2024-6-6 05:0:22 Author: hackernoon.com(查看原文) 阅读量:4 收藏
Authors:
(1) Surya Narayanan Hari, Department of Biology and Biological Engineering California Institute of Technology (Email: [email protected]);
(2) Matt Thomson, Department of Biology and Biological Engineering Program in Computational and Neural Systems California Institute of Technology (Email: [email protected]).
Table of Links
Conclusion and discussion, and References
Abstract
Currently, over a thousand LLMs exist that are multi-purpose and are capable of performing real world tasks, including Q&A, text summarization, content generation, etc. However, accessibility, scale and reliability of free models prevents them from being widely deployed in everyday use cases. To address the first two issues of access and scale, organisations such as HuggingFace have created model repositories where users have uploaded model weights and quantized versions of models trained using different paradigms, as well as model cards describing their training process. While some models report performance on commonly used benchmarks, not all do, and interpreting the real world impact of trading off performance on a benchmark for model deployment cost, is unclear. Here, we show that a herd of open source models can match or exceed the performance of proprietary models via an intelligent router. We show that a Herd of open source models is able to match the accuracy of ChatGPT, despite being composed of models that are effectively 2.5x smaller. We show that in cases where GPT is not able to answer the query, Herd is able to identify a model that can, at least 40% of the time.
1 Introduction
Large language models have found novel ways to increase the number of use cases, such as by expanding the number of parameters, combining existing models to augment a single models’ functionality and quanitizing large models to fit on smaller devices [4, 12, 9, 18, 2, 8, 13, 3–5]. The rapid expansion of model availability has created a significant challenge in practice, where corporations want to expose performant LLM endpoints for their users, and have to spend time evaluating models to find the best one that works for them in practice. To overcome this problem, engineers often resort to proprietary models without knowing if there are open-source models available at a comparable performance standard.
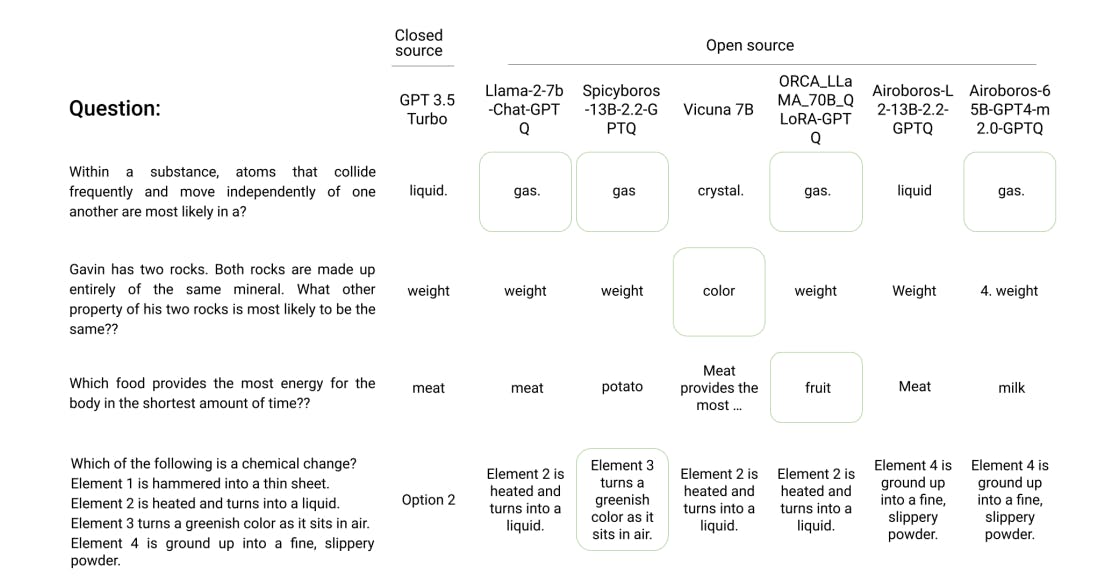
This often leads to the problem elaborated in Figure 1, showing examples of questions taken from MMLU that ChatGPT (GPT 3.5 Turbo) answers incorrectly, but there is some open source model that can answer the question correctly. We use this insight to try and construct a herd of models such that at least one model in the herd can answer any incoming query correctly.

