原文标题:Automatically Inspecting Thousands of Static Bug Warnings with Large Language Model: How Far Are We?
原文作者:Chen Wen, Yuandao Cai, Bin Zhang, Jie Su, Zhiwu Xu, Dugang Liu, Shengchao Qin, Zhong Ming, Cong Tian
原文链接:https://dl.acm.org/doi/10.1145/3653718
发表会议:TKDD
笔记作者:张彬@安全学术圈
主编:黄诚@安全学术圈
1、背景介绍
LLM(大型语言模型)是在广泛的文本数据上训练的神经模型,包括自然语言和源代码,通过采用自我监督的学习目标。具体来说,LLM已经在巨大而多样的数据集上进行了训练,使它们能够在模拟人类语言技能方面表现出足够的能力。因此,它们在多个领域带来了显著的进步。在理解程序代码方面,LLM如OpenAI的ChatGpt表现出了非凡的效率,并越来越多地应用于程序分析领域。LLM的一个有利特征在于其对不同任务的适应性,这得益于快速的工程技术。这些技术包括设计有效的输入提示,以从LLM中引出所需的输出。受这一特性的启发,本文认为LLM的适应性为理解用自然语言表达的错误报告、分析代码行为以及评估代码行为与静态分析工具生成的错误描述之间的一致性提供了一种很有前途的替代方案。
本文为C/C++代码选择了三个具有代表性和知名度的静态分析器,包括Cppcheck、CSA和Infer。这些静态分析器与各种最先进的分析技术(如符号执行、分离逻辑和模式匹配)相集成,在从业者中很受欢迎,并在工业界和学术界得到广泛评估和使用。
Cppcheck是一种典型的基于模式匹配的技术,结合了轻量级的低数据分析。具体来说,Cppcheck使用存储在本地数据库中的报告扫描C/C++源代码以查找潜在的错误模式。尽管该工具是全面的(即,配备了多个错误检查器)和高度灵活的,但Cppcheck在大型代码库中可能会出现高误报。
CSA是基于典型的路径敏感符号执行技术,并建立在LLVM/Clang静态分析工具链上,然而,该工具链仅限于单个翻译单元(例如,单个文件)。换言之,对转换单元之外的函数的任何函数调用都是过近似的,从而导致高误报率。
Infer是一种典型的基于分离逻辑的技术。具体来说,Infer利用分离逻辑和bi-abduction双向推理来推理内存操作,以证明某些内存安全条件,并为分析程序中的每个函数创建程序状态摘要。与其他静态分析器一样,Infer也容易出现误报。
2、Motivation
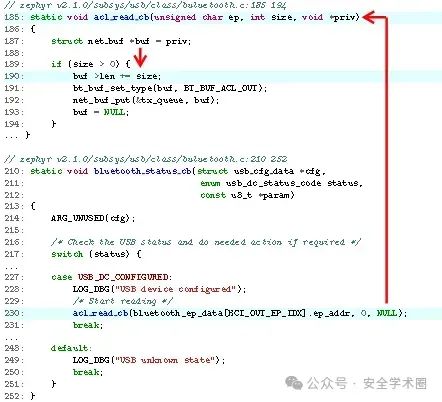
下图显示了Zephyr项目的代码片段,Zephyr是一个开源嵌入式实时系统。代码实现了一个回调函数,用于从USB端点读取数据。Cppcheck在acl_read_cb函数的第190行报告了一个空指针解引用错误,特别是与buf变量相关的错误。然而,这是一个假警报,因为buf变量在第187行被初始化为NULL,通过在第230行传递函数调用的参数,这也将第二个参数(即大小变量)设置为零。因此,第189行不能满足条件,并且从bluetooth_status_cb函数无法访问第190行。
3、本文方法
首先,Llm4sa进行预处理,统一和转换不同静态bug发现工具产生的bug报告。由于这些工具可以为特定项目生成大量警告,因此Llm4sa将整个报告拆分为单个警告,作为自动检查的基本单元。此外,由于不同工具生成的静态警告的不同格式导致报告的信息不一致,Llm4sa将这些静态警告转换为统一和全面的格式,从而对错误类型、描述、错误位置/跟踪和其他相关数据进行编码。这种转换集成了有助于LLM和开发人员双方理解的关键信息。
其次,Llm4sa使用程序依赖分析来创建一个代码数据库,该数据库通过分析审查中的整个项目源代码来存储与bug报告相关的代码片段。具体来说,提取必要的代码片段可以减轻LLM的令牌限制。通过利用格式化错误报告中的信息(例如,错误跟踪/位置),Llm4sa进行静态程序依赖分析,以识别与错误相关的相关函数体。此外,Llm4sa在代码片段中标识基本的调用上下文,例如调用者和被调用者。因此,Llm4sa中的代码段提取算法力求生成简洁而全面的代码段,其中包含LLM检查bug所需的足够信息。
第三,在获得代码片段之后,Llm4sa有效地构造提示词,这些提示词有助于查询LLM,以检查静态警告。具体来说,提示词描述了通过自然语言描述确认bug警告是否代表真正的bug的任务。通过将格式化的bug警告和相应的代码片段放在一起,并利用提示词工程技术,指导LLM提供合理的解释并得出精确的结论。文章使用提示词工程技术(例如,Chain-of-Thought(CoT)和few-shot)来提高LLM的结论的准确性和一致性。
