导读
本文从抖音Android端图片优化历程着笔,主要介绍字节自研BDFresco图片框架及其在抖音的最佳实践、经验沉淀、业务价值。通过分享业务视角遇到的一些问题和我们的解决思路,希望能抛砖引玉,为遇到类似困扰的伙伴们提供有价值的参考。
背景介绍
抖音为什么要持续优化图片能力
图片能力作为抖音最基础的能力之一,服务于抖音各个业务。随着抖音图文、电商、IM等多图业务体量的增长,图片加载量级越来越大,对应的图片带宽成本也在日益增加。为了降低图片成本、提升用户浏览图片体验,需要持续不断的探索和优化图片能力,在保证图片展示质量的前提下,提升图片加载速度,降低图片整体成本,实现图片的 "好快省" 。
BDFresco简介
BDFresco是火山引擎veImageX团队基于开源Fresco拓展优化的Android端通用基础的网络图片框架,主要提供图片网络加载、图像解码、图片基础处理与变换、图片服务质量监控上报、自研HEIF软解、内存缓存策略、云控配置下发等能力,目前已覆盖到字节几乎所有App。
下面将从抖音视角出发,介绍抖音基于BDFresco在图片方向做了哪些优化。
优化思路
一张网络图片完整的加载流程如下:
客户端通过网络获取业务数据,响应内容包括对应的图片数据,通过将图片Url数据交给BDFresco加载,正式开始图片的加载流程。BDFresco会判断当前图片是否在内存缓存及磁盘缓存,若存在则执行对应解码或渲染操作,若不存在则直接走veImageX-CDN下载,将图片资源下载到本地后再进行解码和渲染操作。
图片加载过程不仅占用了客户端内存、存储和CPU等资源,也消耗了网络流量和服务端资源。
图片的加载流程本质上是一个多级缓存逻辑,可以将图片加载流程拆分成4大核心阶段,内存缓存、图片解码、磁盘缓存、网络加载,结合指标监控体系,分别针对各阶段进行优化:
内存缓存优化:当前Android内存缓存命中率高达50%,内存缓存以占用App宝贵的内存为代价,使得我们可以快速地访问图片;但内存缓存的存在并不会直接导致App的OOM或者卡顿情况变严重,相反,根据特定场景配置合理的内存缓存配置能够减少图片频繁的解码和内存申请,甚至可以带来OOM和ANR的优化。 图片解码优化:当内存缓存失败后,图片文件会进行解码,最终以bitmap形式在内存中存在,目前解码后的bitmap平均大小为800KB,90分位为5MB,99分位更是高达夸张的11MB,解码流程需要频繁申请内存,同时有超过15%的图片存在一倍尺寸的浪费,对客户端的性能影响非常大,因此如何减少解码阶段的内存申请是我们需要重点解决的问题。 磁盘缓存优化:尽管对比内存缓存命中率,磁盘缓存命中率只有10%,但理论上内存中的bitmap在磁盘中都有对应的原始文件存在,因此想要整体缓存命中率,我们更关注磁盘缓存的优化,需要通过合理的磁盘配置,让存储空间利用率更高。 网络加载优化:虽然网络阶段失败率高达2.5%,但经过数据排查和修复,实际失败率< 0.1%,优化空间不多,考虑到网络加载是整体流程耗时最长的,耗时占了近90%,其中主要影响为文件过大导致的加载耗时长,因此需要重点解决下发大文件问题,优化网络加载耗时。
优化过程
指标建设
在进行图片优化之前,需要对图片整体质量完成一次数据盘点,指标建设是至关重要的一步。通过建立指标系统,能够帮助我们了解图片现状、确定优化方向和评估优化后的效果。
BDFresco提供日志上报能力,上报的图片日志经过veImageX云端数据清洗,最终可以在veImageX云端控制台查看图片质量相关指标。从触发图片加载,到内存、解码、磁盘、网络各个阶段都建立了完备的数据监控体系,覆盖各阶段加载耗时、成功率、客户端和CDN缓存命中率、文件大小、内存占用、大图异常监控等几百项指标。
具体举措
1 内存缓存优化
1.1 内存查找优化
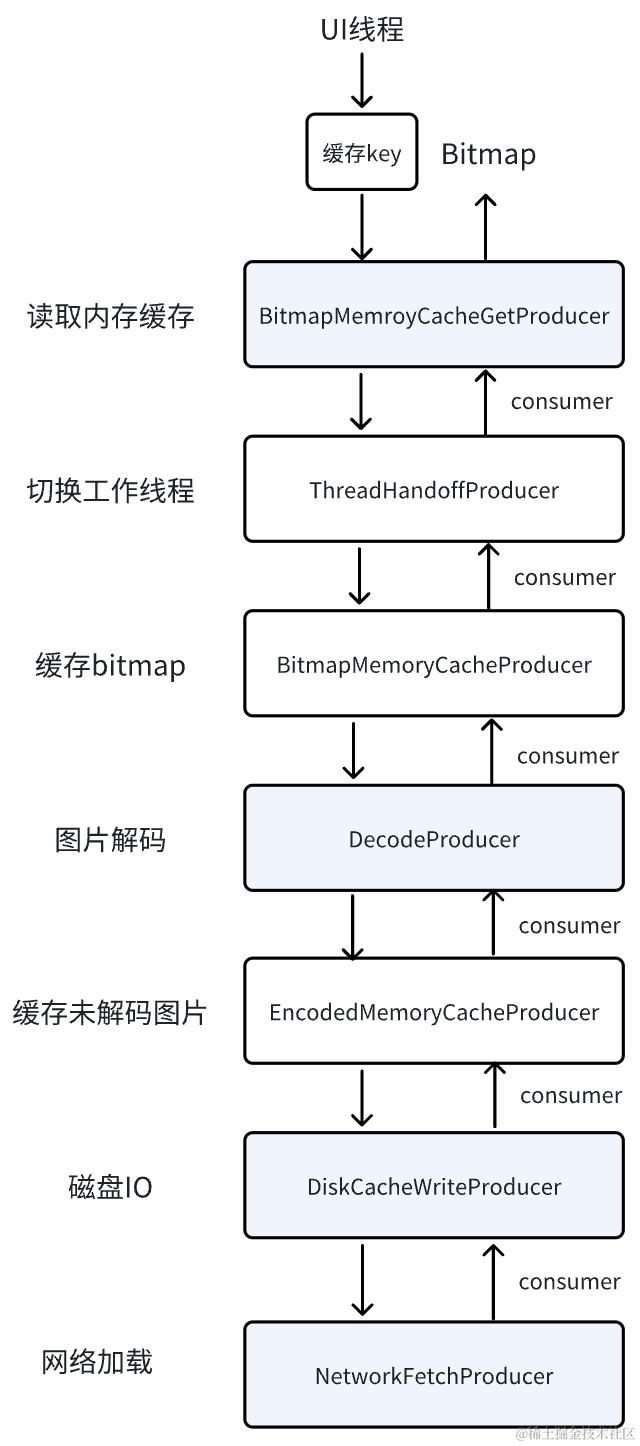
内存缓存原理
BDFresco是通过Producer/Consumer接口来实现图片加载的流程,例如网络数据获取、缓存数据获取、图片解码等多种工作,不同阶段由不同Producer实现类处理,所有的Producer都是一层嵌套一层,产生的结果由Consumer进行消费。一个简化后的图片内存缓存逻辑如下:
其中,读取内存或磁盘缓存是通过缓存key来进行匹配,缓存key是通过Uri做转换的,可以简单理解成cacheKey==uri,抖音在之前上线过一个缓存key优化的实验:对于同个资源的不同域名,会剔除host和query参数,即cacheKey被简化为scheme://path/name
优化方案
业务在进行图片加载时,BDFresco支持传入Uri数组,Uri均是同一资源,指向的是不同veImageX-CDN地址,实际上内部会将该批Uri(A-B-C)识别成同一个缓存key。
如下图所示,ABC3个Uri并不完全是按照【A全流程查找->B全流程查找->C全流程查找】的顺序执行,而是会先对ABC各进行一次内存缓存查找,再按顺序进行ABC的全流程查找。
由于ABC为同一资源,只是域名不同,在端上生成的缓存key一致,实际上的ABC各自的内存缓存查找为无效操作,由于该环节在UI线程执行,且抖音存在多图场景,一次滑动会触发多次图片加载逻辑,因此部分场景会导致卡顿丢帧等情况发生。
通过将多余的内存查找流程去除,对大盘帧率有明显提升。
1.2 动静图缓存拆分
抖音图片的内存缓存大小,是根据 java 堆内存大小来进行配置,默认大小为1/8,即32M或者64M。由于Android 8后,图片内存数据不再存储在java堆上,而是存在native堆,如果继续使用堆内存大小来进行图片内存缓存大小的配置是不合理的,因此通过将内存缓存大小*2,希望能减少解码操作,优化OOM和ANR指标。
实验后的稳定性指标显示,OOM虽然减少了,但是问题转换成了native崩溃和ANR都显著劣化,实验并不符合预期。
图片的缓存命中率和缓存大小成正相关,缓存大小越大,命中率越高,但随着缓存大小的增大,命中率提升空间会越来越小。
结合实验结果来看,单纯增大缓存大小会导致内存水位上升,引发ANR和native崩溃问题,方案并不可行。
目前动图和静图的内存缓存使用同一块缓存块,BDFresco的缓存管理是LRU的淘汰策略,如果播放动图帧数过多,很容易把静图缓存给替换掉,重新切换回来静图就需要重新解码,重新解码势必带来性能的损耗和用户体验的降低,抖音上存在较多此类场景,如IM、个人页动静图混搭场景。
同时,考虑到直接增大内存缓存大小,命中率提升的空间不高,所以尝试将动图和静图缓存做隔离,动静图各使用一块内存缓存,能够有效地提升命中率,减少解码操作。
最终实验收益:
抖音通过拆分动静图缓存,单块缓存大小不变,整体缓存增大,日活显著提升,OOM显著降低,大盘帧率显著正向。 抖极通过拆分动静图缓存,单块缓存大小变为1/2,整体缓存不变,日活显著提升,人均使用时长显著正向,OOM显著降低,大盘帧率显著正向。
