Author:
(1) David Novoa-Paradela, Universidade da Coruña, CITIC, Campus de Elviña s/n, 15008, A Coruña, Spain & Corresponding author (Email: [email protected]);
(2) Oscar Fontenla-Romero, Universidade da Coruña, CITIC, Campus de Elviña s/n, 15008, A Coruña, Spain (Email: [email protected]);
(3) Bertha Guijarro-Berdiñas, Universidade da Coruña, CITIC, Campus de Elviña s/n, 15008, A Coruña, Spain (Email: [email protected]).
Table of Links
Anomaly detection has been a consolidated research field for years. Its great utility has allowed its techniques to be applied in numerous areas: medicine [9], industrial systems [10], electronic fraud [11], cybersecurity [12], etc. However, when we talk about texts and NLP, there is no massive application of these anomaly detection techniques as in the previous cases. This may be due to the difficulty in defining the idea of an anomaly in texts. Contrary to other scenarios, such as monitoring an industrial system through its sensors, in which the anomalous class will correspond to faults in the system, when the data is text, defining the concept of an anomaly is not trivial.
One of the most important lines of research related to the detection of anomalies in texts is fake reviews detection, also known as spam review detection, fake opinion detection, and spam opinion detection [13]. The main problem associated with fake review detection is classifying the review as either fake or genuine. There are generally three types of fake reviews [14]:
• Type 1 (untruthful opinions): Fake reviews describing users who post negative reviews to damage a product’s reputation or post positive reviews to promote it. These reviews are called fake or deceptive reviews, and they are difficult to detect simply by reading, as real and fake reviews are similar to each other.
• Type 2 (reviews on brands only): Those that do not comment on the products themselves, but talk about the brands, manufacturers, or sellers of the products. Although they can be useful, they are sometimes considered spam because they are not targeted at specific products.
• Type 3 (non-reviews): Non-reviews that are irrelevant and offer no genuine opinion.
In the work carried out by J. Salminen et al. [15], the authors try to distinguish genuine reviews from fake reviews on Amazon. To have a labeled dataset of fake reviews, they use GPT-2 [16] to artificially generate them. After this, they solve the task of distinguishing between genuine and fake reviews by fine-tuning a pretrained RoBERTa [17] model. They also show that his model is also capable of detecting fake reviews manually written by humans. Ş. Öztürk Birim et al. [18] proposed to use relevant information as the review length, purchase verification, sentiment score, or topic distribution as features to represent costumers reviews. Based on these features, well-known machine learning classifiers like random forests (RF) [19] are applied for fake detection. In their article, D. U. Vidanagama et al. [20] incorporate review-related features such as linguistic features, Part-of-Speech (POS) features, and sentiment analysis features using a domain ontology to detect fake reviews with a rule-based classifier.
L. Ruff et al. [21] presented Context Vector Data Description (CVDD), a text-specific anomaly detection method that allows working with sequences of variable-length embeddings using self-attention mechanisms. To overcome the limitations of CVDD, J. Mu et al. [22] proposed tadnet, a textual anomaly detection network that uses an adversarial training strategy to detect anomalous texts in Social Internet of Things. In addition, thanks to the capture of the different semantic contexts of the texts, both models achieve interpretability and flexibility, allowing to detect which parts of the texts have caused the anomaly.
Other authors, instead of developing text-specific AD models, make use of well-known AD and NLP techniques to design architectures that solve the problem. B. Song et al. [23] propose to analyze the accident reports of a chemical processing plant to detect anomalous conditions. In this scenario, anomalous conditions are defined as unexperienced accidents that occur in unusual conditions. The authors work directly with the original text extracting the meaningful keywords of the reports using the term frequency-inverse document frequency (TF-IDF) index. Based on this, and using the local outlier factor (LOF) algorithm, they identify anomaly accidents in terms of local density clusters, finding four major types of anomaly accidents. Working with the original texts and not with embeddings they achieve a certain interpretability in the results. In the approach presented by S. Seo et al. [24], a framework for identifying unusual but noteworthy customer responses and extracting significant words and phrases is proposed. The authors use Doc2Vec to vectorize customer responses, then LOF is applied to identify unusual responses, and based on a TF-IDF analysis and the distances in the embedding space, they can visualize useful information about the results through a network graph.
In the previous works and most cases, the detection of fake reviews focuses

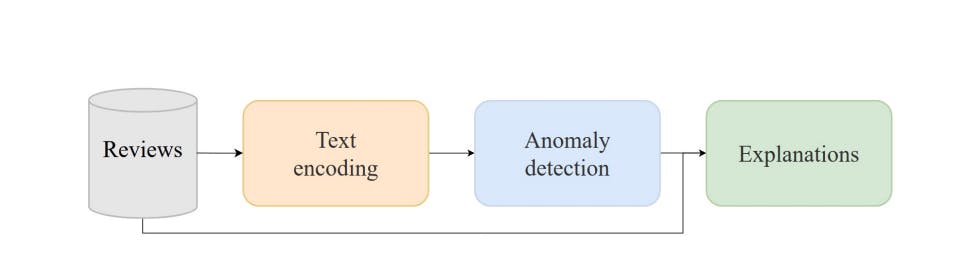
on detecting type 1 reviews, that is, reviews that positively or negatively describe a product but whose intention is not genuine since they do not come from a real buyer. Since there are several works based on this scenario [15, 18, 20], in this work we will focus on detecting type 2 and 3 reviews, which refer to reviews that do not provide information about the product itself. In this way, the objective of this work is to design a pipeline capable of distinguishing reviews related to a specific product (normal reviews) from reviews that do not and therefore do not provide information to the users that read them (anomalous reviews), for example, because they wrongly describe other products or because they are too generic. In addition to this, the classifications carried out by the system will be explained through an analysis process based on NLP techniques.
如有侵权请联系:admin#unsafe.sh