最后,Llm4sa进行后处理,包括通过考虑一致答案的比例等因素来确定LLM回答的置信水平。具体而言,后处理旨在缓解LLM产生的不可靠和不一致的响应问题。基于置信度,Llm4sa能够将静态警告分为以下三类之一:false alarm、real Bug或unknown。
4、评估
4.1 实验设置
静态分析工具。本文选择了三种最先进的静态分析工具,包括Cppcheck、CSA和Infer。
Bug的类型。本文的评估检查了六类具有代表性的bug,包括空指针解引用(NPD)、未初始化变量(UVA)、释放后使用(UAF)、除零(DBZ)、内存泄漏(ML)和缓冲区溢出(BOF)。在呈现评估结果时,文章使用缩写来表示它们。
基准程序。为了了解Llm4sa在自动检查错误警告方面的能力,文章在基准程序和真实世界的软件上对其进行了评估。文章首先通过利用Juliet测试集中的一组基准程序来评估Llm4sa,这些程序包含了各种各样的错误,并且可以获得ground trueth。然后,文章使用3个嵌入式实时操作系统和11个维护良好的开源C/C++项目来评估Llm4sa在真实世界软件中的错误警告检查能力。
大语言模型。与LLM的所有交互,例如向LLM发送请求或从LLM接收响应,都是通过API执行的。文章的工具的LLama-2版本,称为Llm4saL, 利用了Llama-2-70b模型,该模型是目前Llama-2系列中可用的最大参数模型。同样,文章工具的ChatGPT版本采用了gpt-3.5-turbo-16k-0613型号,它支持最长的输入,并确保在评估过程中不会超过令牌限制。为了进行比较,文章还包括两个版本的Llm4sa,其中一个版本采用了few-shot提示词工程技术(称为Llm4saF),另一个使用零样本提示词(称为Llm4saZ)。
4.2 Llm4sa在Juliet Test测试集上的有效性
文章使用Cppcheck、CSA和Infer在文章选定的Juliet Test测试集上生成了总共6904个错误报告。Llm4sa自动逐个处理每个错误警告,并将错误警告分类为real bug、false alarm或unknown。Llm4sa正确地识别出其中的5,492个是真正的错误还是错误的警报。这相当于79.5%的准确率,超过了静态分析工具本身的精度。Llm4sa还证明了它在准确识别几乎所有real bug方面的有效性,从而产生了很高的召回率。虽然这个结果令人鼓舞,但并不意味着Llm4sa可以完全取代人工检查错误警告。详细的数据分析表明Llm4sa对某些类型的bug,特别是NPD、UAF和DBZ,具有较高的准确率和召回率。然而,它在ML和BOF上的表现相对较差,因为在这些情况下通常需要分析较长的跟踪路径或循环。例如,在Cppcheck生成的静态警告上,Llm4sa对NPD的准确率达到了94.05%,而ML的准确率为75%。这也出现在CSA生成的静态警告上。
利用开源大型语言模型Llama-2运行Llm4sa也得到了类似的结果。Llm4sa可以正确识别4847个bug警告,无论是真实的bug还是虚假的bug,准确率达到70.2%。结果表明,Llm4sa可以很容易地推广到其他流行的开源LLM,即使这个结果(70.2%)低于Llm4sa的79.5%的准确率。在检查Cppcheck提供的警告时,Llama-2-70b取得了很高的准确率和召回率(超过90%),略高于ChatGPT-3.5的性能。
相比之下,在评估来自Infer和CSA的警告时,Llama-2-70b的性能较低。期望通过开源LLM的改进和提示词的优化,可以提高实验的结果。
4.3 Llm4sa在真实程序上的有效性
文章使用Cppcheck、CSA和Infer在3个开源嵌入式操作系统和11个应用程序生成了总共749个错误报告,并通过手工检查确定了其中只有13个是真正的错误。
文章使用Llm4sa来过滤静态分析器产生的错误警告。如果Llm4sa将错误警告识别为假警报,文章将它们从报告的错误中排除。否则,它们将被包含在报告的错误中,以供进一步的人工检查。Cppcheck在这3个操作系统中总共报告了576个错误警告。Llm4sa能够推断出这些警告中有371个是假警报,只剩下205个可能是真正的错误。这大大减少了手动检查剩余警告的需要,从而最大限度地减少了人力成本。重要的是,应该注意的是,自动检查过程不会遗漏任何真正的错误,从而导致Cppcheck和Infer产生的那些警告的召回率达到100%。在11个应用程序上,Cppcheck、CSA和Infer都报告了大量警告,其中Infer报告的警告最多,为804个。然而,只有1.74%(即14个警告)的报告是真正的bug。Llm4sa能够显著减少需要人工检查的警告次数。平均而言,Llm4sa将警告数量减少了38.28%,而Llm4sa将错误警告数量减少了53.73%。值得注意的是,对于Cppcheck生成的警告,Llm4sa过滤掉了64.14%的警告。Llm4sa在三个静态分析工具中实现了超过90%的高召回率。
