
About two years ago I came across a .DS_Store file and wanted to extract its information (e.g. file names). After researching the file format and its security implications, as well as writing a parser for it, I would like to share my (limited) knowledge and the parser in Go / Python with the world.
You might want to continue reading if you are interested in how the file works and how it helped to expose several .sql / .db / .swp / .tgz files on websites from the Alexa Top 1M.
Let us begin with a small introduction to this blogpost and how I got to look at a file format from Apple. If you want to directly jump into the technical stuff, then skip to the next section.
While conducting reasearch focused on sensitive files on webservers about two years ago, I came across a file called .DS_Store. Back then I wrote and used a tool in Go to scan the Alexa Top 1M for different security issues, but there were no parsers in that language for the .DS_Store file format. I found one in Perl and a couple in Python, but none of them worked properly or could reliably parse the set of files that I obtained. Furthermore, I wanted to call a class/function that extracts the interesting information directly from Go without having to use external programs.
Therefore, I thought that re-implementing a parser for this file format in Go would be a nice excercise and learning experience, because I was still quite new to that language. The resulting code ended up on GitHub: Gehaxelt - Go DS_Store (Do not look at this if you know how to write Go ;) ). Unfortunately, I didn't comment the code much during development, but it eventually worked™ :)
At the 34C3 conference in Leipzig last year, a colleague and me decided to catch up with the research of this file format again. We finished it by now and I felt like I should share my knowledge with the rest of the world. Being unable to fully understand the code that I had written two years ago and therefore explain the file format, I started to dig into the details again and decided to re-implement the parser in Python!
I am still lacking some tiny parts of the specification/details that I managed to know some years ago, but the new parser should have the same functionality and I will try to give an introduction to the file format.
Before we start with the parsing of a .DS_Store file, let me tell you a bit about it. You might have received the (hidden) file on an USB stick from a colleague with MacOs or seen it somewhere else. Apple's operating system creates this file in apparently all directories to store meta information about its contents. In fact, it contains the names of all files (and also directories) in that folder. The equivalent on Microsoft Windows might be considered the desktop.ini or Thumbs.db.
Due to the fact that .DS_Store is prefixed with a dot, it is hidden from MacOs' Finder, so Mac-users might not be aware of its existence. Furthermore, the file format is proprietary and not much documentation about it is available online.
I am not the first to write a parser for this kind of file, so I do not want to claim this, but writing a parser for it was a good learning experience. The following resources helped me to learn and understand its format:
- https://wiki.mozilla.org/DS_Store_File_Format
- http://search.cpan.org/~wiml/Mac-Finder-DSStore/DSStoreFormat.pod
- https://digi.ninja/projects/fdb.php
I recommend reading all three of them to get a rough understanding of the file before continuing!
Anyway, let's start: I will use an example .DS_Store file to explain its structure. The parsers use a similar methodology to process the file.
The file is in big-endian format and begins with a header of 36 bytes:

The first 4-byte integer is always 0x01 and apparently used as an alignment, and that's why other references define the header to be 32 bytes after that. Anyway, the four blue bytes are the magic bytes (0x42756431).
The two red blocks are a 4-byte integer (0x1000) defining the position (offset) in the file of a root block that contains information about other pieces that we will parse later. Both offset values have to have the same value or the file should be considered invalid. In between is the green 4-byte integer (0x800) indicating the size of the before mentioned root block.
The remaining grey 16 bytes are not reversed yet and considered unknown data, so the parser can simply skip it.
Root block
Now that the basic information about the root block is in our hands, we can focus on its contents between 0x1004 and 0x1804. Note that we use the previously obtained position 0x1000 with an additional block-alignment of 0x04.
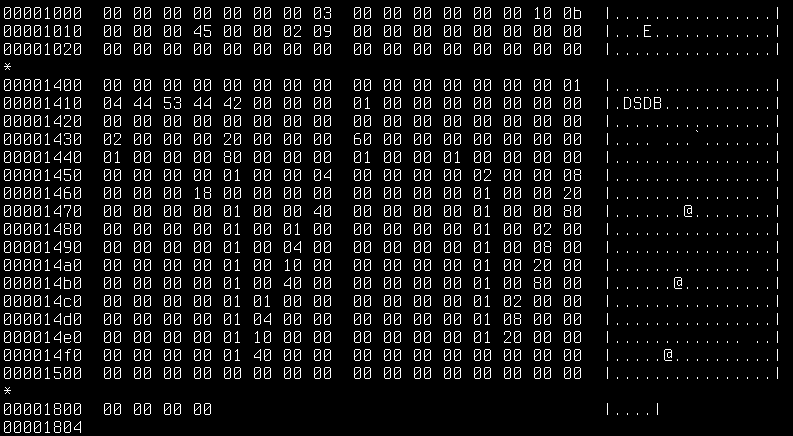
The information about the file names is stored in a tree-like structure where the root block contains important metadata about the tree and its other blocks. In general, the metadata can be split in three different sections:
- Offsets
- Tables of content
- Free list
Offsets
The offsets section contains information about the offsets of the tree's (leaf) blocks in the file. Those blocks store the actual information like file names etc. and the offsets are needed to traverse the tree.

