2024-6-22 08:30:38 Author: hackernoon.com(查看原文) 阅读量:5 收藏
This guide aims to equip you with fundamental insights and practices to ensure you can monitor and troubleshoot your services more effectively.
In application development, logging is often overlooked, but it's a crucial component of building a robust and observable system. Proper logging practices can enhance the visibility of your application, deepen your understanding of its inner workings, and improve overall application health.
Default Logging
Incorporating default logging mechanisms at your application’s entry points is highly beneficial. This automatic logging can capture essential interactions and potentially include the entry point’s arguments. However, it’s crucial to be cautious as logging sensitive information like passwords could pose privacy and security risks.
Common Entry Points
- API Endpoints: Log details about incoming requests and responses
- Background Jobs: Log job start points, execution details, and results
- Async Events: Log the handling of asynchronous events and related interactions
Comprehensive Logging
Every significant action your application takes must produce a log entry, particularly those actions that alter its state. This exhaustive logging approach is key to swiftly identifying and addressing issues when they arise, offering a transparent view into the health and functionality of your application. Such diligence in logging ensures easier diagnosis and maintenance.
Choosing the Appropriate Log Level
Adopting appropriate log levels is crucial for managing and interpreting the vast amount of data generated by your application. By categorizing logs based on their severity and relevance, you ensure critical issues are promptly identified and addressed, while less urgent information remains accessible without overwhelming your monitoring efforts.
Below is a guideline for utilizing log levels effectively:
|
Level |
Description & Examples |
Accepted Use |
Not Accepted |
|---|---|---|---|
|
|
Fatal events that stop system operations. e.g., Lost database connection |
Critical system errors |
Non-critical errors, like failed user login attempts |
|
|
There is a problem but the system can continue execution and complete the requested operation |
Potential issues leading to problems |
Routine state changes |
|
|
Insights into normal application functions, like user account creation or data writing |
State changes |
Read-only operations without changes |
|
|
Detailed diagnostic information, such as process start/end |
Logging process steps do not alter the system state |
Routine state changes or high-frequency operations |
|
|
The most detailed level, including method entries/exits |
Understanding the flow and details of a process |
Logging sensitive information |
What IDs to Log - Hierarchical Approach
When logging actions in your application, including the IDs of entities directly involved is crucial for linking log information to database data. A hierarchical approach helps you quickly find all logs connected to a specific part of your application by linking items to their parent groups or categories.
For example, instead of logging only the ID of a chat when a message fails to send, you should also log the IDs of the chat room and the company it belongs to. This way, you gain more context and can see the broader impact of the issue.
Example Log Entry:
Failed to send the message - chat=$roomId, chatRoomId=chatRoomId, company=$companyId
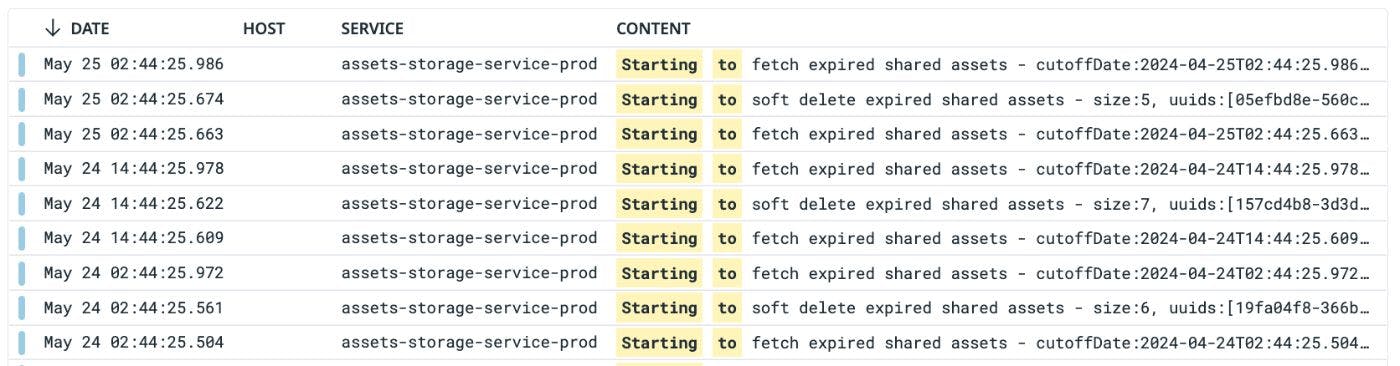
Example of Production Logs
Below is an example of how production logs might look when using the hierarchical approach:

Consistency and Standardization
Standard Prefixes
Standardizing log formats across all teams can make your logs much easier to read and understand. Here are some standardized prefixes to consider:
- Starting to do something
- Failed to do something
- Completed doing something
- Skipped doing something
- Retry doing something
Log Variable Values Separately
Separating variable names and values from the body of log messages offers several advantages:
- Simplifies Log Searching and Parsing: Makes it easier to filter and find specific information
- Streamlines Log Message Creation: Keeps the process of writing log messages straightforward
- Prevents Message Clutter: Large values won't disrupt the readability of the log message
Example Log Format:
Log message - valueName=value
Examples of Logs that Use Proposed Practices
Theoretical Example
Here are examples of well-structured log entries following the best practices discussed:
2023-10-05 14:32:01 [INFO] Successful login attempt - userId=24543, teamId=1321312
2023-10-05 14:33:17 [WARN] Failed login attempt - userId=536435, teamId=1321312
These examples demonstrate:
- Standardized Log Prefixes: Clear, consistent prefixes like "Successful login attempt" and "Failed login attempt" make the logs easy to understand.
- Separated Variable Values: Variable names and values are separated from the log message, maintaining clarity and simplifying searches.
- Readability and Consistency: The structured format ensures logs are easy to read and parse, aiding in efficient troubleshooting and monitoring.
Example of Production Logs
Below is an example of how production logs might look when using the proposed practices:

Trace IDs
To effectively associate logs with a specific user action, it's crucial to include a traceId or as it is also called correlationId in your logs. The ID should remain consistent across all logs generated by logic triggered by that entry point, offering a clear view of the sequence of events.
Implementation Example
While some monitoring services like Datadog provide log grouping out of the box, this can also be implemented manually. In a Kotlin application using Spring, you can implement a trace ID for REST requests using a HandlerInterceptor.
@Component
class TraceIdInterceptor : HandlerInterceptor {
companion object {
private const val TRACE_ID = "traceId"
}
override fun preHandle(request: HttpServletRequest, response: HttpServletResponse, handler: Any): Boolean {
val traceId = UUID.randomUUID().toString()
MDC.put(TRACE_ID, traceId)
return true
}
override fun afterCompletion(request: HttpServletRequest, response: HttpServletResponse, handler: Any, ex: Exception?) {
MDC.remove(TRACE_ID)
}
}
This interceptor generates a unique traceId for each request, adding it to the MDC at the beginning of the request and removing it after the request is completed.
Example Logs With traceId
Implementing such log aggregation will enable you to filter logs similar to the example below

Using UUID vs Long IDs in Logs
In many systems, entities may use either UUID or Long IDs as their primary identifiers, while some systems might use both types of IDs for different purposes. Understanding the implications of each type for logging purposes is crucial to make an informed choice.
Here’s a breakdown of things to consider:
Readability: Long IDs are easier to read and considerably shorter, especially if they are not on the high end of the Long range.
Unique Value: UUID IDs provide uniqueness across the system, enabling you to search for logs using an ID without facing issues of ID collisions. Collisions here mean that there is a chance that 2 entities from unrelated DB tables would have the same Long ID.
System Limitations: In systems that use Long primary keys as an entities IDs, adding a random UUID ID is usually straightforward, in a distributed system with UUID entity IDs it could be challenging or costly to have Long IDs specifically for logging.
Existing Logs: Consistency in the type of IDs used in logs is critical, at least per entity. If the system already produces logs for some entities and you aren't considering changing all of them, it's better to stick with the type already used to identify the entity. Logging both IDs can be considered during a transition period, but having multiple IDs permanently will unnecessarily clutter logs.
Conclusion
Proper logging practices are essential for effective service observability. By incorporating comprehensive logging, appropriate log levels, trace IDs, and standardized log formats, you can significantly enhance your ability to monitor and troubleshoot your applications. These practices improve the clarity and consistency of your logs, making it easier to diagnose and resolve issues quickly.
Thank you for taking the time to read this post!
如有侵权请联系:admin#unsafe.sh