然而,这一结果虽然令人鼓舞,但并不一定意味着Llm4sa是有效的。遗漏真正bug的成本可能会超过人工检查bug警告的成本,特别是当这些真正的bug导致严重问题时。总之,Llm4sa在检查实际应用程序中的各种功能和复杂程度的静态警告方面始终显示出实用性。
4.4 提示词工程带来的提升
Llm4saF使用了少量提示,而Llm4saZ使用了零提示。Llm4saF和Llm4saZ在嵌入式操作系统的错误警告中都实现了100%的召回率。此外,Llm4sa显着提高了Llm4sa在所有三个静态分析器中的精度。在11个实际应用程序中,Llm4saF在精度和召回率方面也比Llm4saZ有了显著的改进。Llm4saZ将Cppcheck工具生成的报告的真阳性率从1.93%提高到3.76%。相比之下,Llm4saF通过六个不同的少量提示增强了所有三种静态分析工具的分析精度。此外,Llm4saF显著减少了需要人工检查的警告次数。Llm4saZ将警告数量平均减少了38.28%,Llm4saF将错误警告数量减少了53.73%。值得注意的是,Llm4saZ过滤掉了Cppcheck生成的53.21%的警告,而Llm4saF过滤掉了64.14%。
5、Case Study
文章将选择3个有趣的案例来展示Llm4sa在检查错误警告方面的有效性。所有这些情况都是由静态分析工具报告为错误的未初始化值错误,但原因各不相同。
对互斥状态不敏感。下图是sed应用程序(一个非交互式命令行文本编辑器)的代码片段。代码实现了从stream中获取一行的函数。两个静态分析工具Infer和CSA在ck_getline函数的第273行报告未初始化的变量访问错误警报。它们犯这个错误是因为他们假设第267行和第270行的两个互斥锁条件都是假的。然而,LLM可以正确地确定变量结果只有在stram没有错误时才被赋值,否则保持未初始化。这是可能的,因为LLM可以在互斥条件下分析代码上下文。这表明LLM有很强的语境总结、分析和推理能力。
路径条件分析不精确。下图显示了apr项目的代码片段,它创建并维护软件库。该代码实现了一个函数,用于从输入中查找所需字符串的长度,然后将参数字符串复制到结果空间中。数组saved_length在第126行没有初始化,这导致apr_pstrcat函数的第158行出现未初始化的变量访问错误。这个假警报由Infer、CSA和其他主流静态分析程序报告,因为它们假设第136行的条件为假。然而,这个假设是不正确的,因为第136 ~ 138行和156 ~ 157行的条件语句是相同的,除了赋值的变量。这意味着如果第158行可以访问,那么初始化数组saved_length的第139行也可以访问。主流静态分析工具只基于不精确上下文中程序的控制值来构造反例,LLM不同,LLM可以利用代码上下文、第129行和第151行中的注释以及关于函数(如va_arg)语义的领域知识。这使得LLM可以将函数apr_pstrcat分为“Pass One”和“Pass Two”两个阶段,并分别进行分析。因此,它可以验证数组saved_length在使用之前的“Pass one”阶段是否已被正确初始化。
难以处理复杂的代码。bash是一种流行的Unix shell和命令行界面(CLI)程序。函数glob_vector在第748行报告了一个未初始化的变量访问错误警报。然而,这是不正确的,因为变量isdir是在738行初始化的,根据732和746行的代码,它总是在748行之前执行。函数glob_vector非常长且复杂,有360多行代码、大量条件语句和按位操作。因此,LLM在理解和推理相关代码时面临困难,因为零概率提示查询将超过3800个令牌。此外,复杂的程序控制低阻碍了LLM理解代码的关键方面,从而阻碍了他们产生精确检查结果的能力。
作者团队介绍
论文第一作者为
西安电子科技大学广州研究院文成副教授,目前主要从事高可信软件工程技术、人工智能使能软件开发与验证、可信软件的基础理论与方法等方面的研究,坚持理论研究与产业应用并重,目前已经在包括ICSE 2024,ICSE 2022,ICSE 2020,IEEE Transactions on Reliability等顶级国际会议和期刊上发表十余篇论文;作为项目负责人承担国家自然科学基金青年基金项目1项、中国博士后科学基金面上项目1项,以及华为公司企业产学研合作课题1项。个人独立研发的自动化测试工具集已在Linux系统主流的开源应用程序中发现上百个真实缺陷(包括73 CVEs),主导研发的并发程序分析平台已在华为公司多个产品线得到实际部署和使用。通讯作者为
秦胜潮教授和苏杰助理教授,作者团队还包括许智武副教授等人。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh