2024-5-24 16:27:28 Author: hackernoon.com(查看原文) 阅读量:1 收藏
Deploying data science and machine learning applications often demands powerful computational resources. In this guide, You will learn about the process of setting up GPU-enabled virtual servers on a Virtual Private Cloud (VPC) using Cloud services.
By leveraging RAPIDS, an open-source suite of data science libraries developed by NVIDIA, you can harness the power of GPUs to accelerate your workflows. RAPIDS utilizes NVIDIA GPUs to provide high-performance data processing and machine learning capabilities, significantly reducing computation times. This post provides a step-by-step tutorial, from configuring your virtual servers to deploying RAPIDS, ensuring you have the necessary tools and knowledge to optimize your data processing tasks efficiently in a cloud environment.
The GPU-enabled family of profiles provides on-demand, cost-effective access to NVIDIA GPUs. GPUs help to accelerate the processing time required for compute-intensive workloads, such as artificial intelligence (AI), machine learning, inferencing and more. To use the GPUs, you need the appropriate toolchain — such as CUDA (an acronym for Compute Unified Device Architecture) — ready.
Let’s start with a simple question.
What is a GPU and how is it different from CPU?
Graphics processing units (GPUs) are becoming more prevalent as accelerated computing is rapidly changing the modern enterprise. They support new applications that are resource-demanding and provide new capabilities to gain valuable insights from customer data.
Let’s quickly go over why you could use GPUs in the first place. By operating in a cloud environment, GPUs work in conjunction with a server’s CPU to accelerate application and processing performance. The CPU offloads compute-intensive portions of the application to the GPU, which processes large blocks of data at one time (rather than sequentially) to boost overall performance in a server environment.
The following video covers the basics about GPUs, including the differences between a GPU and CPU, the top GPU applications (including industry examples) and why it’s beneficial to use GPUs on cloud infrastructure:

What is RAPIDS?
The RAPIDS suite of open-source software libraries and APIs give you the ability to execute end-to-end data science and analytics pipelines entirely on GPUs. RAPIDS utilizes NVIDIA CUDA primitives for low-level compute optimization and exposes GPU parallelism and high-bandwidth memory speed through user-friendly Python interfaces.
Here are the features of RAPIDS as described on the NVIDIA developer website:
- Hassle-free integration: Accelerate your Python data-science toolchain with minimal code changes and no new tools to learn.
- Top model accuracy: Increase machine-learning model accuracy by iterating on models faster and deploying them more frequently.
- Reduced training time: Drastically improve your productivity with near-interactive data science.
- Open source: Customizable, extensible, interoperable — the open-source software is supported by NVIDIA and built on Apache Arrow.
How to provision a GPU-enabled VSI
You will provision a virtual private cloud (VPC), a subnet, a security group with inbound and outbound rules and a virtual service instance (VSI) with a GPU-enabled profile using Terraform scripts with IBM Cloud Schematics. The RAPIDS, along with Docker, are configured via the VSI’s userdata field.
VPC uses cloud-init technology to configure virtual server instances. The User Data field on the new virtual server for VPC page allows users to put in custom configuration options by using cloud-init. Cloud-init supports several formats for configuration data, including yaml in a cloud-config file.
To understand more about Terraform and IBM Schematics, check this blog post: “ Provision Multiple Instances in a VPC Using Schematics.” In short, you can run any Terraform script just by simply pointing to the Git repository with the scripts.
Note: You will need an IBM Cloud account with permissions to provision VPC resources. Check the getting started with VPC documentation.
-
Navigate to Schematics Workspaces on IBM Cloud and click on Create workspace.
-
Under the Specify Template section, provide https://github.com/IBM-Cloud/vpc-tutorials/tree/master/vpc-gpu-vsi under GitHub or GitLab repository URL.
-
Select terraform_v0.14 as the Terraform version and click Next.
-
Provide the workspace name —
vpc-gpu-rapids- and choose a resource group and location. -
Click Next and then click Create.
-
You should see the Terraform variables section. Fill in the variables as per your requirement by clicking the action menu next to each of the variables:

7. Scroll to the top of the page to Generate (terraform plan) and Apply (terraform apply) the changes.
8. Click Apply plan and check the progress under the Log. (Generate plan is optional.)
In the output of the log, you should see the IP_ADDRESS assigned to the VSI. Save the address for future reference.
Test the setup
- Open a terminal. To test the setup, you need to SSH into the VSI with the below command:
ssh -i ~/.ssh/<SSH_PRIVATE_KEY> root@<IP_ADDRESS>
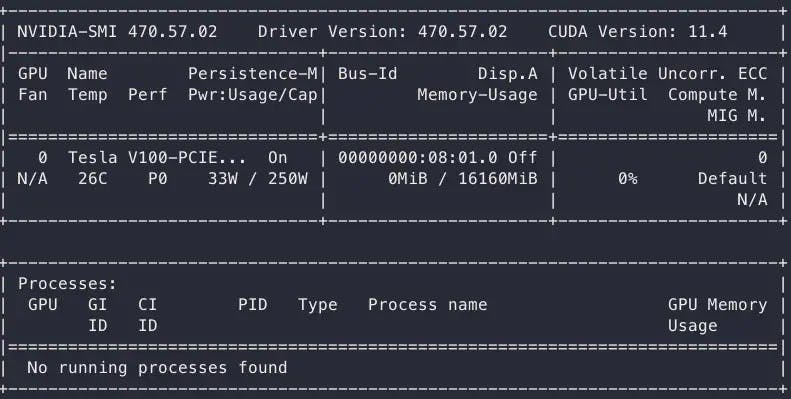
- A working setup can be tested by running a base CUDA container:
sudo docker run — rm — gpus all nvidia/cuda:11.0-base nvidia-smi
The output should look similar to this:

- To check the NVIDIA driver version, run the below command:
cat /proc/driver/nvidia/version
Output:
NVRM version: NVIDIA UNIX x86_64 Kernel Module 470.57.02 Tue Jul 13 16:14:05 UTC 2021
GCC version: gcc version 9.3.0 (Ubuntu 9.3.0–17ubuntu1~20.04)
If you don’t see the expected output, check the troubleshooting section of the post.
How to use RAPIDS
The RAPIDS notebooks are one of the ways to explore the capabilities. These Jupyter notebooks provide examples of how to use RAPIDS. These notebooks are designed to be self-contained with the runtime version of the RAPIDS Docker Container.
- Run the below commands to pull a Docker image and run a container to explore RAPIDS:
docker pull rapidsai/rapidsai:cuda11.0-runtime-ubuntu20.04
docker run — gpus all — rm -it -p 8888:8888 -p 8787:8787 -p 8786:8786 rapidsai/rapidsai:cuda11.0-runtime-ubuntu20.04
2. Launch a browser and enter your <IP_ADDRESS>:8888.
3. You should see the Jupyter notebook:

4. On the left pane, click on notebooks > cuml > tools and then launch the notebook. This notebook provides a simple and unified means of benchmarking single GPU cuML algorithms against their skLearn counterparts with the cuml.benchmark package in RAPIDS cuML.
5. As shown in the image above, click on the icon to launch the GPU dashboards. These dashboards provide a real-time visualization of NVIDIA GPU metrics in interactive Jupyter environments.
6. Click on GPU Resources and Machine Resources to launch the respective dashboards.
7. Run each code cell in the Jupyter notebook until you see the Nearest Neighbors — Brute Force cell.
8. Run the cell and check the metrics on the GPU resources and Machine Resources dashboard to understand the GPU utilization metrics and CPU metrics, respectively:

Below the cell, you can check the CPU vs. GPU benchmark metrics.
Troubleshooting
To check the cloud-init logs, run the following command:
cat /var/log/cloud-init-output.log
If the install is configured successfully, you should see a message similar to this:
_Cloud-init v. 21.2-3-g899bfaa9-0ubuntu2~20.04.1 running 'modules:final'_ _at Thu, 23 Sep 2021 08:51:11 +0000. Up 36.08 seconds._
_Cloud-init v. 21.2-3-g899bfaa9-0ubuntu2~20.04.1 finished at Thu, 23 Sep 2021 08:59:30 +0000. Datasource DataSourceNoCloud [seed=/dev/vdb][dsmode=net]. Up 534.16 seconds_
If you have any queries, feel free to reach out to me on Twitter or on LinkedIn.
如有侵权请联系:admin#unsafe.sh