2024-6-28 20:15:26 Author: hackernoon.com(查看原文) 阅读量:1 收藏
API is commonly used as a method of data exchange between user and backend endpoints to receive authentication-based content. Lack of information security exists with the inclusion of raw fields from server databases like sequential IDs of events, orders, etc., to view in page layouts as they can be used as a source of extracting information about business-related metrics. This article focuses on data analysis approaches applied to visible fields in API responses to showcase potential vulnerabilities of such architecture and research into methods of its prevention.
Introduction
Focusing on infrastructure security within communication channels between client and server brought significant improvements in technologies and rules implemented to prevent intruders from generating, corrupting, or modifying sent data, as well as blocking its ability to be received on any of the ends. Nevertheless, the root issue, even with all the adopted restrictions, immutably remains the same - the content deliberately chosen to be sent might also include vulnerabilities for information security without initial intent.
The goal of this article is to introduce the hidden lack of security in auto-increment fields when they are chosen to be used as main identification in front-end applications and thus sent openly over API endpoints.
Data handling in client-server communication
The server-side hosting application programming interface allows communication via HTTP methods, performing commands related to user actions to either send data, upload received one to the backend, or both. The common flow of exchange includes user authentication processes leading to creating Oauth-like bearer token pairs to store on the device for future authorization, responding to generated actions by getting related data from connected databases and deleting or inserting new entries to keep the up-to-date state of information about the user. In the case of mobile applications for short-term rent actions requiring GET requests, sending data from server to user can include launching a page with available listings or opening the user's renting history. POST requests include a payload of user-generated data to be handled in the backend, with an example of pressing a button to book the chosen apartment for the selected period. DELETE requests allow for the truncation of tables or their specific entries, for instance, in situations when the user decides to delete posted comments for a listing or remove their account from the platform entirely.
A variety of actions available to the user through the interface requires attaching a database management system to the backend, handling traffic to store parsed payload from incoming requests, and extracting needed data in response. Such a connection opens the possibility of converting generated actions into SQL-like queries in a user-friendly and secure way by hiding the commands and connection management routines from the application view and filtering any malicious requests that might be generated. For instance, when attaching their authentication token among other headers to GET for bookings history endpoint with a table storing information about all the made transactions in an application, the request in the backend is then converted to a query that might look like the following:
SELECT
transaction_id,
listing_id
FROM Table
WHERE user_id = *user_id*;
transaction_id (Int64) - id of booking transaction
listing_id (Int64) - id of booked listing
user_id (Int64) - id of user who made the booking
Such an approach provides a convenient method of interaction between user and server to present needed data in an application and prevent unsanctioned access to unrelated information by denying valid responses in case of missing or damaged authentication, filtering queries execution to only return selected data based on authorization, e.g., not showing user A bookings of user B, and implementing security tools to handle SQL injection-like attacks.
Most database management systems provide a useful approach to keeping a structured sequence of entries in tables by introducing an automatic increment setting for the ID field. The mechanism is based on keeping the current counter in memory representing the numeric index value of the last entry inserted in the table and allocating counter + 1 to new row appearing in the table, and finally storing its updated value. Auto-increment ensures the uniqueness of the ID field even in case of row deletion and also provides sorting capability, knowing the rule that any entry with a larger ID was recorded later than one with a smaller value.
Security details aside, it brings focus on not whether malicious intent might be successful in retrieving data from API that was not supposed to be retrieved but rather on the security of data explicitly provided according to all the set rules. The described auto-increment identifier often acts as the primary key and is included in responses to GET for selected tables. From a business standpoint, it allows for simplicity in synchronizing references to the same exact entry in the database across any users, services, or device allocated storage (e.g., showing an auto-increment field for user_id in interface can serve as a convenient tool in case of contacting support with account deletion request because it gives a straightforward link to needed DB entry). However, with an analytical approach, it becomes possible to utilize such incremental IDs in data research to retrieve valuable company metrics without the need for system intrusion.