Recent model evaluation frameworks [6, 19] help users compare LLMs against each other, but the growing pace of model formats, outpaces one-size-fits-all comparison software suites. Empirical evidence in this work, reveals that open source models have caught up with leading proprietary models, but not all open source models feature on leaderboards, due to their vast number.
Deployment of models also remains a key challenge. The 70b parameter Llama-2, in 16-bit precision, requires 2 80Gb A100 GPUs, and in practice, users might want several models running in parallel. Sacrificing parameter count to cut costs risks performance degradation, the exact magnitude of which is unknown before deployment.
While quantized models might alleviate some of the challenges associated with model deployment, finding performant quantized models, navigating their formats and knowing their training details, such as what datasets were used in their quantisation calibration, requires expertise.
In addition to quantized variants of models, specific model variants exist with chat capabilities, with different performance metrics from non-chat models. Others with more specific domain expertises such as science or code [17, 1], might be useful for some user applications but aren’t fine-tuned for chat capability, making it harder to pick one model to use in production.
Today the Huggingface (HF) model repository contains ∼24,000 machine learning models for text generation. While model cards might provide some insight into the dataset that a model is trained on, common practices such as fine-tuning models using inputs from other large language models or model merging [10, 16, 14, 11] has made it difficult to track what data was used to train the model. This has also made it challenging to track what datasets or tasks one can expect the models to be performant on. Futher, not all open source models have detailed model cards, making trusting them in deployment even more challenging.
Together, it would be a useful service to expose an endpoint that would process an incoming users’ request by abstracting away model selection. Here, we explore the advantage of exposing a model herd of open source models, which outperforms a larger, proprietary large language model, offering size advantages. We also train a Tryage router [7] to predict model performance, and show that the model herd is able to answer 74% of incoming queries with performance comparable to or better than ChatGPT.

Herd Architecture

Demonstrating Her
We find that a herd of open source models is able to beat ChatGPT (Figure 2) despite being effectively less than 30% of the size (effective size measured as the average size of models weighted by the number of examples allocated to them. Further, none of the models in the herd were individually better than ChatGPT, but together, they were able to surpass ChatGPT’s performance. Further, all the models are open source, and the herd can be seamlessly expanded, contracted or interchanged for other models
We trained a tryage router [7] to model the performances of a herd and found that the router was able to successfully allocate incoming queries to models that produced aggregate performance comparable to GPT 3.5 Turbo despite being effectively 2.5x smaller 3a [1] . Further, some models in the herd are quantized, meaning they can be run on edge compute / cloud compute - a user can trade off the size of a herd for compute cost.

We show that Herd can capture knowledge in cases where ChatGPT fails to answer an incoming query. While any single model might not be able to answer all the incoming queries, Herd is able to find a model that can answer each query, based on the input text of the prompt. ChatGPT is only able to beat a herd of open source models 26% of the time, implying 74% of the queries can be answered by open source models (Fig. 3b, ‘beat’ is defined as F1 in excess of 5%).
In the cases where ChatGPT was wrong, defined as when ChatGPT had an F1 score of less than 0.9, Herd was able to achieve a correct answer (defined as when any model in the Herd had an F1 score greater than 0.95), 69.3% of the time. A predictive router, was able to identify a model that can answer the query correctly, 40% of the time (Tryage bar in Fig. 3c). The mean of the F1s of the answers from each model, as well as the aggregate F1s from Herd and the predictive router, are shown in Figure 3c.
[1] exact number of parameters in ChatGPT (GPT 3.5 Turbo) unknown, based on reported information
如有侵权请联系:admin#unsafe.sh