2024-6-27 06:39:8 Author: hackernoon.com(查看原文) 阅读量:2 收藏
Resilience in software refers to the ability of an application to continue functioning smoothly and reliably, even in the face of unexpected issues or failures. In Fintech projects resilience is of especially high importance due to several reasons. Firstly, companies are obliged to meet regulatory requirements and financial regulators emphasise operational resilience to maintain stability within the system. Moreover, the proliferation of digital tools and reliance on third-party service providers exposes Fintech businesses to heightened security threats. Resilience also helps mitigate the risks of outages caused by various factors such as cyber threats, pandemics, or geopolitical events, safeguarding core business operations and critical assets.
By resilience patterns, we understand a set of best practices and strategies designed to ensure that software can withstand disruptions and maintain its operations. These patterns act like safety nets, providing mechanisms to handle errors, manage load, and recover from failures, thereby ensuring that applications remain robust and dependable under adverse conditions.
The most common resilience strategies include bulkhead, cache, fallback, retry, and circuit breaker. In this article, I’ll discuss them in more detail, with examples of problems they can help to solve.
Bulkhead

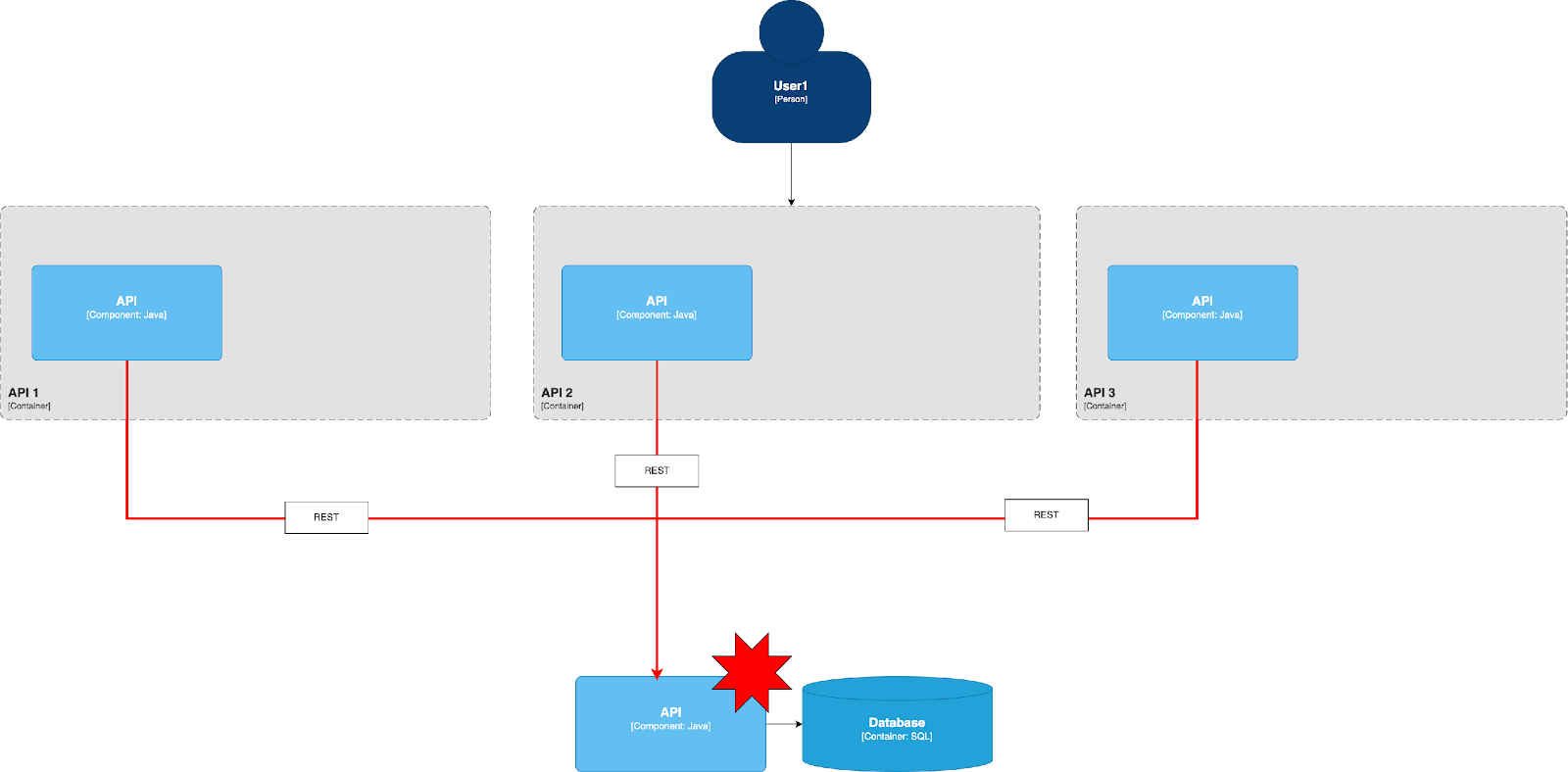
Let us take a look at the above setting. We have a very ordinary application with several backends behind us to get some data from. There are several HTTP clients connected to these backends. It turns out that all of them share the same connection pool! And also other resources like CPU and RAM.
What will happen, If one of the backends experiences some sort of problems resulting in high request latency? Due to the high response time, the entire connection pool will become fully occupied by requests waiting for responses from backend1. As a result, requests intended for the healthy backend2 and backend3 won't be able to proceed because the pool is exhausted. This means that a failure in one of our backends can cause a failure across the entire application. Ideally, we want only the functionality associated with the failing backend to experience degradation, while the rest of the application continues to operate normally.
What is the Bulkhead Pattern?
The term, Bulkhead pattern, derives from shipbuilding, it involves creating several isolated compartments within a ship. If a leak occurs in one compartment, it fills with water, but the other compartments remain unaffected. This isolation prevents the entire vessel from sinking due to a single breach.
How Can We Use the Bulkhead Pattern to Fix This Problem?

