注:本文基于刘洪善5月25日在“2024OWASP中国数据&AI安全技术沙龙”作的主题演讲删改,网安加社区授权本公众号发布,以作为刘洪善最爱的女儿的第三个六一儿童节的小礼物。
刘志诚老师(左)与宋荆汉院长(右)为刘洪善(中)授予特聘专家荣誉
演讲全文
不好意思,前几天拔了颗牙,所以戴着口罩,很不礼貌,对不起兄弟们。
去年我分享了大模型安全方面的进展,今天则想畅想一下如何利用大模型重构网络安全产品的体验。
一、对大模型的几个简单思考
自从22年底ChatGPT火爆之后,AI首次大规模直面C端用户,以往都是各类算法不同的小模型零散地应用于各业务中,用户没有明显感知到AI的存在。
媒体和产业界通常使用“大模型”来指代这一波AI技术浪潮。但业界对大模型其实并没有明确的定义,当然,“参数大”和“生成式”是这波大模型技术浪潮的2个基本特征,所以准确的说法,应该叫“生成式AI大模型”。
这是我从一本著名的讲解大模型的书《这就是ChatGPT》中截取的图片,它通俗的说明了什么是大模型:伽利略做自由落体实验,积累了许多数据,堆满了实验室,但这么多数据最后只总结成了一个简单的函数,以代表自由落体运动的物理规律。
大模型本质上是一个超级大的函数,通过输入大量数据进行训练后,不断调整这个函数的权重,最后抽象出这些数据背后的共同规律或者函数表示,以预测输入之后的下一个词(Token)是什么。这种预测能力,要求它去“理解”文本代表的人类世界的含义。
顾名思义,大模型之所以这么神奇,核心原因就是“大”。AI行业有一篇著名的论文,名为《The bitter lesson》,在这篇论文中提出一个简单的道理,即我们利用各种新奇算法来解决的问题,最后发现都不如大力出奇迹,直接用简单的算法加大量的算力,反而是终极解决方案,这就是大模型得以出现的思想基础。可以说OpenAI一帮杰出的科学家,用工程实践,“重新”发现了这一原则,也即著名的“Scaling Law”。
大模型的训练,分为四个阶段。
第一阶段,是用大量数据进行预训练,得到基础大模型,这时大模型有了大量的人类知识,但生成方式不可控,只知道预测下一个词(Token),一直给你补下一个词,生成的内容可能对人类而言是无意义的。
第二阶段,使用少量人类标注好的高质量问答对数据对大模型进行微调,实际就是在已经得到的基础大模型的基础上改变部分权重,使得确定的知识得到确定的回答,得到有监督微调模型。
第三阶段,对得到的模型的同一提示的不同回答进行人类评分,基于评分数据,训练出一个奖励模型来使得模型的输出与人类价值观对齐。
第四阶段,则是综合以上阶段进行强化学习,调优成最终模型。其实阶段三和四合在一起,就叫人类强化学习。
ChatGPT为什么能在这个时间点出现,让大模型爆火?除了OpenAI的集体努力,还得益于摩尔定律使得算力提升了数十亿倍,另外,互联网的普及,为大模型的诞生积累了大量数据,缺一不可。
那大模型有什么技术特点,让业内人士这么兴奋呢?
