原文标题:NetMamba: Efficient Network Traffic Classification via Pre-training Unidirectional Mamba
原文作者:Tongze Wang, Xiaohui Xie, Wenduo Wang, Chuyi Wang, Youjian Zhao, Yong Cui
原文链接:https://arxiv.org/pdf/2405.11449v2
发表会议:arXiv预发布
笔记作者:张强@安全学术圈
主编:黄诚@安全学术圈
1 介绍
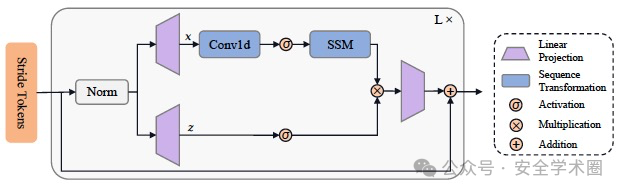
《NetMamba: Efficient Network Traffic Classification via Pre-training Unidirectional Mamba》这篇论文的核心贡献在于提出了一个针对网络加密流量分类的新型预训练模型NetMamba(图1所示),它通过单向Mamba架构和全局流量和步长字节分割表示策略,有效地提高了模型的效率和分类性能。
2 本文方法
2.1 数据集
本论文在多个公开数据集下进行了下游任务的微调:
CrossPlatform (Android & iOS): 包含254和253个应用,用于加密应用分类。 ISCXTor2016: 包含8个通信类别的Tor流量数据,用于加密流量分类。 ISCXVPN2016: 包含7个通信类别的VPN流量数据,同样用于加密流量分类。 CICIoT2022: 用于攻击流量分类,构建了6个数据类别。 USTCTFC2016: 用于恶意软件流量分类,包含20个数据类别。
2.2 流量特征
按照如下图所示的流量将原始数据包转换一系列字节数组后,按照一个合适的步长对其进行切割,再加入每个流中前面某几个包作为全局信息,以实现降低内存消耗的同时保留序列信息和字节间潜在的关系。
2.3 方法的创新点
NetMamba: 一个高效的线性时间状态空间模型,配备全局流量和步长字节分割表示策略。 流量表示: 保留有效信息,去除有偏信息,如全局流量和基于步幅的数据切割。 使用单向Mamba架构代替Transformer(如图3所示),以解决效率问题。 预训练策略: 使用掩码自编码器(MAE)结构在大量未标记数据集上通过重建mask过的分割步长的方式进行自监督预训练,学习加密流量数据的通用表示。
2.4 实验结果
在所有分类任务中,NetMamba几乎达到了99%的准确率(有些超过99%)。 相比于现有的基线,NetMamba在推理速度上提高了高达60倍,同时保持了较低的内存使用。 在少样本学习方面,NetMamba表现出色,即使在标记数据较少的情况下也能实现更好的分类性能。
3 作者团队介绍
论文通讯作者为清华大学计算机科学与技术系-计算机网络研究所谢晓晖助理研究员(邮箱:[email protected]),其研究领域为互联网体系结构,网络安全,人工智能。
4 其他
论文代码的公开访问链接:https://github.com/wangtz19/NetMamba。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
文章来源: https://mp.weixin.qq.com/s?__biz=MzU5MTM5MTQ2MA==&mid=2247490816&idx=1&sn=7a36d1533fc7955fe4e1a5f1140d4b3a&chksm=fe2ee28bc9596b9dbfc0c8df9419d7a3ced5839467eadf4e837f531b755315b06a891779937d&scene=58&subscene=0#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh