2024-6-27 06:0:13 Author: hackernoon.com(查看原文) 阅读量:4 收藏
Authors:
(1) ZHIYUAN WEI, Beijing Institute of Technology, China;
(2) JING SUN, University of Auckland, New Zealand);
(3) ZIJIAN ZHANG, XIANHAO ZHANG, XIAOXUAN YANG, and LIEHUANG ZHU, Beijing Institute of Technology, China;
(4) XIANHAO ZHANG, Beijing Institute of Technology, China;
(5) XIAOXUAN YANG, Beijing Institute of Technology, China;
(6) LIEHUANG ZHU, Beijing Institute of Technology, China.
Table of Links
Overview of Smart Contracts and Survey Methodology
Vulnerability in Smart Contracts
Conclusions, Acknowledgement and References
6 EVALUATION
Our objective is to provide a comprehensive overview of the state-of-the-art automated analysis tools available for smart contracts. Given that the field of smart contract analysis is relatively new and rapidly evolving, it can be challenging to stay updated with the latest developments and understand the strengths and limitations of existing tools. Therefore, we have conducted an extensive review of the literature and websites to compile a list of the most promising analysis tools for smart contracts. Additionally, to address RQ4 and RQ5, which focus on evaluating the performance of existing tools, we propose a systematic evaluation approach that involves selecting appropriate tools, utilizing datasets of smart contracts, defining criteria for the assessment, and conducting experiments.
6.1 Experimental Setup
6.1.1 Tool Selection. Vulnerability-detecting tools are the most widely used method to assist developers in discovering security vulnerabilities in smart contracts. A wide range of analysis tools has been developed for this purpose, and we have compiled a list of 82 such tools based on academic literature and internet sources. Table in https://sites.google. com/view/sc-analysis-toollist presents the list of tools, along with key properties such as venue, methodology, input object, open-source link, and vulnerability ID. However, despite the abundance of vulnerability-finding tools, only a few papers have proposed a systematic approach to evaluate their effectiveness [45, 55]. To address this gap and answer RQ5, we adopted the four selection criteria below proposed by Durieux et al. [45].
C1: [Available] The tool must be publicly available and accessible for download or installation with a command line interface (CLI).
C2: [Funcctionality] The tool must be designed especially for smart contracts and must have the ability and detect vulnerabilities. This excludes constructing artifacts like control flow graphs.
C3: [Compatibility] The tool must be the source code of the smart contract. That excludes tools that only consider EVM bytecode.
C4: [Documentation] The tool must provide comprehensive documentation and user guides.
These criteria were utilized to filter our list of tools, resulting in the identification of 12 tools that meet the requirements: ConFuzzius [37], Conkas [92], Maian [68], Manticore [131], Mythril [44], Osiris [36], Oyente [48], Securify [50], sfuzz [112], Slither [41], Smartcheck [115], and solhint [102].
6.1.2 Dataset Construction. One important issue when evaluating analysis tools is how to obtain a sufficient number of vulnerable smart contracts. Although there are many open-source analysis tools available, comparing and reproducing them can be challenging due to the lack of publicly available datasets. Most analysis tools primarily check or detect only some of the well-known Ethereum smart contract vulnerabilities. To evaluate the effectiveness of any analysis tool, it is crucial to establish a standard benchmark. While several researchers have published their datasets (Durieux et al., 2020; Ghaleb et al., 2020; ConFuzzius), these datasets have limitations such as small sample sizes or an uneven distribution of vulnerable contracts. To address this limitation and partially answer RQ5, we created an annotated dataset consisting of 110 contract test cases. These cases are divided into 11 sub-datasets, with 10 sub-datasets containing known vulnerabilities corresponding to the top 10 categories mentioned in Section 3, and one sub-dataset representing correct contracts. These contracts vary in code sizes and encompass a wide range of applications. We have made our benchmark publicly available on GitHub: https://github.com/bit-smartcontract-analysis/smartcontract-benchmark.
6.1.3 Hardware Configuration. We obtained the most recent versions of the selected analysis tools from their respective public GitHub repositories, except for version 0.3.4 of the Manticore tool. The tools were executed on a 64-bit Ubuntu 18.04.5 LTS machine with 32 GB of memory and an Intel(R) Core(TM) i5-13400 CPU (6 cores clocked at 4.4 GHz). To address RQ4, we evaluated the effectiveness of each tool in terms of accuracy, performance, solidity version, and category coverage
6.2 Experimental Results
6.2.1 Accuarcy. We first measure the accuracy of the selected tools in finding vulnerabilities. There is currently no widely accepted standard or systematic method to evaluate the accuracy of analysis tools for smart contracts in finding security vulnerabilities. We test the selected tools on our benchmark, and the results are summarized in Table 1. This table presents an overview of the strengths and weaknesses of the selected tools across the Top 10 categories in Section 3. Each tool is represented as a column, while the different vulnerability categories are listed as rows. The numbers in each cell show the number of true positives identified by each tool for each vulnerability category. The format used to report the results is “x/y", where x is the number of vulnerabilities correctly detected and y is the total number of cases tested for that category. It is notable that none of the tested tools was able to identify all categories of vulnerabilities. Mythril and ConFuzzius outperformed the other tools by detecting 8 categories of vulnerabilities among all the tools.
Table 1 shows that different tools perform better at identifying certain vulnerability categories than others. For example, Conkas and Slither perform well in detecting reentrancy vulnerabilities, while Smartcheck excels at identifying time manipulation issues. The table provides valuable information for developers and security analysts in selecting the most effective tools for detecting specific types of vulnerabilities in smart contracts.
The last row of Table 1 shows the total number of true positives detected by each tool out of a total of 100 test cases. This data gives an insight into the accuracy of each tool’s performance in identifying Top 10 categories. Mythril has the highest total number of 54 true positives, while Conkas has a high number of 44 true positives and ConFuzzius has 42 true positives. The interesting thing is that all the top 3 tools combine different analysis methods. For example, Mythril uses symbolic execution, SMT calculation, and taint analysis. The combination of different analysis methods can lead to a more effective analysis, as it can leverage the strengths of each method to overcome their respective weaknesses.

Table 2 displays the accuracy of each tool by calculating the number of true positives and false negatives in each vulnerability category. The first row lists the selected tools, and each subsequent row shows the true positives and false negatives for each tool in that category. We obtained the false negatives from 10 correct test cases. The last row presents the accuracy of each tool, which is calculated as the ratio of the total number of true positives to the sum of true positives and false positives. For example, ConFuzzius has 42 true positives out of 100 test cases, and it also has 7 false negatives out of 10 test cases. Therefore, its accuracy is calculated as (42+7)/(100+10)=45%. It is evident from the table that Mythril outperforms the other tools in terms of correctly identifying vulnerabilities in the tested smart contracts with an accuracy of 58%.

6.2.2 Performance. Execution time is another crucial factor to consider when evaluating the effectiveness of a tool because the longer it takes for a tool to run, the less efficient it is in terms of time. To assess performance, we calculated the execution time for each tool, including the average time and total time, as indicated in Table 3. The total time represents the cumulative execution time for all the test processes, while the average time is obtained by dividing the total time by the number of successful test cases. It is important to note that unsuccessful test cases have been excluded from the calculation of the average time. Slither and solhint demonstrate the shortest average execution time, completing a test case in just 1 second, while ConFuzzius and sFuzz exhibit the longest average execution time, requiring approximately 18 minutes per test case. The total time taken by each tool also varies significantly, with ConFuzzius consuming the longest duration of over 26 hours, while Slither proves to be the most time-efficient, requiring only 2 minutes. It is worth mentioning that the longer average execution times of ConFuzzius and sFuzz could be attributed to their utilization of fuzzing methods, which inherently entail lengthier execution times. In summary, Table 3 offers valuable insights into the performance of different analysis tools, aiding software developers in selecting the most suitable tool for their testing requirements.

6.2.3 Effectiveness. During our experiments, we discovered that aside from accuracy and execution time, there are two additional crucial factors to consider when assessing the overall quality of analysis tools. These factors are version compatibility and category coverage. Version compatibility refers to the ability of a tool to support different versions of the programming language or framework used in smart contracts. It is essential because smart contract development frameworks often undergo updates and introduce new features or changes. An effective analysis tool should be compatible with a wide range of versions to ensure its usefulness and relevance in different development environments. Category coverage refers to the extent to which an analysis tool can detect vulnerabilities across various categories or types. Smart contract vulnerabilities can vary in nature, and different tools may have varying levels of effectiveness in detecting them. A comprehensive analysis tool should have a broad category coverage, capable of identifying vulnerabilities across multiple categories, ensuring a more thorough and comprehensive evaluation of smart contracts. By considering these factors alongside accuracy and execution time, we can obtain a more comprehensive assessment of the overall quality and effectiveness of analysis tools for smart contracts.


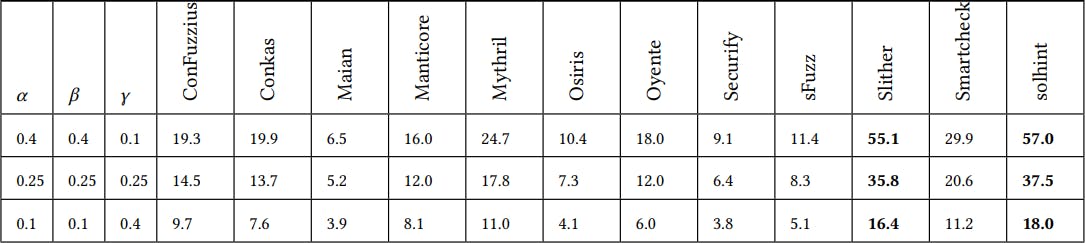
It is crucial to obtain a balance between accuracy, average execution time, compatibility version, and category coverage when evaluating the effectiveness of a tool. One common approach to achieving this balance is by using a weighted sum method, where the four factors are assigned different weights based on their relative importance. In this approach, we assign a weight of 𝛼 to accuracy, 𝛽 to average execution time, 𝛾 to compatibility version, and (1 − 𝛼 − 𝛽 −𝛾) to category coverage. We then calculate the overall score (𝑆𝑐𝑜𝑟𝑒) using the following formula:
𝑆𝑐𝑜𝑟𝑒 = 𝛼 × 𝐴 ∗ 100 + 𝛽 × (1/𝐴𝐸𝑋) ∗ 100 + 𝛾 × 𝑆𝑣 + (1 − 𝛼 − 𝛽 −𝛾) × 𝑆𝑐
where 𝐴 is the accuracy value and 𝐴𝐸𝑋 is the average execution time.
The scores for each tool can be found in Table 5. The table consists of three sets of scores, each with different weightings for the four measuring attributes: accuracy, execution time, version compatibility, and category coverage. The highest-scoring tool in each row is highlighted in bold. In the first row, where the weightings for 𝐴 (accuracy) and 𝐴𝐸𝑋 (execution time) are higher, Slither and solhint receive the highest scores. Similarly, in the second and third rows, where the weightings for 𝑆𝑣 (version compatibility) and 𝑆𝑐 (category coverage) are higher, respectively, Slither and solhint still achieve the highest scores. It is important to note that each tool has its own strengths and weaknesses, and the choice of tool should depend on the specific needs and goals of the user. For example, Slither excels in semantic-level analysis, while solhint is better suited for canonical code. This explains why solhint performs well in detecting vulnerabilities related to low-level opcodes such as call and tx.origin, but may not be able to detect vulnerabilities like reentrancy and unsafe delegatecall as shown in Table 1. Maian, on the other hand, differs from other tools as it focuses on vulnerabilities involving a long sequence of invocations of a contract.

Overall, the scores presented in Table 5 offer valuable insights into the performance of each tool when different weighting schemes are applied. By adjusting the weights assigned to the measuring factors, users can customize the evaluation criteria based on their specific requirements and priorities. This flexibility allows users to emphasize the aspects that are most critical to the evaluation process. By doing so, they can make more targeted decisions when selecting a tool. These findings provide a clear response to the fourth research question, RQ4, as outlined in Section 2.2. The evaluation of the selected analysis tools based on various factors such as accuracy, execution time, version compatibility, and category coverage has shed light on their overall effectiveness. By considering these factors, developers and researchers can make informed decisions about the most suitable tools for their smart contract analysis needs.
In addition, it is worth mentioning that using a combination of analysis tools could be an effective approach to improve the overall quality of code and detect potential vulnerabilities. For instance, solhint can be used to perform grammatical checks and ensure code adherence to standards, while Mythril can identify known vulnerabilities and help prevent attacks. Slither, on the other hand, can provide a deeper analysis of the code and detect some semantic-level issues. By using these tools in combination, developers can ensure that their code is well-written, adheres to standards, and is free from vulnerabilities to the extent possible.
Finally, in order to address the fifth research question, RQ5, as outlined in Section 2.2, we have employed established criteria for selecting the different analysis tools and developed an annotated dataset comprising 110 smart contracts. The dataset is divided into 11 sub-datasets, with 10 sub-datasets containing the faulty contracts with the top 10 known vulnerabilities discussed in Section 3, and one sub-dataset consisting of correct contracts. This dataset serves as a valuable resource for researchers and practitioners to conduct comprehensive evaluations of the capabilities and limitations of various tools. It enables them to make fair judgments when selecting the most appropriate tools for their specific requirements. By providing a standardized and annotated set of smart contracts, the dataset facilitates objective comparisons and assessments, promoting transparency and reliability in smart contract tool evaluation.
6.3 Threat to validity
Threats to validity are factors that have the potential to impact the results of an experiment and the validity of its findings. In our research, we have identified two specific aspects that could pose threats to the validity of our study: the categorization of smart contract vulnerabilities and the generality of the evaluation datasets.
One potential threat to the validity of our evaluation is the subjectivity and variation among researchers in evaluating and categorizing vulnerabilities and their associated smart contracts. Different researchers may have diverse perspectives, criteria, and interpretations when assessing the severity and classification of vulnerabilities. This subjectivity can introduce bias and affect the validity of the comparisons presented in the evaluation. To mitigate this threat, we have adopted a systematic approach based on industry standards and best practices in Section 3. We have thoroughly reviewed and discussed each vulnerability category to ensure a consistent and objective classification. This involved extensive research, consultation with experts, and careful consideration of existing literature. We have also provided clear definitions, criteria, and explanations for each vulnerability category considered in our analysis. By providing this transparency and documentation of our evaluation process, we aim to minimize ambiguity and facilitate a more consistent understanding of the vulnerabilities across different researchers and readers.
The generality of the evaluation datasets represents another potential threat to the validity of our research. This threat refers to the extent to which the datasets used for evaluation accurately reflect real-world scenarios and the usage patterns of smart contracts. If the evaluation datasets are limited in scope or fail to encompass the diversity of smart contract applications, the findings and conclusions may lack generalizability. To mitigate this threat, we have made significant efforts to address dataset limitations. We have conducted an extensive collection of contract tests from various sources, including publicly available datasets and our own developed test cases. Our dataset consists of 110 contract test cases, which have been carefully selected to cover a wide range of applications and different code sizes. By incorporating diverse contract test cases, we aim to provide a more representative evaluation of smart contract vulnerabilities and increase the generalizability of our findings.
While we have taken measures to address these threats, it is important to acknowledge that limitations may still exist. To further enhance the validity of future studies, researchers can focus on refining vulnerability categorization criteria and collecting larger, more diverse datasets that better capture real-world scenarios.
如有侵权请联系:admin#unsafe.sh