2 图片解码优化
2.1 解码格式优化
单位像素占用的字节数由颜色模式Bitmap.Config决定,即ARGB 颜色通道,主要有6种类型:
ALPHA_8:只有一个alpha通道,8bit,每个像素占1Byte; ARGB_4444:包含红绿蓝alpha4个通道,每个通道4bit,每个像素占2Byte; ARGB_8888:包含红绿蓝alpha4个通道,每个通道8bit,每个像素占4Byte; RGB_565:包含红绿蓝3个通道,其中红色占5bit,绿色占6bit,蓝色占5bit,每个像素占2Byte; RGBA_F16:包含红绿蓝alpha4个通道,每个通道8bit,每个像素占4Byte; HARDWARE:ARGB_8888的特殊配置,Bitmap会直接存储在显存中。
目前抖音主要使用ARGB_8888和RGB_565两种配置,ARGB_8888支持透明通道,且颜色质量更高,RGB_565不支持透明通道,但整体内存占用少了一半,抖音的优化思路如下:
低端机默认使用RGB_565进行解码,减少内存占用。
抖音部分图片不携带透明通道,如所有的heic图,但业务指定为ARGB_8888,导致透明通道做无效占用,在内存上造成浪费,因此可以在解码阶段将不携带透明通道的图片强制降级为RGB_565,在牺牲一定程度的颜色质量下减少近一半的内存占用和解码性能损耗。
由于部分bitmap的操作如圆角、高斯模糊等依赖透明通道的渲染,若强制将无透明通道图片降级成565,可能会导致部分业务无法正常展示,因此需要针对这类业务进行加白处理。
2.2 heif解码内存优化
优化原理:
BDFresco中heic图解码原逻辑是通过jni调用解码器的解码接口,返回解码后像素数据,返回到java层再转换成Bitmap对象展示。原逻辑中存在使用超大临时对象问题,会导致java内存开销以及GC,优化后减少大对象创建,直接在native层完成Bitmap对象构建,预期减少heif图片解码耗时,提升一定流畅度。
将原有heif图片解码流程从:
优化为流程:
修复前:每个heic图片解码时使用两个大数组:
图片原始数据,大小为图片文件大小,一般在40K-700K之间 图片解码后数据:大小为图片宽高4,一般在1-11M之间
修复后: 无java层大数组使用,只使用一个40K-700K的native层的DirectByteBuffer数组。减少两个java层大数组创建,减少GC发生概率以及因为大数组创建导致的OOM问题,从而带来流畅度以及ANR收益。
在抖音上开实验,性能相关指标均有显著提升:java内存占用减少,heic解码耗时减少,Android ANR减少,从而显著提升图文的消费市场,带动了整体使用时长收益。
2.3 自适应控件解码
在前面,我们提到有超过15%的图片存在一倍尺寸的浪费,导致解码阶段需要申请大量的内存,最终展示在控件上并不需要这么大的bitmap,我们通过将图片尺寸resize至控件大小后进行解码,最终解码出小分辨率的Bitmap,能够将解码内存申请极致化。
但考虑到图片浪费主要是服务端下发过大的图片,单纯在解码阶段限制大小,无法解决网络阶段的大图片问题,带宽浪费和网络加载耗时长问题仍然没有解决,因此我们将该阶段做了前置迁移,在网络加载阶段进行优化,具体方案可看4.2节按需缩放方案。
3 磁盘缓存优化
通过优化客户端的磁盘缓存配置来提升缓存命中率,减少图片请求量级,在提升图片加载速度的情况下,也能降低图片带宽成本。
磁盘缓存分为3种:主磁盘、small磁盘、独立磁盘;各磁盘空间存在上限,采用LRU替换算法,目前抖音主要使用主磁盘和独立磁盘,整体流程如下:图片默认存储在主磁盘,图片被替换概率较高;若业务指定独立磁盘cacheName,则指定图片会单独使用一个磁盘,被替换概率低。
主磁盘存储空间增大:抖音Android端存储空间上限为40M,考虑到该值为fresco的默认值,配置值主要参考当年设备的存储空间,因此可以针对存储空间较多的设备,增加图片存储配置,提升磁盘缓存命中率。
实验结果表明:随着存储空间的增大,磁盘缓存命中率显著上涨,进一步带来图片量级的减少,当图片存储上限提升至80M时,Android大盘量级-5% 独立磁盘推广:针对复用率高的图片场景,推荐接入独立磁盘缓存,可以减少被其他业务图片LRU替换的几率,提升图片的磁盘缓存命中率。
以IM表情包为例,我们拉取IM业务的图片缓存命中率数据分析, 表情包命中率仅有7%,对比同样使用独立磁盘的IM普通图片的28%和个人页主态的31%,表情包磁盘命中率偏低。将IM表情包接入独立磁盘后,表情包请求量减少27%
4 网络加载优化
4.1 图片格式优化
常见图片格式
image:原图,未经过veImageX压缩处理。 JPEG:全称为Joint Photographic Experts Group(联合图像专家组),于1992发布,是一种有损压缩的光栅图像文件格式,压缩率越高图片质量越差,同时不支持透明通道。 PNG:全称为Portable Network Graphics(便携式网络图形),在1997年3月作为知识性RFC 2083发布,于2004年作为ISO/IEC标准发布,PNG也是一种栅格图形格式,但支持无损压缩,同时也支持携带透明通道信息。 WebP:是一种由谷歌开发的图片格式,于2010年发布,支持有损压缩和无损压缩图片文件格式,提供更高的压缩率和更快的加载速度。对比jpeg和png格式,在相同图片质量的情况下,文件体积能减少30%+,同时WebP 图片格式还支持透明通道和动画,目前抖音Android所有版本均支持Webp格式。 HEIC(BVC1):基于火山引擎自研BVC算法进行封装的图片(17项第一,火山自研编码器在MSU大赛多项夺冠[https://www.toutiao.com/article/6951287905268843011/?upstream_biz=doubao&source=m_redirect]),通常的文件后缀名为heic,对比Webp格式,在相同图片质量的情况下,文件体积能再减少30%+,带宽收益更加明显。但heic格式也存在缺点:由于高效编码会导致解码性能损耗略有增加,但体积较小也会带来网络耗时的降低,最终总的加载耗时基本打平或略有降低,目前抖音Android端已全量使用自研BVC软解实现解码。 vvic:字节基于 BVC2算法自研的图片格式,采用的是VVC的图片编码格式,又称BVC2编码格式,对比heic的BVC1压缩率更高。
heic格式推广
当前veImageX平台支持最好的是heic编码格式,但到22年初,抖音Android端覆盖率不足50%,直接通过提升业务的heic占比能够大幅减少带宽成本,提升图片加载速度。
JPEG->heic,大幅减少带宽成本80%以上,加载速度提升30%+ webp->heif,个人页动图平均文件大小-25.33%,加载速度提升30%+
在做heif动图实验推广时,发现个人页UI帧率存在大幅劣化,在高低端设备均有6-8帧的帧率下降,实验无法上线,针对该问题,我们对heif动图的解码缓存逻辑进行一次优化,提出了heif动图独立缓存优化方案。
heif动图独立缓存
动图原理
在图片文件下载完成解析成字节流,动图正式播放之前,BDFresco会进行预解码,当动图正式播放时,会根据动图调度器的播放顺序将Bitmap渲染到屏幕上,并且在播放过程中会主动预解码下一帧,如当前需要播放第5帧,会同步解码第6帧率。其中预解码操作均在子线程中进行。
不同调度器的核心区别为:当子线程预解码速度过慢,下一帧需要播放的Bitmap不存在时,是继续返回当前帧重复播放,等待子线程进行解码,还是返回下一帧,直接在主线程进行解码渲染。
SmoothSlidingFrameScheduler:默认调度器,在子线程预解码速度跟不上播放速度时,会降低动图的播放速度,如重复播放当前帧,保证不在主线程进行解码,会导致动图播放不流程,但对页面性能非常好,不会引起卡顿。 DropFramesFrameScheduler:严格按照图片的时间标准进行播放,若预解解码速度太慢,则直接在主线程进行解码,以保证对应帧能够在对应时间内进行解码并且渲染到屏幕上,缺点是会在主线程进行解码,可能会引起页面的卡顿。 自定义调度器:业务自定义实现getFrameNumberToRender接口,支持倒序播放、跳帧播放等特殊逻辑。
独立缓存
heif动图掉帧问题经过排查,发现heif动图采用了一个新的播放调度逻辑FixedSlidingHeifFrameScheduler:动图无任何预解码逻辑,在需要播放对应帧时,直接在主线程进行解码,即播放一帧解码一帧,这也导致了Heif动图在播放过程中需要在主线程占用大量CPU资源进行解码。
为什么heif动图必须在主线程解码呢?
对比其他动图支持任意帧解码,heif动图采用了帧间压缩的方式,引入了I帧P帧的概念,I帧为关键帧,包含了当前图像的完整信息,能够独立解码;P帧为差别帧,没有完整的画面数据,只有与前一帧的画面差别的数据,无法独立进行解码,解码需要依赖前一帧数据。
由于AndroidBDFresco的内存缓存为LRU替换,Bitmap随时有可能被回收,因此针对Heif动图的解码,必须严格按照动图顺序进行解码,否则会导致Heif动图播放过程中出现花屏绿屏等问题。
方案思考:
从源头解决,优化heif动图的编码解码逻辑,但目前Heif的帧结构就决定了解码器的解码逻辑,如果需要支持指定帧解码,就得改造Heif编码格式,方案不可行。
不在主线程进行解码,专门开一个子线程做heif动图的解码,主线程需要渲染某一帧的时候,就切到子线程去解码,解码完成通知主线程做渲染,但方案对BDFresco的解码流程改造较大,且不支持内存缓存,方案待定。
抖音Android&iOS双端共用一个解码器,但iOS实验并无帧率劣化,原因在于iOS的图片内存缓存是可控的,不会有不符合预期的缓存释放,因此Android端可以尝试借鉴该思路
给heif动图单独开辟一个新的内存缓存块,且对解码后的Bitmap进行强引用,即不会被动释放内容,也不会被其他图片LRU替换。方案优点在于能够完美复用老的解码逻辑,也支持子线程预解码,只需要将Bitmap单独缓存即可实现。 由于Bitmap是强引用,缓存块也无上限,方案存在内存无限增长的可能,因此需要有一个主动释放时机,即能减少内存占用,也能保证解码顺序不被影响。因此我们尝试关联view的detach方法,当动图控件在快速滑动时,会主动释放不可见View上对应的Bitmap。
经过实验,最终采取了独立缓存方案,在取得带宽收益的同时,个人页帧率无明显劣化。
4.2 按需缩放
背景
图片加载流程最终会将解码后的bitmap渲染在控件上,当bitmap大小大于控件时,实际对用户感官并无影响,图片最终展示的像素值不会超过控件占据的空间,当图片大小 >> 控件大小时:
造成一定程度的带宽浪费; 图片过大,客户端性能损耗严重; 不同业务对同一张图片进行图片裁剪,没有考虑图片尺寸碎片化问题,导致veImageX-CDN缓存命中率显著下降,最终造成回源成本的暴涨。
解决方案
在图片展示时上报对应的bitmap和控件大小,从上报的数据来看,存在大量业务请求的图片大小远大于控件。因此,需要采用一种通用的方案,在满足图片质量的前提下,客户端提供一套控件规范,根据控件大小将图片收敛至固定大小,保证图片尺寸和展示控件基本一致,同时减少图片碎片化问题。
个人页、同城、推荐等多个业务均存在双列封面场景,这里以双列封面为例子:
收益
视觉搜索场景文件大小 -83.39%,内存大小 -66.57% veImageX-CDN缓存命中率提升 + 6.99%,回源请求数减少 -23.79%
5 异常恢复
尽管前面我们对图片的加载流程做了一系列优化,但因为抖音本身图片量级大,部分业务如电商、IM等对图片清晰度有较高的要求,且存在图片放大和长图展示等操作,业务会进行超大图加载,直接将图片直接加载进内存,单张图片内存甚至高达100M+,无论在磁盘IO阶段,还是内存解码或者Bitmap拷贝过程中均会申请大量内存,最终导致卡顿、ANR甚至OOM崩溃,因此需要一套兜底方案来解决图片OOM频发问题,提升图片加载的可靠性。
抖音在系统内存触顶时,会通过释放图片内存来缓解压力:监听系统内存的告警回调,根据不同级别释放不同大小的图片内存缓存,降低发生OOM和ANR的几率,但因大图存在,仍然存在大量OOM。
OOM兜底
因此针对高频的图片解码和内存拷贝逻辑,增加兜底逻辑,当代码发生OOM,主动catch,并通过清除图片占用的内存缓存来释放部分内存,降低内存水位:
清除两级内存缓存,解码内存缓存+未解码内存缓存 清除接入层缓存的动图预览帧
实验结果表明,尽管部分OOM转换成native崩溃,但整体影响用户大幅下降,实验符合预期。
总结
总体来看,抖音在建设了图片的全链路监控后,根据数据分析对图片加载流程做了不少优化。
提升了图片加载速度和性能 减少了图片的总成本
从收益角度来看,大致可以分为成本优化和客户端体验优化两方面。成本收益主要是图片带宽成本的降低,体验收益体现在日活和OOM指标上,并且随着各种优化方案推广到更多的业务线,收益也在持续增加。
本文简要介绍了抖音基于BDFresco的图片优化最佳实践、经验沉淀、业务收益。由于篇幅所限,本文对探索历程、具体实现等细节内容有所省略,但仍希望能给业内同仁们一点启发或者参考借鉴。目前BDFresco已集成到火山引擎veImageX产品,对行业开放使用中,如需体验抖音同款图片优化能力,可以到火山引擎veImageX官网申请使用。
参考:火山引擎veImageX提供端到端一站式的整体图片解决方案,包含图片及素材托管、图像处理与压缩、分发、客户端编解码及图片加载SDK全链路能力,官网地址:https://www.volcengine.com/product/imagex
如有侵权请联系:admin#unsafe.sh