2024-6-15 04:49:37 Author: securityboulevard.com(查看原文) 阅读量:5 收藏
By Artem Dinaburg
Earlier this week, at Apple’s WWDC, we finally witnessed Apple’s AI strategy. The videos and live demos were accompanied by two long-form releases: Apple’s Private Cloud Compute and Apple’s On-Device and Server Foundations Models. This blog post is about the latter.
So, what is Apple releasing, and how does it compare to the current open-source ecosystem? We integrate the video and long-form releases and parse through the marketing speak to bring you the nuggets of information within.
The sound of silence
No NVIDIA/CUDA Tax. What’s unsaid is as important as what is, and those words are CUDA and NVIDIA. Apple goes out of its way to specify that it is not dependent on NVIDIA hardware or CUDA APIs for anything. The training uses Apple’s AXLearn (which runs on TPUs and Apple Silicon), Server model inference runs on Apple Silicon (!), and the on-device APIs are CoreML and Metal.
Why? Apple hates NVIDIA with the heat of a thousand suns. Tim Cook would rather sit in a data center and do matrix multiplication with an abacus than spend millions on NVIDIA hardware. Aside from personal enmity, it is a good business idea. Apple has its own ML stack from the hardware on up and is not hobbled by GPU supply shortages. Apple also gets to dogfood its hardware and software for ML tasks, ensuring that it’s something ML developers want.


What’s the downside? Apple’s hardware and software ML engineers must learn new frameworks and may accidentally repeat prior mistakes. For example, Apple devices were originally vulnerable to LeftoverLocals, but NVIDIA devices were not. If anyone from Apple is reading this, we’d love to audit AXLearn, MLX, and anything else you have cooking! Our interests are in the intersection of ML, program analysis, and application security, and your frameworks pique our interest.
The models
There are (at least) five models being released. Let’s count them:
- The ~3B parameter on-device model used for language tasks like summarization and Writing Tools.
- The large Server model is used for language tasks too complex to do on-device.
- The small on-device code model built into XCode used for Swift code completion.
- The large Server code model (“Swift Assist”) that is used for complex code generation and understanding tasks.
- The diffusion model powering Genmoji and Image Playground.
There may be more; these aren’t explicitly stated but plausible: a re-ranking model for working with Semantic Search and a model for instruction following that will use app intents (although this could just be the normal on-device model).
The ~3B parameter on-device model. Apple devices are getting an approximately 3B parameter on-device language model trained on web crawl and synthetic data and specially tuned for instruction following. The model is similar in size to Microsoft’s Phi-3-mini (3.8B parameters) and Google’s Gemini Nano-2 (3.25B parameters). The on-device model will be continually updated and pushed to devices as Apple trains it with new data.
What model is it? A reasonable guess is a derivative of Apple’s OpenELM. The parameter count fits (3B), the training data is similar, and there is extensive discussion of LoRA and DoRA support in the paper, which only makes sense if you’re planning a system like Apple has deployed. It is almost certainly not directly OpenELM since the vocabulary sizes do not match and OpenELM has not undergone safety tuning.
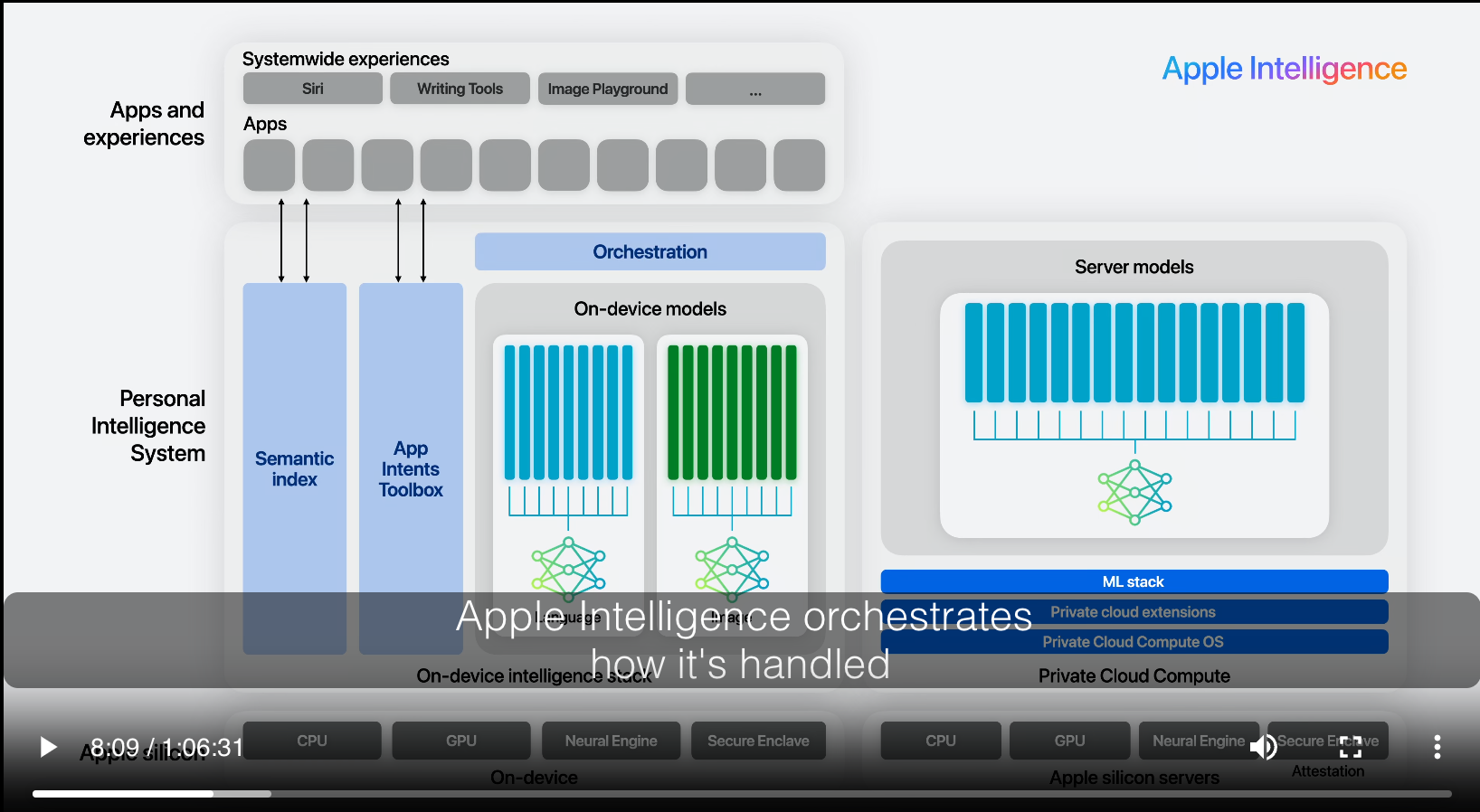
Apple’s on-device and server model architectures.
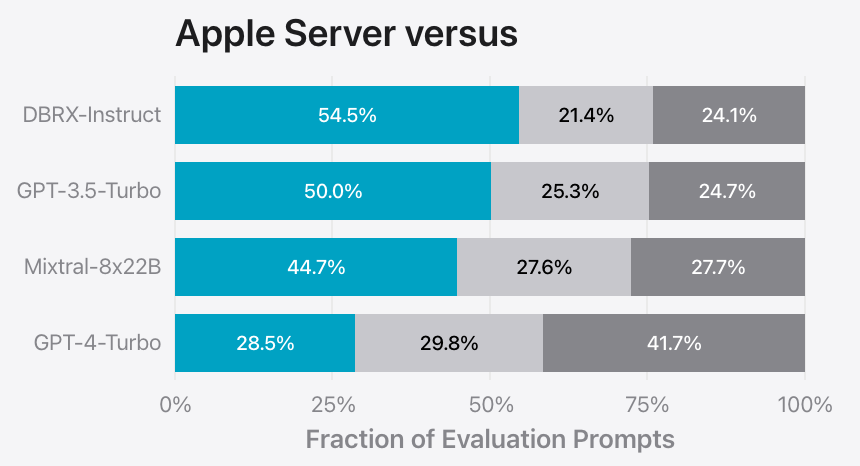
A large (we’re guessing 130B-180B) Mixture-of-Experts Server model. For tasks that can’t be completed on a device, there is a large model running on Apple Silicon Servers in their Private Compute Cloud. This model is similar in size and capability to GPT-3.5 and is likely implemented as a Mixture-of-Experts. Why are we so confident about the size and MoE architecture? The open-source comparison models in cited benchmarks (DBRX, Mixtral) are MoE and approximately of that size; it’s too much for a mere coincidence.

Apple’s Server model compared to open source alternatives and the GPT series from OpenAI.
The on-device code model is cited in the platform state of the union; several examples of Github Copilot-like behavior integrated into XCode are shown. There are no specifics about the model, but a reasonable guess would be a 2B-7B code model fine-tuned for a specific task: fill-in-middle for Swift. The model is trained on Swift code and Apple SDKs (likely both code and documentation). From the demo video, the integration into XCode looks well done; XCode gathers local symbols and proper context for the model to better predict the correct text.
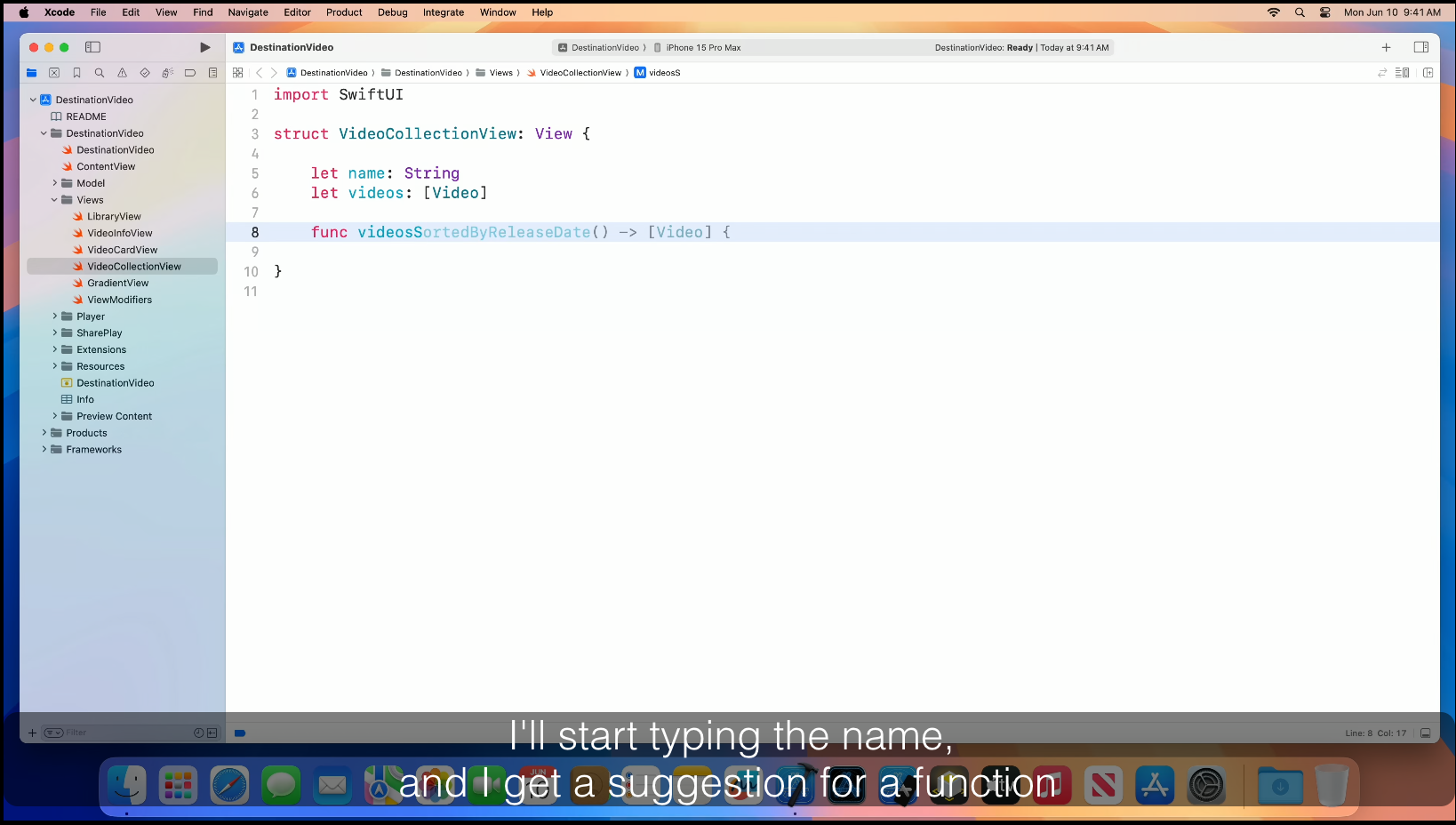
Apple’s on-device code model doing FIM completions for Swift code via XCode.