首先,海量的人类数据,让它拥有了海量的人类知识。
其次,知识密度导致它有或者看上去有一定的推理能力,也就是智能涌现,具有了“大脑”的特征。
再次,“大脑”的存在,使得通过大模型统一的联接各类服务和数据,打破服务和数据的孤岛状态成为可能。
再次,是新交互,也就是多模态交互,它现在能够理解语言、图片、视频等,非常像人类的学习和沟通方式。
最后,大模型所广为人知的缺点,但在我看来其实也是优点,就是有幻觉,如果你需要正经、严肃的答案,那么有时候可能会胡说八道,但如果你需要创造力和想象力,大模型的幻觉就是创造力和想象力。
基于这5个特点,结合现有产品和业务场景,就能摸索出提升用户体验和业务指标的办法。
总的来说,它是一个什么都懂,口才非常好,学习能力超强,完成工作非常迅速,充满想象力,不休不眠的初级员工。OpenAI的副总裁在接受采访时也表示,有了GPT4,你可以认为有了无限数量的实习生,但你要怎么用好这些实习生来创造价值?这是需要思考的组织学问题。
在AI领域做产品,受2个因素制约,一个是用户需求,另外一个是技术边界。传统的软件技术发展到现在,你只要有用户需求,很少有实现不了的软件技术。但在AI领域,特别是大模型这个领域,它的输出其实是不稳定的,因为它的底层数学原理是基于概率统计的,那它的输出就有不稳定性,这一点也跟人类很像,人类的表现也不会是始终如一的,这时你就要考虑技术边界的问题,在当前大模型的技术边界内做产品,这也是一个必须遵守的“物理定律”。
那目前业界主要用大模型来做什么产品?主流都是往智能体方向发展,有三个方向:情感陪伴、个人助理和行业智能。
情感陪伴,追求的是让智能体具有类人的特点,以拟人的方式与用户沟通,回应用户的情感陪伴诉求,典型的产品是Character.AI,比较知名的形象,是电影《Her》里面的萨曼莎。要攻破的难点,是怎么在多模态大模型的基础上,微调出一个有长期记忆、有个性的助理。
个人助理,是行业中花费最多人力和资源去实现的产品,主要是帮用户解决重复复杂的非过程类任务,或者说是用户只想得到一个结果,但不想体验过程的任务,其实也可以叫“软件自动驾驶”,比如订明天去北京的酒店机票,给一个时间和地点,制定合理的出行攻略等等,也就是一个管家的角色,类似于《钢铁侠》里的贾维斯。
这类助理,实际就是在现有的产品,比如现有的手机操作系统之上,构建一个以大模型为大脑,以调度软件操作为四肢的“智能代理”或者“智能体”,从而组成一个“手机自动驾驶系统”。
思路是不难,难的是实现,最大的问题是生态,因为你要“驾驶”的是各种软件,哪个软件愿意不触达用户,而愿意甘当绿叶去让你“驾驶”?他们的流量不要了?现有的商业模式不要了?只为做助理的公司,比如手机厂商打工?不可能,完全不可能。
所以未来,更大的可能是各类软件也会拥抱大模型,形成自己的大模型助理。以后是助理和助理之间沟通,而不是用户和助理之间沟通。比如我要订一个机票,那我的手机助理自己去跟美团的大模型助理沟通,给我一个结果就行,这起码部分保障了软件生态的利益。
除此之外,成本、时延、硬件适配等等都是一个个难题。但我是坚定这个方向是对的。目前处于中间状态的典型就是微软的Copilot系列产品,这个系列虽然还是“辅助驾驶”,但辅助驾驶,是通往自动驾驶的必经之路。有人会问,为什么微软的Copilot系列不存在生态问题?因为这些产品本来就是他家的啊!所以,我还是那个观点,目前,先把自家的产品优化了,再去谈生态,不要一下子操那么大的心。
行业智能,针对特定的行业需求,如教育、医疗等,利用特定的数据集去微调,以获得特定行业的知识和应用。演讲的第二部分,会以安全行业为例来稍微展开。
再说说大模型的成本问题。虽然在我作这个演讲的时候,各大云厂商正好在做大模型价格战,但真正高质量的大模型的成本问题仍然是大模型技术普及最大的障碍,因为在价格战中的大模型要么质量一般,要么其实你只要真的大量调用,肯定来个“升级”交费,所以成本没有什么本质改变。
对手机厂商或者互联网厂商而言,一个1000万日活的内置了大模型的应用,调用一次需要大概1分钱,基本上用户如果每天使用10次的话,一天就要花100万人民币。1000万日活的应用在行业里并不算很高,如果是上亿的用户,都把大模型类的应用用起来,那成本是哪个企业也接受不了的。所以目前大模型相关的应用用户并不多,多了之后,如何变现,也是一个悬在行业头上的绕不过去的大问题。
成本的原因也导致端云结合、大小结合是必然。例如将70亿以下端侧模型,与1000亿左右的云侧模型相结合,复杂任务用大的,简单任务用小的。基础大模型最终会与云计算一样,全球一定会只剩下几家,多了没有必要,因为没有带来什么不同的差异和价值,其他个人和公司就基于基础模型做应用。目前国内的模型是过剩状态,过2年,80%的基础模型公司都不会继续存在,因为在商业上,说不通,投资回不来。
大模型无论怎么组合使用,首要原则就是用户导向、产品驱动。虽然我提到了目前行业在发力智能体,做情感陪伴、个人助理和行业智能,但都刚刚开始,我不像业界某些专家大佬那么乐观,他们说今年一定会爆发大模型的杀手级应用,我看不到这个趋势。我认为这几年,用大模型来对现有产品和业务进行提升,是毫无疑义的主流。
你非要说杀手级应用,我认为现在最大的杀手级应用就是ChatGPT,但它的流量和日活是有下降趋势的,因为也没人会天天跟一个机器人闲聊,也没那么多问题天天问。
所以,好好的去考察你现有的产品和业务的刚需高频的痛点,看看能不能用大模型去解决或者部分改善,才是一条比较务实的道路,例如大模型结合手机、汽车、VR等硬件,去提升用户体验,产生粘性,最终实现投资变现。能够短期投资变现,才有长期未来。
总的来说,我今天恐怕就是作为一个布道者,来鼓吹大模型的,因为我认为大模型是人人可用的技术,大模型的暴力美学,将AI技术、软件技术的门槛打低到每个企业、每个人都可以构建自己的大模型来重构业务和产品体验的程度,算法和代码不再是普通人的门槛。这样平权的智力引擎,历史上什么出现过?这是多么激动人心的大事件啊!一定要拥抱拥抱再拥抱!
二、大模型可能如何重构安全产品的体验
因为我没有实际做过这方面的工作,所以我一再强调,只是畅想,抛砖引玉。
通用大模型虽然很好,但它很难既通用、又专业、还便宜,也是一个“不可能三角”,因为通用大模型的数据,大部分是从网上爬来的,而行业数据绝大部分不会放在网上,大模型缺乏行业知识这是再正常不过了。
所以通用大模型在某些特定领域的专业性不足,这就导致了前面我说的第三个方向——行业智能的发展是必然趋势。
通过哪些手段,去获得特定行业特定领域的专业的大模型呢?主要是提示工程、检索增强生成、微调和预训练。
首先是提示工程,这个成本最低,基本方法是不断尝试不同输入,观察通用大模型能否给出更好的答案。这基于一个假设,那就是通用大模型已经具备了这个行业的某些知识。对浅度的知识,一般也可以满足的。
第二个是检索增强生成RAG,可以简单理解成把行业知识向量化之后,变成一个外挂知识库,当你询问大模型时,先去知识库检索跟问题相关的的知识,放到输入提示里,让大模型来理解和生成更专业的答案。因为这个方法不需要用数据来改变大模型的权重,保密性较好,是目前行业首选的方案。
第三个是微调,前面已经说过它的一般方法。它要求高质量的数据整理,并且数据会被内化到大模型的权重里,如果不是私有部署的大模型,有数据泄露的风险。
最后是预训练。由于代价很高,一般企业不会使用。
上面的几个手段,得到一个行业大模型之后,与安全产品结合,可能会有怎样的体验提升?我这里抛砖引玉,提几个场景讨论讨论。
首先,是安全知识沉淀。将企业积累的知识库和专家经验变成数据集之后,在基础大模型上进行微调;或者切片量化后形成RAG。这样,公司可以有一个体验更好的知识沉淀和变现方式,而不是干巴巴的文档传承;专家也能更好的传承自己的经验。另外,对初级安全人员和非安全人士,在遇到不懂的问题时,可以有一个快速解惑的渠道。当然,也可以面向企业内一般员工做更有趣的信息安全知识科普等等。
第二个是安全智能体。即通过好的运营,鼓励专家基于安全智能体平台创建和导入个人经验,给活跃和受欢迎的专家以激励,实现高质量知识和数据的“众筹”,也能一定程度解决企业有数据但没有整理形成的数据来源问题。比如,我写的几百篇安全产品和技术文章,能否导到智能体平台去微调或者形成RAG,得到一个“刘洪善智能体”?别人跟这个智能体对话,基本和我对话差不多,因为我知识储备也就是这几百篇文章。
第三个是代码安全扫描与分析。传统扫描器一个很大的问题,是无法识别长一些的代码上下文的安全问题,为了效率,很多企业是将代码切片后扫描的。但上下文理解,正好是大模型擅长的地方之一,通过大模型的广博的代码知识和上下文理解能力,有可能发现传统扫描器无法识别的代码安全问题。这是去年ChatGPT刚火的时候,我写的一个安全专利的基本思路,也申请通过了,其实很简单,但实现起来不容易。
第四个是安全数据分析。比如我之前做安全运维时,动辄收到几万条报警信息,无论是漏报、误报还是真报,人工方式去检查总是难以应付的,大模型能否在这方面发力?联系起它是一个数量近乎无限的实习生的定位,让几万个实习生去验证几万条报警,似乎是瞬间完成的事。这个方向虽然看着很兴奋,但因为现在的数据一是量大,二是格式各种各样,不只是文本的,怎么整理成大模型可理解的数据形式,本身就是个难题,三是实时性无法保障,所以也抛出来同大家一起研究。
第五个是安全信息总结。前面我也提过,信息总结也是大模型最擅长的领域。比如把安全相关的书本、资料、链接丢给大模型,就可以立马总结出核心要点,并且可以做到多轮问答、多轮追问。对安全专业的学生,写论文会有较大帮助;对安全行业从业者也可以从中节省大量的时间,又获得精炼的安全知识和资讯。
最后,是安全自动驾驶。即利用大模型Agent的感知、决策、执行能力,包括调度工具的功能,进行自动的安全态势判断,并执行相应的安全策略。前面我说过,这是业界都在探索的方向,但实现起来有非常多的工程难题,有赖于技术的进一步发展。
以上只是一些随意的畅想,其实深入到每个产品,每个场景,肯定都会有大模型的用武之处,欢迎大家基于大模型的特点,继续畅想和讨论。另外,要真实践起来,肯定会有许多工程难题,但积极尝试是必不可少的,所谓沿途下蛋,你往那个方向冲,只是冲到一半,可能你已经是最厉害的人了,总比不冲好。
三、大模型是天下人的大模型
我前面讲了这么多,我总的是想告诉大家一句话,我认为大模型技术具有很好的前景和潜力,与各行各业,包括安全行业结合,肯定会有很多化学反应,我一点都不怀疑。当然,前途是光明的,道路是曲折的,还有很多工作要做。
经过一年的交流,我也发现大家会有一种焦虑,就是认为大模型技术变化太快,无所适从,总怕自己投资下去,一个新的大模型出来,之前的投资是否失败或者废弃了?
这经常让我想起亚马逊创始人贝佐斯的一句话“我常被问一个问题:‘在接下来的10年里,会有什么样的变化?’但我很少被问到‘在接下来的10年里,什么是不变的?’我认为第二个问题比第一个问题更加重要,因为你需要将你的战略建立在不变的事物上。”
同样的道理,无论AI技术怎么快速发展,我们都要在变化中寻找那些不变或者基本不变的东西,我认为就是一套以客户需求为导向的业务框架。
在这套框架里,大模型只是一个智力引擎,其他投资是四肢。客户需求是相对稳定的,框架也是相对稳定的。一定要在客户需求框架下思考AI大模型与业务的深度融合。有了框架,则技术的变换,只是换了引擎,其他零部件的投资并没有被放弃。
最重要的是,能够在一个相对稳定的框架下,不断积累业务经验。
最后,说了那么多的壮怀激烈、雄心壮志,咱们回归现实,自己往自己头上浇点冷水,清醒清醒。
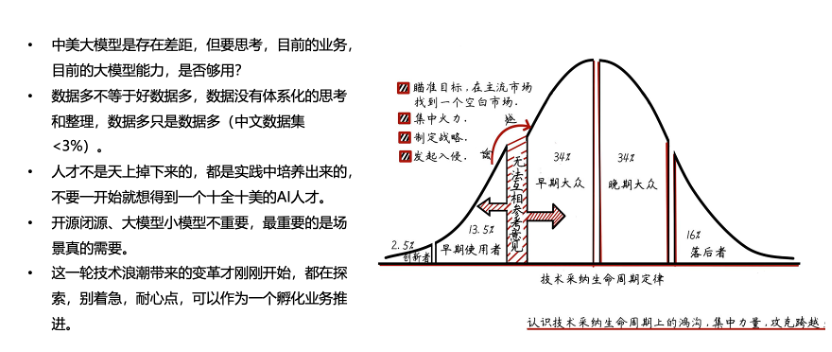
大家应该都知道著名的跨越鸿沟理论,即一个新技术刚开始的时候,依次要经历几个采纳周期。
刚开始,通常是一批创新者或者发烧友先尝试这个技术,即使产品体验不好,他们也愿意探索,去发现技术背后激动人心的价值。
他们往往会把这个技术推销给另外一波人,叫做早期使用者,他们通常是社会精英,胸怀大志、手握大权,只要他们也认识到这个技术的潜力,那么,就会有大量的资源投资这个技术,从而加速这个技术的发展,典型的如微软的比尔盖茨对OpenAI的投资,刚开始他不看好,但后面他看好之后,OpenAI从微软拿到了天量的资源去快速发展他们的技术。
技术有了发展,产品有了提升,但如果不普及到广大群众里,其实是没法闭环投资的,因为量不够。量不够,那就永远只是少数人的昂贵玩具。怎么让玩具变成一个人人可用的消费品、从而产生一个巨大的行业?这就是早期使用者和早期大众之间巨大的鸿沟。
目前大模型就处于这个鸿沟的左边,远远没到普及的程度,技术成熟度、产品体验和成本都是一道道小鸿沟。当然,大家感觉大模型这2年如火如荼,那是因为你是从业者,你可以询问你的妻子或者亲戚,他们大概率不了解大模型的含义,也没用过大模型的应用,或者用过了也不知道什么大模型小模型。所以大家不要过于亢奋,要把大模型技术普及开,还需要开展很多艰苦的工作。
第一,中美大模型还存在较大差距,这是毋庸置疑的。我经常看到一些公司跳出来说中美大模型差距3个月、6个月、不到1年等等,我就觉得这是在误人子弟。
我们不宜妄自菲薄,但也不宜盲目乐观。我觉得大模型的从业者一定要头脑冷静下来,务实、敬畏的向一切强于我们的人学习,学习的前提是清晰的知道自己的差距,最起码,承认确实有差距。
中美顶尖大模型的差距绝对不止6个月,不能是人家发布了一个模型,你基于研究别人的基础上用6个月追上了,所以差距是6个月;那是别人厚积薄发,正常迭代版本出来的水平,那要是GPT5憋个大招,迟迟不发布,你用什么去追赶?
创新能力的差距,用时间来衡量是不对的,正确的衡量方式是我们的创新氛围、创新能力组成的一个整体的创新引领能力的差距,这种差距,都是5年10年为纬度的差距,因为要做很多基础工作,比如AI课程进入课堂,培养大量的科学家,给人才以宽松的研究环境,这都是说了几十年而未解决的老大难问题。
我们可以以实用主义的态度,去用别人已经走出来的经验,站在巨人的肩膀上看得更远,但如果巨人不让你站在他肩膀上了呢?所以要清醒的认识差距,好好的在真正需要努力的地方去自立自强。
另外一方面,也要思考,目前的业务,目前的大模型能力,是否够用?目前的环境下,没法说你的基础大模型是最强的,也没有必要,这个东西本来就在快速演进,你能做的是思考什么业务什么场景需要大模型来解决什么问题,现在的技术够不够你去解决这个问题。
第二,数据多不等于数据好。这是我与行业交流多年后得出的感受。我们经常说自己是数据大国,这没错。但我发现很多企业并未进行数据整理,数据库里有数据,硬盘里也存了几百GB、几TB的数据,可仔细分析起来,要么很多是无效数据,例如过程记录或者警告记录,要么没有整理成AI可训练的数据格式,或者缺失的数据维度,没法在市场上获得,这基本是一个数据生态的构建问题。所以,目前中文高质量数据集可能只占了全球的1%-3%。没有数据,哪来的AI ?这是一个现实,我们必须努力构建数据生态。
第三,大模型人才不是天上掉下来的,是在实践中培养出来的。不要一开始就想得到一个又有大模型技术产品理解,又有行业知识的人才,这样的人,你基本找不到,因为这样的人要么自己创业了,要么已经被人重金挖走了,所以还是要靠自己培养。我前面也说了,大模型其实从原理到应用,门槛已经很低了,培养人的成本并不高。当然,最基础的算法方面的知识,还是有一定门槛的,需要不断加强该领域基础知识的学习。
第四,开源闭源、大模型小模型不重要,最重要的是场景真的需要。研究业务场景与大模型的结合,应该是每一个企业的核心工作。
第五,这一轮技术浪潮带来的变革才刚刚开始,我认为大家都在探索和起步,谁也不比谁懂得更多,别着急,耐心点。个人要沉下心去学习和实践,企业也可以作为一个孵化业务推进,给大家一些空间。
最后,我衷心认为大模型对每个企业、每个人都是一个大好的历史机会,我们真是遇上了一个百年未有之大变局,大家可以结合现有工作,各自探索、研究、投资,广阔天地,大有可为。
今天的分享,时间有点超了,谢谢大家。
如有侵权请联系:admin#unsafe.sh