基本信息
原文名称:MINER: A Hybrid Data-Driven Approach for REST API Fuzzing
原文作者:Chenyang Lyu;Jiacheng Xu;Shouling Ji;Xuhong Zhang;Qinying Wang;
Binbin Zhao;Gaoning Pan;Wei Cao;
Peng Chen;Raheem Beyah;
原文链接:https://www.usenix.org/
conference/usenixsecurity23/presentation/lyu
发表期刊:32nd USENIX Security Symposium
开源代码:https://github.com/
puppet-meteor/MINER
一、引言
二、研究动机
MINER的基本框架如下图所示,主要由5部分组成:
即:序列模板选择模块、生成模块、Fuzz模块、收集模块、注意力模块
基本的工作流程就是MINER持续生成连续的请求来测试云服务的rest api。MINER如同已经存在的fuzzer一样在编译模块构建请求模板来测试rest api。首先,利用序列模板选择模块,在概率上根据长度选择请求序列模板,然后延展这个序列。再用生成模块生成序列模板中的模板请求并构造能够使用的序列。模糊测试模块会测试生成的请求序列。收集模块会收集历史数据。历史数据应是有效请求并且相关变异的参数。用参数值对,来表示变异参数以及在请求生成中使用的值。最后,周期的在训练模块用收集到的键值对来训练一个注意力模型。用这个训练的模型,对每一个请求模板来生成需要的键值对。
图1 MINER流程概述图
三、模块细节
在这个组件中,MINER 基于从收集模块收集的种子序列模板构建候选序列模板。具体来说,MINER 首先根据其长度为每个种子序列模板分配不同的选择概率。序列模板越长,其选择概率越大。因此,MINER 获得了一组选定的序列模板,这些模板的长度往往更大。其次,对于每个选定的序列模板,MINER 执行扩展过程以构建候选序列模板。换句话说,MINER 在所选模板的末尾添加了一个新的请求模板。基于上述设计,MINER 实现了长度定向序列构建。在实现中,我们使用 log10(l + 1)作为序列模板选择的概率函数,其中 l 是序列模板的长度。
图2 序列模板选择模块细节
2. 生成模块
在这个部分中,MINER会在候选序列模板中生成每个请求,即MINER会为每个参数分配一个值,不包括请求中的目标对象 id。如图3所示,MINER实现了两种方法来生成请求。第一个是传统的生成方法,即为每个参数随机选择一个替代值,第二种方法的过程如下所示。
图3 生成模块
为了生成请求,MINER 1) 为每个参数选择默认值;2) 找到那个用于变异的键值对的集合,这个集合是通过注意力模型对这个模板生成的;3) 根据均匀分布从键值对集合中概率的选择候选概率键值对;4) 根据键值对集合中选定的值,来调整参数。对于不在所选参数值列表中的参数,MINER 保留在请求生成中使用的默认值。通过执行上述过程,MINER 实现了基于注意力的请求生成。
在实现中,为了生成包含 n个请求的序列,MINER 使用键值对表的方法来生成前 n-1 个请求,并使用传统的生成方法生成最后一个请求。原因如下。在生成前 n-1 个请求时,MINER 希望利用键值对表来提高生成质量。这有助于触发目标云服务的正常执行。然后,MINER 利用传统的生成方法生成最后一个请求,以增加触发异常行为的概率,例如,尝试创建一个参数值不符合定义的类型的资源。
3. Fuzz模块
在这个组件中,MINER执行以下过程来探索独特的错误。首先,MINER通过其REST API将生成的请求序列发送到云服务,并分析每个请求对应的响应。如果MINER收到了一个50×范围内的响应,MINER认为对应的请求触发了错误,并将生成的序列及其响应存储在本地以供将来分析。其次,MINER利用每个安全规则检查器对当前请求序列进行变异,以触发特定的规则违反。特别是,我们提出了请求参数违规检查,并实现了一个名为DataDriven Checker的新安全规则检查器,以找到由于不正确的参数使用而导致的错误,其目标规则违反如下所示。
图4 FUZZ模块
一般来说,供应商为每个请求定义特定的参数,以触发云服务的特定行为。如果用户向请求添加未定义的参数并将其发送到云服务,则云服务通常会忽略未定义参数的不正确使用,并根据定义的参数值执行行为。然而,由于各种情况,云服务可能会根据未定义的参数执行意外行为,例如参数定义的改变和不正确的代码实现。意想不到的行为可以触发与安全相关的异常,例如云服务可以访问不存在的资源。因此,由于参数未定义,云服务的过程可能会崩溃并返回50X范围内的响应。
为了捕捉这种规则违规,DataDriven Checker 在生成过程中向请求添加了一个未定义的参数值对。具体来说,对于序列中的最后一个请求,MINER 随机选择收集模块中收集的未定义的键值对。然后,MINER 将所选的键值对添加到序列的最后一个请求中。最后,MINER通过其REST API将新构建的请求序列发送到云服务。如果云服务在50×范围内返回响应,MINER认为新请求触发不正确的参数使用错误,并在本地存储序列以进行进一步分析。
4. 收集模块
在模糊测试过程中,MINER首先收集有效的请求序列,其中所有请求都通过Fuzzing Module中云服务的检查。这些序列被用作序列模板选择中的种子序列模板,以指导序列构建。其次,MINER分析来自云服务的每个生成的请求的响应,并提取在通过检查的有效请求中使用的键值对。具体来说,如果一个请求在20×和50×范围内收到响应,这意味着请求通过了检查并触发了云服务的某种行为,MINER会分析请求中每个参数的使用值。如果使用的值不是参数的默认值,MINER将该值视为对该参数的关键突变,并将其存储为键值对。因此,MINER为每个有效请求收集了一个键值对列表,其中包含有效的突变,以帮助通过云服务的检查。
图5 收集模块
收集的列表用于 1)训练Training Module中的注意力模型,以及 2)为DataDriven Checker提供未定义的键值对,以触发不正确的参数使用错误。
5. 训练模块
MINER 定期调用训练模块以使用收集模块中收集的键值对来训练注意力模型。训练后,MINER 利用模型生成每个请求模板的键值对表,该表将用于生成模块以生成请求。
图6 训练模块
在训练模块中,MINER使用从在20×范围内触发响应的请求中收集的键值对表作为训练数据来训练注意力模型。
1)在训练模块中,MINER使用从在20×范围内触发响应的请求中收集的参数-值对列表作为训练数据来训练注意力模型。按一般机器学习处理方式,将所有词嵌入到向量中。因此,在收集模块中收集的键值表被转换为一组向量序列(类似于图7中所示的输入序列)。
2)MINER随机将向量序列分为训练集和验证集,分别用于训练模型和验证模型的预测性能。
3)在每个集合中,MINER利用一个向量序列来训练/验证注意力模型。具体而言,MINER使用序列中前n个向量作为输入,第n+1个向量作为期望输出,如图7所示。在训练过程中,模型自适应调整神经元之间的权重,并增加期望输出向量的预测概率。例如,假设理想输出为<Pair T+2>如图7所示,模型将调整权重以提高<Pair T+2>的预测概率,并降低其他的预测概率。
4)在MINER完成一定数量的训练周期并将预测准确性提高到稳定水平后,训练过程结束。
图7 注意力模型在MINER中的结构
四、MINER中的数据流
在这个小节中,我们从数据流的角度阐述了三个核心数据驱动设计在MINER中如何共同工作。如图5所示,在收集模块中,MINER主要收集三个数据集:1)成功通过云服务检查的请求序列集合;2)来自在50×范围内具有响应的请求的键值对;以及3)来自在20×范围内具有响应的请求的键值对。接下来,我们说明MINER中的哪个设计利用了这些数据集。
图8 在MINER中的数据流
对于请求序列集合,MINER将其用于指导在序列模板选择中的序列构建。由于MINER主要在这一设计中处理序列模板构建,因此其他两个数据集不被使用。
来自通过云服务检查并在50×和20×范围内具有响应的有效请求的键值对,被用于在DataDriven Checker中探索不正确的参数使用错误。由于请求在触发潜在错误之前应该通过云服务检查,因此在DataDriven Checker中,MINER不使用来自具有40×范围内响应的请求的键值对。
来自响应在20×范围内的请求的键值对也被用作训练模块中注意力模型的训练数据。因此,注意力模型倾向于生成帮助通过云服务检查的参数-值列表。由于1)在模糊测试过程中,响应在50×范围内的请求非常罕见,2)并非所有类型的请求都能在50×范围内获得响应,它们的数量不足以作为模型的训练数据。因此,在我们的应用场景中,我们不将它们的键值对包括在训练数据中。相反,如果我们在连续模糊测试云服务等应用场景中收集到足够的响应在50×范围内的请求,我们可以利用机器学习模型学习如何生成一个触发50×范围响应的请求,并利用该模型按需生成请求。
五、试验设计及结果
(一)具体实现
在实现过程中,为了衡量我们检查器的错误发现性能,我们构建了两个原型,分别为不带DataDriven Checker的MINER_PART和带有DataDriven Checker的MINER。
1.进行比较的fuzzer
我们对MINER_PART和MINER进行评估,与最先进的开源模糊测试工具RESTler[1]进行比较,RESTler是2019年提出的第一个用于自动探索云服务错误的REST API模糊测试工具。由于另一个REST API模糊测试工具Pythia[2]没有开源,我们无法将我们的模糊测试工具与其进行比较。
2.目标云服务
我们通过表1中显示的11个REST API对GitLab [3]、Bugzilla[4]和WordPress[5]进行评估,选择这些目标的原因如下。首先,GitLab、Bugzilla和WordPress是广泛使用的云服务。评估它们的安全性对供应商和用户都是有意义的。其次,GitLab的REST API的请求模板包含许多参数,支持各种功能。相反,Bugzilla和WordPress的请求模板相对简单,参数较少,限制了可以进行变异的位置。因此,在评估中,我们可以分析模糊测试工具在具有不同功能复杂性的目标上的性能。第三,每个REST API与云服务上的不同资源进行交互。通过这些REST API进行模糊测试,评估的模糊测试工具可以执行不同的代码行并探索云服务的不同状态,从而更全面地检查它们的模糊测试性能。
3.实验设置
每次评估在一个docker容器上进行48个小时,配置有8个CPU核心、20GB RAM、Python 3.8.2和Ubuntu 16.04 LTS操作系统。我们在3台服务器上运行评估,每台服务器配备两颗E5-2680 CPU、256GB RAM和一张Nvidia GTX 1080 Ti显卡。
4.评估指标
为了衡量每个模糊测试工具在请求生成和错误发现方面的性能,我们使用以下三个指标对这些模糊测试工具进行评估。首先,为了评估请求生成的质量,我们测量每个模糊测试工具对云服务的语法和语义检查的通过率,该通过率通过将20×和50×范围内的响应数除以总响应数来计算。其次,为了衡量每个模糊测试工具成功生成了多少个独特的请求模板,我们统计在20×范围内收到响应的生成请求的类型。成功生成并发送到云服务的独特请求模板越多,REST API模糊测试工具触发的行为种类也就越多。第三,我们统计每个模糊测试工具报告的独特错误数量,这些错误触发了50×范围内的响应或违反了定义的安全规则。
(一)具体实验
1.实验一:FUZZ性能分析
如表1所示,我们模糊测试工具中实施的新设计显著提高了在云服务上的通过率。例如,MINER_PART和MINER的平均通过率分别比RESTler在GitLab上高出28.65%和28.28%。MINER_PART的平均通过率比RESTler在Bugzilla上高出35.03%。尽管一些API的请求模板(例如WordPress帖子API)是易于构建的,包含很少参数,但我们的模糊测试工具仍然比RESTler实现了更高的通过率。实验结果证实了我们混合数据驱动方法所带来的通过率改善。
表1 RESTler、MINER_PART与MINER在三个云服务上的fuzz效果
MINER_PART和MINER可以比RESTler生成更多的独特请求模板。例如,MINER_PART覆盖的平均独特请求模板数量比GitLab上的RESTler多8.22%。MINER覆盖的独特请求模板数量比GitLab上的RESTler的Groups API多20.00%。
MINER_PART和MINER在大多数目标上发现的唯一错误比RESTler更多。例如,MINER_PART在GitLab和WordPress上分别比RESTler发现了37.74%和25.00%更多的唯一错误。
2. 实验二:真实错误分析
为进一步评估每个模糊测试工具在真实错误发现方面的性能,我们手动分析了GitLab、Bugzilla和WordPress上每个模糊测试工具报告的所有错误。具体来说,我们筛选掉由于服务器状态更改而无法重现的错误,如第6.2节所讨论的。然后,我们去重由相同原因引起的错误。每个模糊测试工具在三个云服务上发现的真实错误的详细信息如表2所示。
RESTler触发的真实错误的探索空间被MINER_PART和MINER完全覆盖并超出。经过错误筛选和去重后,MINER_PART找到了RESTler发现的所有错误,并发现了6个RESTler错过的新的唯一错误,由此我们可以得出以下结论。
1)由于MINER_PART涵盖了RESTler可能的请求组合,因此由RESTler触发的真实错误也可以被MINER_PART找到;
2)得益于MINER_PART实现的以长度为导向的序列构建,MINER_PART为长请求序列分配了更多的执行次数。因此,MINER_PART发现了由长度大于2的请求序列触发的5个新的唯一错误;
3)我们发现RESTler无法找到第16个错误,该错误由4个请求触发,但所有四个请求都已成功由RESTler生成,因为RESTler成功生成的唯一请求模板数量与表2中所示的WordPress类别API上的MINER_PART和MINER相同。因此,要么RESTler无法构建足够长的序列,要么RESTler无法生成高质量请求以通过WordPress的检查。