The server code model is branded as “Swift Assist” and also appears in the platform state of the union. It looks to be Apple’s answer to GitHub Copilot Chat. Not much detail is given regarding the model, but looking at its demo output, we guess it’s a 70B+ parameter model specifically trained on Swift Code, SDKs, and documentation. It is probably fine-tuned for instruction following and code generation tasks using human-created and synthetically generated data. Again, there is tight integration with XCode regarding providing relevant context to the model; the video mentions automatically identifying and using image and audio assets present in the project.

Swift Assist completing a description to code generation task, integrated into XCode.
The Image Diffusion Model. This model is discussed in the Platforms State of the Union and implicitly shown via Genmoji and Image Playground features. Apple has considerable published work on image models, more so than language models (compare the amount of each model type on Apple’s HF page). Judging by their architecture slide, there is a base model with a selection of adapters to provide fine-grained control over the exact image style desired.
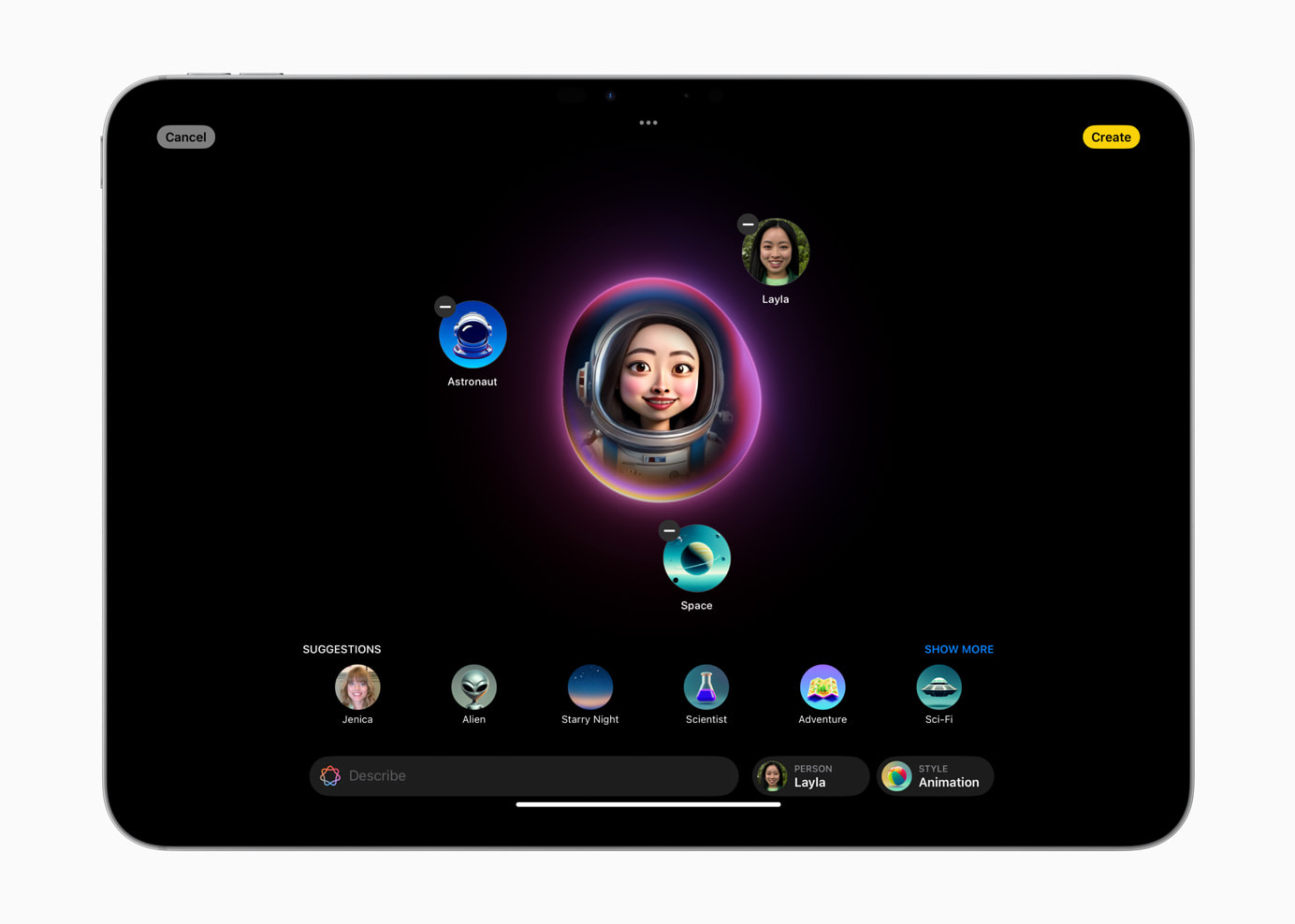
Image Playground showing the image diffusion model and styling via adapters.
Adapters: LoRAs (and DoRAs) galore
The on-device models will come with a set of LoRAs and/or DoRAs (Adapters, in Apple parlance) that specialize the on-device model to be very good at specific tasks. What’s an adapter? It’s effectively a diff against the original model weights that makes the model good at a specific task (and conversely, worse at general tasks). Since adapters do not have to modify every weight to be effective, they can be small (10s of megabytes) compared to a full model (multiple gigabytes). Adapters can also be dynamically added or removed from a base model, and multiple adapters can stack onto each other (e.g., imagine stacking Mail Replies + Friendly Tone).
For Apple, shipping a base model and adapters makes perfect sense: the extra cost of shipping adapters is low, and due to complete control of the OS and APIs, Apple has an extremely good idea of the actual task you want to accomplish at any given time. Apple promises continued updates of adapters as new training data is available and we imagine new adapters can fill specific action niches as needed.
Some technical details: Apple says their adapters modify multiple layers (likely equivalent to setting target_modules=”all-linear” in HF’s transformers). Adapter rank determines how strong an effect it has against the base model; conversely, higher-rank adapters take up more space since they modify more weights. At rank=16 (which from a vibes/feel standpoint is a reasonable compromise between effect and adapter size), the adapters take up 10s of megabytes each (as compared to gigabytes for a 3B base model) and are kept in some kind of warm cache to optimize for responsiveness.
Suppose you’d like to learn more about adapters (the fundamental technology, not Apple’s specific implementation) right now. In that case, you can try via Apple-native MLX examples or HF’s transformers and PEFT packages.

A selection of Apple’s language model adapters.
A vector database?
Apple doesn’t explicitly state this, but there’s a strong implication that Siri’s semantic search feature is a vector database; there’s an explicit comparison that shows Siri now searches based on meaning instead of keywords. Apple allows application data to be indexed, and the index is multimodal (images, text, video). A local application can provide signals (such as last accessed time) to the ranking model used to sort search results.

Siri now searches by semantic meaning, which may imply there is a vector database underneath.
Delving into technical details
Training and data
Let’s talk about some of the training techniques described. They are all ways to parallelize training very large language models. In essence, these techniques are different means to split & replicate the model to train it using an enormous amount of compute and data. Below is a quick explanation of the techniques used, all of which seem standard for training such large models:
- Data Parallelism: Each GPU has a copy of the full model but is assigned a chunk of the training data. The gradients from all GPUs are aggregated and used to update weights, which are synchronized across models.
- Tensor Parallelism: Specific parts of the model are split across multiple GPUs. PyTorch docs say you will need this once you have a big model or GPU communication overhead becomes an issue.
- Sequence Parallelism was the hardest topic to find; I had to dig to page 6 of this paper. Parts of the transformer can be split to process multiple data items at once.
- FSDP shards your model across multiple GPUs or even CPUs. Sharding reduces peak GPU memory usage since the whole model does not have to be kept in memory, at the expense of communication overhead to synchronize state. FDSP is supported by PyTorch and is regularly used for finetuning large models.
Surprise! Apple has also crawled the web for training with AppleBot. A raw crawl naturally contains a lot of garbage, sensitive data, and PII, which must be filtered before training. Ensuring data quality is hard work! HuggingFace has a great blog post about what was needed to improve the quality of their web crawl, FineWeb. Apple had to do something similar to filter out their crawl garbage.
Apple also has licensed training data. Who the data partners are is not mentioned. Paying for high-quality data seems to be the new normal, with large tech companies striking deals with big content providers (e.g., StackOverflow, Reddit, NewsCorp).
Apple also uses synthetic data generation, which is also fairly standard practice. However, it begs the question: How does Apple generate the synthetic data? Perhaps the partnership with OpenAI lets them legally launder GPT-4 output. While synthetic data can do wonders, it is not without its downside—there are forgetfulness issues with training on a large synthetic data corpus.
Optimization
This section describes how Apple optimizes its device and server models to be smaller and enable faster inference on devices with limited resources. Many of these optimizations are well known and already present in other software, but it’s great to see this level of detail about what optimizations are applied in production LLMs.
Let’s start with the basics. Apple’s models use GQA (another match with OpenELM). They share vocabulary embedding tables, which implies that some embedding layers are shared between the input and the output to save memory. The on-device model has a 49K token vocabulary (a key difference from OpenELM). The hosted model has a 100K token vocabulary, with special tokens for language and “technical tokens.” The model vocabulary means how many letters and short sequences of words (or tokens) the model recognizes as unique. Some tokens are also used for signaling special states to the model, for instance, the end of the prompt, a request to fill in the middle, a new file being processed, etc. A large vocabulary makes it easier for the model to understand certain concepts and specific tasks. As a comparison, Phi-3 has a vocabulary size of 32K, Llama3 has a vocabulary of 128K tokens, and Qwen2 has a vocabulary of 152K tokens. The downside of a large vocabulary is that it results in more training and inference time overhead.
Quantization & palletization
The models are compressed via palletization and quantization to 3.5 bits-per-weight (BPW) but “achieve the same accuracy as uncompressed models.” What does “achieve the same accuracy” mean? Likely, it refers to an acceptable quantization loss. Below is a graph from a PR to llama.cpp with state-of-the-art quantization losses for different techniques as of February 2024. We are not told what Apple’s acceptable loss is, but it’s doubtful a 3.5 BPW compression will have zero loss versus a 16-bit float base model. Using “same accuracy” seems misleading, but I’d love to be proven wrong. Compression also affects metrics beyond accuracy, so the model’s ability may be degraded in ways not easily captured by benchmarks.
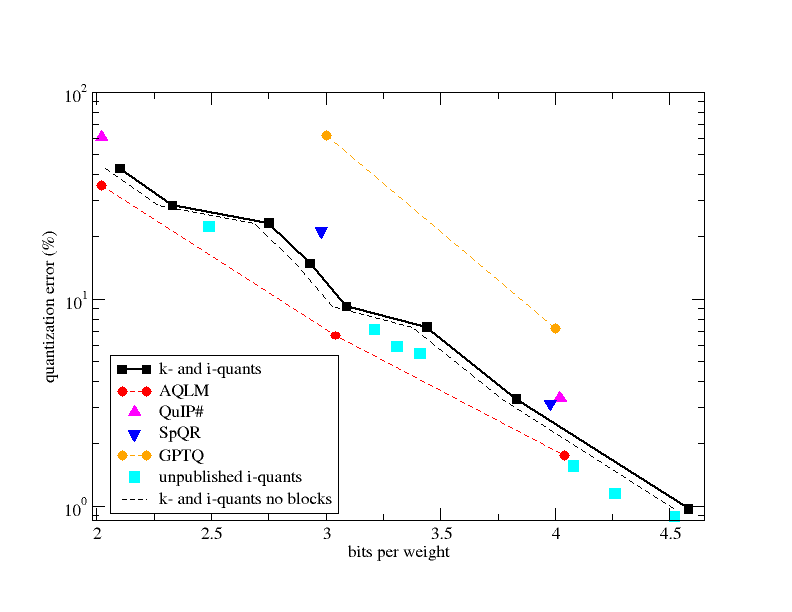
Quantization error compared with bits per weight, from a PR to llama.cpp. The loss at 3.5 BPW is noticeably not zero.
What is Low Bit Palletization? It’s one of Apple’s compression strategies, described in their CoreML documentation. The easiest way to understand it is to use its namesake, image color pallets. An uncompressed image stores the color values of each pixel. A simple optimization is to select some number of colors (say, 16) that are most common to the image. The image can then be encoded as indexes into the color palette and 16 full-color values. Imagine the same technique applied to model weights instead of pixels, and you get palletization. How good is it? Apple publishes some results for the effectiveness of 2-bit and 4-bit palletization. The two-bit palletization looks to provide ~6-7x compression from float16, and 4-bit compression measures out at ~3-4x, with only a slight latency penalty. We can ballpark and assume the 3.5 BPW will compress ~5-6x from the original 16-bit-per-weight model.

Palletization graphic from Apple’s CoreML documentation. Note the similarity to images and color pallets.
Palletization only applies to model weights; when performing inference, a source of substantial memory usage is runtime state. Activations are the outputs of neurons after applying some kind of transformation function, storing these in deep models can take up a considerable amount of memory, and quantizing them is a way to fit a bigger model for inference. What is quantization? It’s a way to map intervals of a large range (like 16 bits) into a smaller range (like 4 or 8 bits). There is a great graphical demonstration in this WWDC 2024 video.
Quantization is also applied to embedding layers. Embeddings map inputs (such as words or images) into a vector that the ML model can utilize. The amount/size of embeddings depends on the vocabulary size, which we saw was 49K tokens for on-device models. Again, quantizing this lets us fit a bigger model into less memory at the cost of accuracy.
How does Apple do quantization? The CoreML docs reveal the algorithms are GPTQ and QAT.
Faster inference
The first optimization is caching previously computed values via the KV Cache. LLMs are next-token predictors; they always generate one token at a time. Repeated recomputation of all prior tokens through the model naturally involves much duplicate effort, which can be saved by caching previous results! That’s what the KV cache does. As a reminder, cache management is one of the two hard problems of computer science. KV caching is a standard technique implemented in HF’s transformers package, llama.cpp, and likely all other open-source inference solutions.
Apple promises a time-to-first-token of 0.6ms per prompt token and an inference speed of 30 tokens per second (before other optimizations like token speculation) on an iPhone 15. How does this compare to current open-source models? Let’s run some quick benchmarks!
On an M3 Max Macbook Pro, phi3-mini-4k quantized as Q4_K (about 4.5 BPW) has a time-to-first-token of about 1ms/prompt token and generates about 75 tokens/second (see below).

Apple’s 40% latency reduction on time-to-first-token on less powerful hardware is a big achievement. For token generation, llama.cpp does ~75 tokens/second, but again, this is on an M3 Max Macbook Pro and not an iPhone 15.
The speed of 30 tokens per second doesn’t provide much of an anchor to most readers; the important part is that it’s much faster than reading speed, so you aren’t sitting around waiting for the model to generate things. But this is just the starting speed. Apple also promises to deploy token speculation, a technique where a slower model guides how to get better output from a larger model. Judging by the comments in the PR that implemented this in llama.cpp, speculation provides 2-3x speedup over normal inference, so real speeds seen by consumers may be closer to 60 tokens per second.
Benchmarks and marketing
There’s a lot of good and bad in Apple’s reported benchmarks. The models are clearly well done, but some of the marketing seems to focus on higher numbers rather than fair comparisons. To start with a positive note, Apple evaluated its models on human preference. This takes a lot of work and money but provides the most useful results.
Now, the bad: a few benchmarks are not exactly apples-to-apples (pun intended). For example, the graph comparing human satisfaction summarization compares Apple’s on-device model + adapter against a base model Phi-3-mini. While the on-device + adapter performance is indeed what a user would see, a fair comparison would have been Apple’s on-device model + adapter vs. Phi-3-mini + a similar adapter. Apple could have easily done this, but they didn’t.

A benchmark comparing an Apple model + adapter to a base Phi-3-mini. A fairer comparison would be against Phi-3-mini + adapter.
The “Human Evaluation of Output Harmfulness” and “Human Preference Evaluation on Safety Prompts” show that Apple is very concerned about the kind of content its model generates. Again, the comparison is not exactly apples-to-apples: Mistral 7B was specifically released without a moderation mechanism (see the note at the bottom). However, the other models are fair game, as Phi-3-mini and Gemma claim extensive model safety procedures.
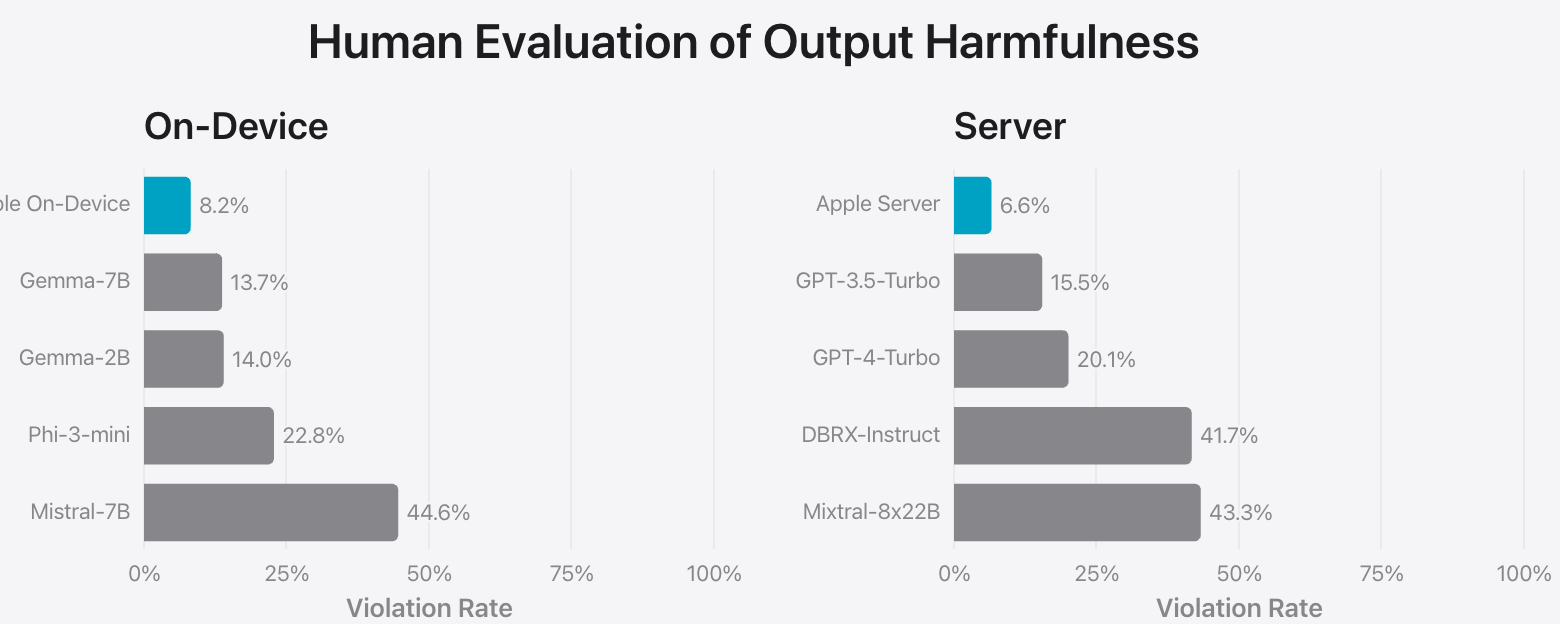
Mistral-7B does so poorly because it is explicitly not trained for harmfulness reduction, unlike the other competitors, which are fair game.
Another clip from one of the WWDC videos really stuck with us. In it, it is implied that macOS Sequoia delivers large ML performance gains over macOS Sonoma. However, the comparison is really a full-weight float16 model versus a quantized model, and the performance gains are due to quantization.

The small print shows full weights vs. 4-bit quantization, but the big print makes it seem like macOS Sonoma versus macOS Sequoia.
The rest of the benchmarks show impressive results in instruction following, composition, and summarization and are properly done by comparing base models to base models. These benchmarks correspond to high-level tasks like composing app actions to achieve a complex task (instruction following), drafting messages or emails (composition), and quickly identifying important parts of large documents (summarization).
A commitment to on-device processing and vertical integration
Overall, Apple delivered a very impressive keynote from a UI/UX perspective and in terms of features immediately useful to end-users. The technical data release is not complete, but it is quite good for a company as secretive as Apple. Apple also emphasizes that complete vertical integration allows them to use AI to create a better device experience, which helps the end user.
Finally, an important part of Apple’s presentation that we had not touched on until now is its overall commitment to maintaining as much AI on-device as possible and ensuring data privacy in the cloud. This speaks to Apple’s overall position that you are the customer, not the product.
If you enjoyed this synthesis of Apple’s machine learning release, consider what we can do for your machine learning environment! We specialize in difficult, multidisciplinary problems that combine application and ML security. Please contact us to know more.
*** This is a Security Bloggers Network syndicated blog from Trail of Bits Blog authored by Trail of Bits. Read the original post at: https://blog.trailofbits.com/2024/06/14/understanding-apples-on-device-and-server-foundations-model-release/
如有侵权请联系:admin#unsafe.sh