The blue integer (0x03) tells us how many offsets we need to read after we skipped another four grey bytes that appear to always be zero. The following twelve green bytes are the three 4-bytes integers that should be added to an offsets list:
0x0000100B0x000000450x00000209
The order is important, because we will later access the values by their index in the list. Those offsets are the tree's block positions in the file. The rest of the section is padded with zeroes (red bytes) and the padding is aligned to go up to the next multiple of 256 entries (1024 bytes). In our case the padding goes up to 0x140c, because it equals 0x1000 + 3*4 bytes for the three integers (skipped/count/skipped) + 3*4 bytes for the three offsets + (256 entries - 3 entries)*4 bytes of padding.
Therefore, the next section will start at 0x140c.
Tables of content
After the offsets, the tables of content section follows. It usually contains at least one table named DSDB with the value 0x01. This particular table references the first block's id that we will traverse.

The red bytes are the padding from the offsets section and the TOC starts at 0x140c with four blue bytes representing the count of TOCs to parse. In our case that's only one (0x01).
It is followed by a single green byte indicating the TOC name's length which is 0x04. The TOC's name can be retrieved by the yellow marked bytes as an ASCII string. After the name, the purple 4-bytes integer is the TOC's value.
It is recommended to store the TOC in a dictionary, so that we can query it later:
- ['DSDB'] =
0x01
Free list
The last section is the free list, where unused or free blocks of the tree can be saved. In practice, I haven't used any values of that list to retrieve the file names, but it might be useful somewhen else.

It consists of n=0..31 buckets with the dictionary's key being 2^n.
In our example the free list starts at 0x1419. For each bucket a blue 4-byte integer is read. This integer then represents amount of offsets that we need to read.
From the hexdump above we see that the first five buckets from 0x1419 to 0x142d have zero elements. The sixth bucket after 0x142d has a value of 0x02 and therefore two elements 0x00000020 and 0x00000060.
After the complete iteration of the loop, the resulting free list should look similar to this:
{
1: [],
2: [],
4: [],
8: [],
16: [],
32: [32, 96],
64: [],
128: [128],
256: [256],
512: [],
1024: [1024],
2048: [2048, 6144],
4096: [],
8192: [8192],
16384: [16384],
32768: [32768],
65536: [65536],
131072: [131072],
262144: [262144],
524288: [524288],
1048576: [1048576],
2097152: [2097152],
4194304: [4194304],
8388608: [8388608],
16777216: [16777216],
33554432: [33554432],
67108864: [67108864],
134217728: [134217728],
268435456: [268435456],
536870912: [536870912],
1073741824: [1073741824],
2147483648: []
}
After parsing all three sections, we are done with the root block and can continue with the tree.
Tree
As I said earlier, the information is arranged in a tree-like structure. This tree needs to be traversed to obtain the file names or other information stored in the .DS_Store file.
Block IDs and offsets
I explained that the TOC contains the block id and in particular, the DSDB TOC references the first block by its ID that we will traverse. In our example the ID was 0x01.
We use the ID as the index to our previously computed offsets list to obtain an address: offsets[0x01] => 0x00000045
However, we cannot simply use the data at the location of 0x00000045, because the real offset and size of the block is encoded within this value:
2^k, with k being the five least-significant bits, is the block's size. It shouldn't be lower than 32 bytes.- it becomes the block's offset when the five bits are set to zero.
With our example address 0x00000045 and some bit operation magic, we get the following results:
- offset:
int(0x00000045) >> 0x5 << 0x5=0x40 - size:
1 << (int(0x00000045) & 0x1f)=0x20
Our example block with ID 0x01 will therefore start at 0x40+0x4 = 0x44 and be 0x20 bytes long.
Traversing the tree
To get the file names, we need to traverse the tree from its root block. As previously described, it is referenced by the block ID in the DSDB TOC and starts at 0x44.

This block contains exactly 5 integers of which the red one is the most interesting one, because it contains the block-ID of the first block with actual data. The other integers are:
- green: Levels of internal blocks (
0x00) - yellow: Records in the tree (
0x06) - blue: Blocks in the tree (
0x01) - brown: Always the same value (
0x1000)
Using the parsed block-ID 0x02 we can traverse the tree using recursion and extract the file names.
The data block's address is offsets[0x02] => 0x00000209 that becomes:
- offset:
int(0x00000209) >> 0x5 << 0x5=0x200 - size:
1 << (int(0x00000209) & 0x1f)=0x200
Knowing that the data block will start at 0x204 in the file, we continue with the following hexdump:

A block starts with two important integers:
- red: Block mode (
0x00) - green: Record count (
0x06)
If the mode is 0x00 then it is immediately followed by count records.
Otherwise, count pairs of next-block-ID|record follow, where the traverse function can be called recursilvely with the next-block-ID.
However, our example block is in mode 0x00 and therefore only 0x06 records need to be parsed.
A Record
Let's look at how the records inside a block look like.
A record begins with the length (blue 4-bytes integer) of the following UTF-16 file name of 2*length bytes (yellow 4-bytes integer).
After the file name a brown 4-bytes integer structure-ID (that I'm not sure how it's used) and a red 4-byte string structure-type. Depending on the structure type, a different amount of bytes needs to be skipped before reaching the end of the current block. An exhaustive list of structure types can be found here.
Once the parser finishes, a list of six file names should be the result:
- favicon.ico
- flag
- static
- templates
- vulnerable.py
- vulnerable.wsgi
Code
I am going to share the code that I have written over the years, but please do not expect bug-free, perfect code. As I said in the beginning, I am not the first to try to write a parser; the code is based on the work of others and might not be feature-complete. Bugfixes and PRs are always welcome!
If you are brave enough to look at it (or even use it!) then here are the links:
If you just want to try and parse a .DS_Store to see its contents, then you can also use the webservice that I am providing here:
Known Issues
While developing the code and writing the blogpost, I discovered some issues in the implementation and parsing logic, which I would like to discuss briefly. Maybe you will find a fix?
Root block offset
I came across at least one .DS_Store file, where the root block's offset from the initial header parsing was off by 4 bytes. This resulted in a incorrectly parsed offsets list as well as TOC. However, this seemed to be a rare occurence and I am not sure, how or why it occured.
Incorrect file name length
Another issue that I encountered was that the file name length inside a record had a wrong value. For example, it appeared as 0x0a (10 * 2 bytes), but the UTF-16 file name was actually > 20 bytes long. Often, this resulted in an unmatched structure type and an error. Setting the correct length with an hexeditor usually fixed the issue, but I am unsure how that obviously wrong length made it there.
Nonetheless, I have implemented a brute-force like approach to resolve this issue: Re-reading the next two bytes of the file name until a known structure-ID appears. This mostly fixed the issue, but it does not feel like it's the best approach.
Until now I only discussed the structure and contents of .DS_Store files, but this is a security-related blog, and I promised to answer the above question: YES, this file has some security implications if it's being uploaded to webservers!
Regarding to me, the juicy parts of the .DS_Store file are the file names that it contains. MacOs creates a .DS_Store file in almost all folders and you won't even notice it, because it is prepended with a dot and Finder won't show dot-files per default. Each file in a directory has an entry in the directorie's .DS_Store file.
Information disclosure (of sensitive files)
With the Internetwache.org project that I'm part of, we scanned the Alexa Top 1M domains for this file in their document root. It turns out that sensitive files are exposed and potentially accesible by the existence of that file. We discovered file names that indicated the existence of full document root backups, databases, configuration files, swap/temporary files or even private keys!
You can find a detailed blogpost about the methodology and the results on the internetwache.org's english blog.
How to check and protect yourself?
An important thing that needs to be clarified is that the file names stored in a .DS_Store file only represent the contents of a directory on a local MacOs based system. This, however, means that the files we have found on the internet must had been (unknowingly) uploaded by someone. On the other side this means that not all file names necessarily exist on the server!
The upload might happen if...
- you committed the file to your version control system (e.g. git/svn/etc) and pulled the repo's contents on the server.
- you upload the files using
rsync/sftp/etc without excluding/removing them first. - (the server runs on Mac :D)
If you feel like checking your webserver now, I would recommend running the the following command (on a linux system):
cd /var/www/ #wherever your webserver's document root is
find . -type f -iname "*.DS_Store*"
This command searches through all folders in the /var/www directory for files that have .DS_Store in their name and prints them.
If you find any files that are not intended to be there, you might be leaking some file names. You can delete the files by appending -delete to the previous command.
Furthermore, you can harden your webserver to deny access to those files.
Apache
Add the following block to your httpd.conf:
<Files ~ "\.DS_Store$">
Order allow,deny
Deny from all
</Files>
Nginx
Put the following lines into your server block:
location ~ \.DS_Store$ {
deny all;
}
Let me finish with a short conclusion about the things that I (or we?) have learned from this blogpost. Writing a parser for a (proprietary) file format allowed my to learn about the internals of file formats and how those can be structured and parsed. Unfortunately, the .DS_Store format is not fully open, so some features are missing and some bugs cannot be explained/fixed. Another important thing that I've learned: Commenting your code is a MUST if you want to understand it a couple of years later. Especially, when it is a more "complex" piece of software like a file format parser ;)
Furtermore, I hopefully convinced you to check your webserver if there are any .DS_Store files laying around that might expose some sensitive files. If you cannot find any, you should still add a configuration rule to deny access to those files and check back with your developers that those files will not be committed or uploaded anywhere in the first place!
Last but not least, I would like to thank the people who did the hard reversing part and published their notes online! Otherwise I would not have managed to have my fun with the file format :)
-=-