The Bulkhead pattern can be used to isolate various types of resources within an application, preventing a failure in one part from affecting the entire system. Here's how we can apply it to our problem:
- Isolating Connection Pools We can create separate connection pools for each backend (backend1, backend2, backend3). This ensures that if backend1 is experiencing high response times or failures, its connection pool will be exhausted independently, leaving the connection pools for backend2 and backend3 unaffected. This isolation allows the healthy backends to continue processing requests normally.
- Limiting Resources for Background Activities By using Bulkheads, we can allocate specific resources for background activities, such as batch processing or scheduled tasks. This prevents these activities from consuming resources needed for real-time operations. For example, we can restrict the number of threads or CPU usage dedicated to background tasks, ensuring that enough resources remain available for handling incoming requests.
- Setting Restrictions on Incoming Requests Bulkheads can also be applied to limit the number of incoming requests to different parts of the application. For instance, we can set a maximum limit on the number of requests that can be processed concurrently for each upstream service. This prevents any single backend from overwhelming the system and ensures that other backends can continue to function even if one is under heavy load.
Сache

Let's suppose our backend systems have a low probability of encountering errors individually. However, when an operation involves querying all these backends in parallel, each can independently return an error. Because these errors occur independently, the overall probability of an error in our application is higher than the error probability of any single backend. The cumulative error probability can be calculated using the formula P_total=1−(1−p)^n, where n is the number of backend systems.
For instance, if we have ten backends, each with an error probability of p=0.001 (corresponding to an SLA of 99.9%), the resulting error probability is:
P_total=1−(1−0.001)^10=0.009955
This means our combined SLA drops to approximately 99%, illustrating how the overall reliability decreases when querying multiple backends in parallel. To mitigate this issue, we can implement an in-memory cache.
How we can solve it with the in-memory cache

An in-memory cache serves as a high-speed data buffer, storing frequently accessed data and eliminating the need to fetch it from potentially slow sources every time. Since caches stored in-memory have a 0% chance of error compared to fetching data over the network, they significantly increase the reliability of our application. Moreover, caching reduces network traffic, further lowering the chance of errors. Consequently, by utilising an in-memory cache, we can achieve an even lower error rate in our application compared to our backend systems. Additionally, in-memory caches offer faster data retrieval than network-based fetching, thereby reducing application latency—a notable advantage.
In-memory cache: Personalised caches
For personalised data, such as user profiles or recommendations, using in-memory caches can be also highly effective. But we need to ensure all requests from a user consistently go to the same application instance to utilise data cached for them, which requires sticky sessions. Implementing sticky sessions can be challenging, but for this scenario, we don’t need complex mechanisms. Minor traffic rebalancing is acceptable, so a stable load balancing algorithm like consistent hashing will suffice.
What is more, in the event of a node failure, consistent hashing ensures that only the users associated with the failed node undergo rebalancing, minimising disruption to the system. This approach simplifies the management of personalised caches and enhances the overall stability and performance of our application.
In-memory cache: local data replication

