发现的分支进分析,循环检查其中是否包含了漏洞集合中的语句并且计算出每个分支中的稀有因子R,将所有R≧2的分支加入到Brare,最终A得到一个包含稀有分支的集合Brare和漏洞分支的集合Bvulnerable。
能量调度:作者设计了一个能量调度算法Ω管理fuzz过程中的能量分配和两条规则。
规则3:对稀有分支的能量分配。给定br1分支R1和br2分支R2在同一路径p,其中Ri是稀有因子且R1 < R2。为了便于具有较高稀有因子的稀有分支被更充分地测试,Ω将能量∇1*E分配给br1,∇2*E分配给br2,其中∇1<∇2。
规则4:对漏洞分支的能量分配。给定路径p1中的一个分支br1和路径p2中的一个分支br2,当R1 = R2和br1∈Bvulnerable时,Ω将α∗E能量分配给br1(α > 1),E能量分配给br2。系数α控制着对漏洞分支的偏好程度。
4.漏洞分析报告(Vulnerability Analysis and Report)
在这个阶段,IR-Fuzz重点在于漏洞生成和生成报告,发现智能合约中的漏洞以及为进一步人工确认生成更细节的漏洞报告。作者调研之前的工作并且定义了八种漏洞的特定类型:时间戳依赖、块序号依赖、危险代理、以太冻结、未检查的外部调用、重入漏洞、整数溢出和危险以太严格相等漏洞。作者实现了一个模式分析器处理以上提及的模式。
四、实验
RQ1:IR-Fuzz是否能够检测合约的漏洞?相较于SOTA的表现如何?
RQ2:IR-Fuzz是否能够比现有的方法达到更高的分支覆盖率?
RQ3:IR-Fuzz在智能合约模糊测试方面和生成测试用例的效率如何?
RQ4:IR-Fuzz中的不同组件对于其分支覆盖和漏洞检测准确率的贡献如何?
1.实验设置
实现:IR-Fuzz总共包含了9k行以上的C++代码,代码开源。作者基于sFuzz上实现IR-Fuzz。
Baselines:7种开源方法,如表1所示,作者选择了3种模糊测试工具:ConFuzzius,ILF,sFuzz;选择了4种静态分析类型:Mythril,Oyente,OOsiris,Securify。从分支覆盖、效果和效率三个方面与IR-Fuzz进行对比。实验环境为Intel Core i9 CPU 3.3GHz,GPU 2080Ti和64GB内存。每个实验重复10遍,汇总平均结果。
数据集:作者爬取Etherscan上经过过验证的合约,这些合约都是在真实世界被部署的合约。并且通过比较合约的二进制代码移除了5074份重复的合约,最终的数据集总共包含了12,515个有源代码的智能合约。将数据集部署在本地以太网络进行实验测试,对于智能合约的ground truth的标签通过模式匹配和人工核对结合的方式实现标定。
2.有效性(RQ1)
作者计算出每种方法都能够识别出的具有漏洞的智能合约的数量,并给出每种方法的准确性、误报率和漏报率。
IR-Fuzz与SOTA对比:每个方法的量化实验结果总结在表2。(1)与其他的方法比较,IR-Fuzz能够识别出更多的漏洞,特别的,IR-Fuzz能够达到更高的准确率(超过90%)。(2)IR-Fuzz在检测每种类型的漏洞方面优于最先进的方法。例如,对于以太冻结脆弱性(EF),IR-Fuzz比Securify和ConFuzzius提高了15.63%和16.14%的精度。(3)IR-Fuzz发现了一种新的智能合约漏洞,即危险的以太严格平等(SE)。
误报和漏报分析:为了进一步评估IR-Fuzz的有效性,作者检查了已确定的漏洞合同,表3显示了每种方法发现的漏洞合同的数量,以及每种方法的误报率和漏报率的数量。(1)从表2中可以观察到,现有的方法对八种类型的漏洞尚未获得较高的准确率。例如,对于未检查的外部调用漏洞(UC),Securify和sFuzz产生7个true positive,而连ConFuzzius和ILF分别获得8个和2个true positive,主要是由于传统的工具忽略了外部调用返回值的异常。(2)现有的方法有很高的误报率,可能是由于两个因素导致(i)多数方法倾向于使用一些简单但不精确的模式来检测漏洞(ii)工具的检测方法假设所有返回负值的算术运算都是易受攻击的,从而导致很高的误报。
3.分支覆盖(RQ2)
作者通过将数据集分为大型合约「多余3600个指令和小型合约(少于3600个指令)」,测算了test suite中的测试用例覆盖的分支数量。将结果可视化为图3,绘制了分支覆盖范围随时间变化的趋势。可以看出,IR-Fuzz始终优于其他fuzzer。定量上,IR-Fuzz在小型合约上的覆盖率达到90.10%,比sFuzz、ILF和ConFuzziuz分别高28.20%、20.10%和10.10%;在大型合约上,IR-Fuzz分别高出19.20%,14.00%和9.10%。同时,IR-Fuzz达到最大分支覆盖率的时间相较于其他的fuzzers更短。
图 3 不同fuzzer分支覆盖率(随时间变化)
4.效率(RQ3)
作者通过计算每个合约的平均执行时间来测量IR-Fuzz的开销,它在每个合约上平均花费21.30秒;同时通过计算随着时间的推移产生的测试用例数量来进一步衡量IR-Fuzz的效率,如图4所示。
图 4 可视化地比较在不同工具上的效率
5.消融实验(RQ4)
序列生成策略的研究:作者从IR-Fuzz中删除了序列生成策略,替换为随机序列构造方法,变体表示为IR-Fuzz-WSG。定量结果汇总见表4,IR-Fuzz的性能明显优于IR-FuzzWSG。
分支距离种子进化方法的研究:作者删除该方法,替换为随机测试用例生成,表示为IRFuzz-WDM,结果如表4所示,可以观察到IR-Fuzz-WDM的准确性和分支覆盖率平均比IR-Fuzz低2.03%和15.76%。
能量分配机制的研究:作者利用平均分配能量的策略代替了IR-Fuzz中提出的能量分配机制,表示为IR-Fuzz-WEA,结果见表4中,IR-Fuzz-WEA的准确率和分支覆盖率都比IR-Fuzz低4.87%和43.02%。
五、讨论
种子变异优化:IR-Fuzz使用AFL中的种子突变策略,存在产生重复和无效测试用例的问题,同时,任意突变测试输入的位可能会忽略输入中某些不应该突变的关键部分,降低了在严格条件下保护的分支的概率。因此,在后续的工作中,可以集中于使fuzzer不改变测试用例的这些关键部分,使测试触发深度和复杂的状态。
六、总结
本文提出了IR-Fuzz,一个全自动的模糊测试框架,具有顺序函数调用生成和关键分支重复访问的功能来检测智能合约的漏洞。具体来说,作者提出了一个序列生成策略,包括调用顺序和延长,以生成高质量的函数调用序列,强制fuzzer触发复杂和深层状态;设计了一个种子优化范式,利用基于分支距离的度量来迭代地将测试用例演变到目标分支,减轻了测试用例生成的随机性;开发了一个能量分配机制,灵活地引导模糊测试资源分配到罕见和易受攻击的分支,提高了整体模糊测试效率和分支覆盖率。实验结果表明,IR-Fuzz在很大程度上显著超越了现有技术的模糊测试方法。
—END—
如有侵权请联系:admin#unsafe.sh