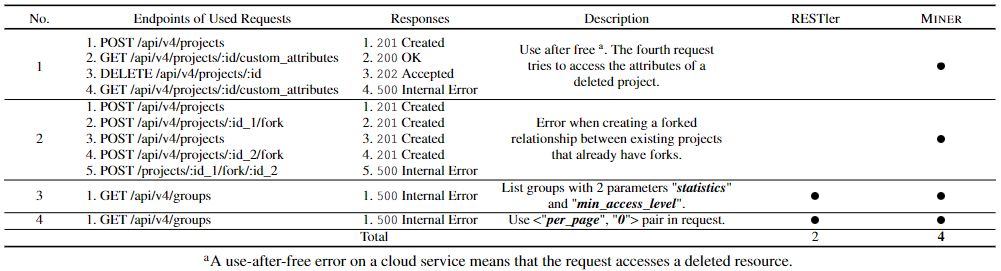
表2 RESTler、MINER_PART和MINER在GitLab、Bugzilla和WordPress上发现的真实错误
3. 实验三:重现严重bug的性能
为评估RESTler和MINER在严重错误发现方面的性能,我们手动检查了GitLab的已发布问题,并收集了4个REST API模糊测试工具可以重现的严重bug作为标准。然后,我们为每个独特的错误构建了只包含相关请求模板的模糊测试语法,如表3所示。例如,要重现第2个错误,模糊测试工具需要正确生成5个请求,并以合理的顺序执行,这些请求基于语法中的4个不同请求模板。每次评估持续时间长达48小时,并重复5次以计算平均触发时间。结果显示在表3和表4中,从中我们得出以下观察结果。
表3 在GitLab上,MINER与RESTler上找到的公开的bug
表4 MINER与RESTler平均花费时间
与RESTler相比,MINER能够更有效、更高效地重现GitLab上发布的严重错误。MINER可以重现所有4个错误,而RESTler只能重现其中的两个。此外,如表4所示,MINER平均需要142.6分钟来构建一个包含5个请求的正确顺序序列,而RESTler无法在48小时内构建该序列。结果表明MINER在严重错误发现方面表现出显著的性能,我们分析原因如下。首先,MINER可以通过以长度为导向的序列构建构建长的请求序列,相较于RESTler,这增加了对复杂请求组合的执行次数。其次,MINER实现的基于注意力模型的请求生成改善了对GitLab难以构建请求的通过率,从而减少了错误的触发时间。
六、局限及不足
MINER的局限性以及可能的解决方法如下所示。
1. 数据集的局限:
由于在模糊测试过程中收集的训练数据不足,我们很难为序列生成训练一个注意力模型。然而,在不同场景下,如连续模糊测试和并行模糊测试,可能会有足够的训练数据用于序列生成。因此,利用机器学习模型为请求序列提供关键的变异策略可能是未来工作中一个有趣的课题。
2. Bug难以复现的局限:
由于服务器状态的改变,一些唯一的错误只能在云服务的特定状态下触发,而在未来的分析中无法重现。这是REST API模糊测试中常见的问题。例如,一个模糊测试工具可以通过访问一个资源来触发错误,该资源是由其他请求序列几个小时前创建的。然而,在接下来的模糊测试过程中,模糊测试工具删除了这个资源,使错误无法重现。因此,如何分析相距较远的请求序列之间的相关性以及如何重现这种错误可能是REST API模糊测试的一个有趣的研究方向。
七、总结
为解决REST API模糊测试工具的局限性并提高其错误发现性能,我们提出了一种混合数据驱动方法,包括三个新设计,有助于发现由长请求序列触发的安全漏洞并探索不正确的参数使用错误。我们基于这一方法实现了原型系统MINER,并通过11个REST API在3个开源云服务上将MINER与RESTler进行了评估。结果显示,MINER在请求生成和错误发现方面比RESTler表现得更好。经过手动分析,MINER还发现了比RESTler多10个真实错误,其中包括5个尝试访问已删除资源的安全漏洞。此外,我们使用GitLab发布的错误作为评估标准,展示了MINER在严重错误发现方面的显著性能。此外,我们进行了广泛的分析,展示了MINER在序列扩展、代码覆盖率和时间开销方面的出色性能。总的来说,我们的方法可以作为改进REST API模糊测试工具的序列扩展、通过率和错误发现的新方向。
参考文献
[1] V. Atlidakis, P. Godefroid, and M. Polishchuk. RESTler: Stateful REST API Fuzzing. In Proceedings of the 41st International Conference on Software Engineering, pages 748–758, 2019.
[2] Vaggelis Atlidakis, Roxana Geambasu, Patrice Godefroid, Marina Polishchuk, and Baishakhi Ray. Pythia: Grammar-based Fuzzing of REST APIs with Coverageguided Feedback and Learning-based Mutations. arXiv preprint:2005.11498, 2020.
[3] GitLab. https://gitlab.com/gitlab-org/gitlab.
[4] Bugzilla. https://www.bugzilla.org.
[5] WordPress. https://wordpress.org.
—END—
如有侵权请联系:admin#unsafe.sh