If the data we intend to cache is critical and used in every request our system handles, such as access policies, subscription plans, or other vital entities in our domain—the source of this data could pose a significant point of failure in our system. To address this challenge, one approach is to fully replicate this data directly into the memory of our application.
In this scenario, if the volume of data in the source is manageable, we can initiate the process by downloading a snapshot of this data at the start of our application. Subsequently, we can receive updates events to ensure the cached data remains synchronised with the source. By adopting this method, we enhance the reliability of accessing this crucial data, as each retrieval occurs directly from memory with a 0% error probability. Additionally, retrieving data from memory is exceptionally fast, thereby optimising the performance of our application. This strategy effectively mitigates the risk associated with relying on an external data source, ensuring consistent and reliable access to critical information for our application's operation.
Reloadable config
However, the need to download data on application startup, thereby delaying the startup process, violates one of the principles of the '12-factor application' advocating for quick application startup. But, we don't want to forfeit the benefits of using caching. To address this dilemma, lets explore potential solutions.
Fast startup is crucial, especially for platforms like Kubernetes, which rely on quick application migration to different physical nodes. Fortunately, Kubernetes can manage slow-starting applications using features like startup probes.
Another challenge we may face is updating configurations while the application is running. Often, adjusting cache times or request timeouts is necessary to resolve production issues. Even if we can quickly deploy updated configuration files to our application, applying these changes typically requires a restart. With each application's extended startup time, a rolling restart can significantly delay deploying fixes to our users.
To tackle this, one solution is to store configurations in a concurrent variable and have a background thread periodically update it. However, certain parameters, such as HTTP request timeouts, may require reinitializing HTTP or database clients when the corresponding configuration changes, posing a potential challenge. Yet, some clients, like the Cassandra driver for Java, support automatic reloading of configurations, simplifying this process.
Implementing reloadable configurations can mitigate the negative impact of long application startup times and offer additional benefits, such as facilitating feature flag implementations. This approach enables us to maintain application reliability and responsiveness while efficiently managing configuration updates.
Fallback
Now let us take a look at another problem: in our system, when a user request is received and processed by sending a query to a backend or database, occasionally, an error response is received instead of the expected data. Subsequently, our system responds to the user with an 'error'.
However, in many scenarios, it may be more preferable to display slightly outdated data along with a message indicating there is a data refresh delay, rather than leaving the user with a big red error message.

To address this issue and improve our system's behaviour, we can implement the Fallback pattern. The concept behind this pattern involves having a secondary data source, which may contain data of lower quality or freshness compared to the primary source. If the primary data source is unavailable or returns an error, the system can fall back to retrieving data from this secondary source, ensuring that some form of information is presented to the user instead of displaying an error message.
Retry

If you look at the picture above, you'll notice a similarity between the issue we're facing now and the one we encountered with the cache example.
To solve it, we can consider implementing a pattern known as retry. Instead of relying on caches, the system can be designed to automatically resend the request in the event of an error. This retry pattern offers a simpler alternative and can effectively reduce the likelihood of errors in our application. Unlike caching, which often requires complex cache invalidation mechanisms to handle data changes, retrying failed requests is relatively straightforward to implement. As cache invalidation is widely regarded as one of the most challenging tasks in software engineering, adopting a retry strategy can streamline error handling and improve system resilience.
Circuit Breaker

However, adopting a retry strategy without considering potential consequences can lead to further complications.
Lets imagine one of our backends experiences a failure. In such a scenario, initiating retries to the failing backend could result in a significant increase in traffic volume. This sudden surge in traffic may overwhelm the backend, exacerbating the failure and potentially causing a cascade effect across the system.
To cope with this challenge, it's important to complement the retry pattern with the circuit breaker pattern. The circuit breaker serves as a safeguard mechanism that monitors the error rate of downstream services. When the error rate surpasses a predefined threshold, the circuit breaker interrupts requests to the affected service for a specified duration. During this period, the system refrains from sending additional requests to allow the failing service time to recover. After the designated interval, the circuit breaker cautiously allows a limited number of requests to pass through, verifying whether the service has stabilised. If the service has recovered, normal traffic is gradually restored; otherwise, the circuit remains open, continuing to block requests until the service resumes normal operation. By integrating the circuit breaker pattern alongside retry logic, we can effectively manage error situations and prevent system overload during backend failures.
Wrapping Up
In conclusion, by implementing these resilience patterns, we can strengthen our applications against emergencies, maintain high availability, and deliver a seamless experience to users. Additionally, I'd like to emphasise that telemetry is yet another tool that should not be overlooked when providing project resilience. Good logs and metrics can significantly enhance the quality of services and provide valuable insights into their performance, helping make informed decisions to improve them further.
如有侵权请联系:admin#unsafe.sh