Competitive analysis based on data from auto-increment database ID fields
Analysis of metrics starts with the data collection process to provide values of selected measurements attached to specified timestamps of their parsing moment, allowing for further time series research. Communication with API commonly includes receiving JSON objects with predefined rules for handling their content in the front end. POST request with transaction data sent after a user performs relative action in application returns dictionary with among other fields transaction identifier created in backend database table corresponding to storing transaction events in the following structure:
{"datetime" : "YYYY-MM-DD 00:00:00", "transaction_id" : 4190823068}
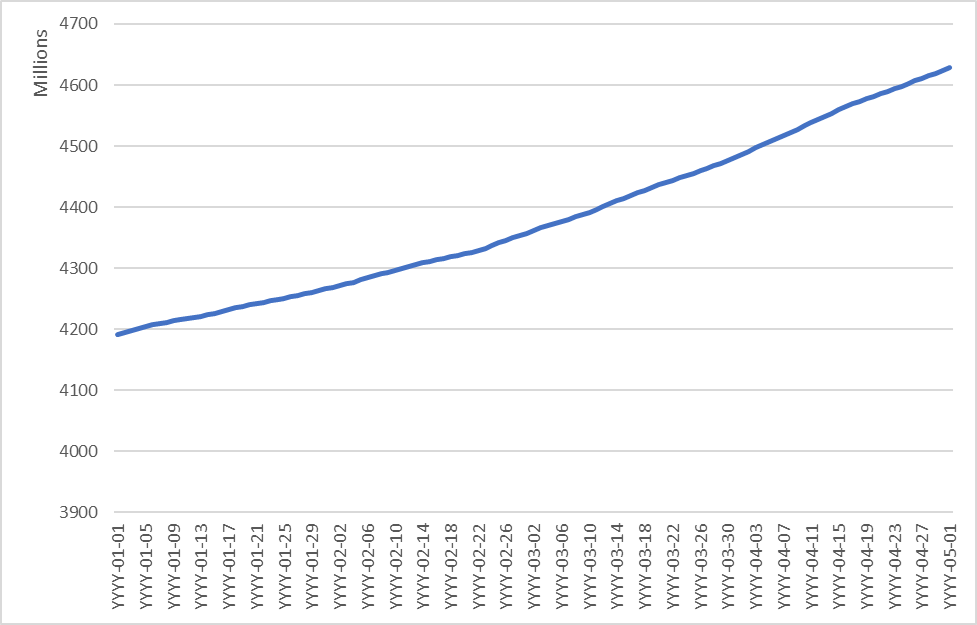
Example of multiple transaction_idvalues over a time period are presented in Figure 1.

Absolute values of returned sequential fields do not provide valid enough information to describe underlying metric data as they are likely to store its increment since the very first transaction handled in the selected backend solution, rarely with the ability to track back the precise moment of when it started. The nature of the incremental approach also implies that the counter is not refactored after any unsuccessful transactions are deleted from the database. The conclusion from the described points leads to a model of comparing multiple deltas between defined counter-value parsing moments rather than working with its single raw value to get insights about its dynamics.
Automated data-scraping code tailored to generating or viewing selected ID counters with defined intervals allows one to compare how the value changed during periods of measurement. Deltas are then calculated as differences between current and previous values. The results of code-collecting transactions daily with equal intervals are presented in Table 1 (Delta values of database ID).
|
datetime |
transaction_id |
id delta |
|---|---|---|
|
YYYY-MM-01 |
4190823068 |
- |
|
YYYY-MM-02 |
4194606047 |
3446714 |
|
YYYY-MM-03 |
4198052761 |
3337648 |
|
YYYY-MM-04 |
4201390409 |
3225201 |
|
YYYY-MM-05 |
4204615610 |
2808664 |
Observing identifiers in such a way does not allow to divide visible ID counters into only business-focused values, such as confirmed transactions, and all the others, e.g., failed ones, backend stress tests, and gaps in case the incrementation rule is set to add random numbers instead of the fixed single shift in writing new values to the table. Despite the lack of straightforward insight, regular data parsing provides delta values sufficient to analyze the dynamics of the targeted metrics over a period of time and, where applicable, convert them into absolute values.
Public companies provide quarterly financial information about their performance with the usual inclusion of leading quantitative indicators. In the example of a short-term renting business, the number of active users on the platform might be presented, as well as the total nights booked or new listings added. Matching such key statistics to the respective IDs collected from backend interaction leads to the opportunity to extract the ratio between business-related values and all others inside the increments mentioned above. Suppose a company states to have 0.75x transactions of total delta value between parsing dates of the same time period. In that case, it can be assumed that a quarter of all transactions written to the database were invalid or in some other way irrelevant to the chosen research (if linear regression among other hypotheses has the closest resemblance to the pattern between data points from parsed values and reported ones with an intercept being 0). The final transition from initial raw IDs to measurable time series is shown in Figure 2.

The combination of extracting intel from insecure API and examination of corresponding reporting figures results in opportunities for data-driven solutions from competitors of the company being analyzed. Metrics built by multiple key parameters from the operational activity of a company are a useful source of comparing entity industry`s market trends as well as the impact of selected ad campaigns or new features introduced overall or in targeted A/B tests aimed at diminishing competitor market share in specific user scenarios. Detailed time periods at which changes can be observed moreover contribute to expected impact by allowing the test hypotheses faster (statistical significance test is required to prove that the chosen length of the observation period is representative of total ID increment over the over-reporting quarter).
API architecture solutions for information security
Detailed analysis of methods of extracting valuable insights from auto-increment database fields sent over API interaction leads to the need for research into approaches to ensure system information security. As the core vulnerability appears to be the inability to measure differences between various ID values due to their sequential generation, a useful solution arrives with changing auto-increment fields for randomly generated ones. In such architecture, when a user observes multiple identifiers of the same database field, it is made impossible to understand how many IDs were generated between those. To also ensure the uniqueness of every created value, a 128-bit standard label used for information storage called UUID can be used as its probability of duplication is generally considered close enough to zero to be negligible.
Transitioning to a non-sequential identifier generation method might bring inconvenience with previously used frontend data processing, e.g., sorting returned lists of listings available for booking from newly added to oldest. Apart from numerous workarounds open to solve such issues, the one with the artificial necessity to proceed with sorting by ID can be implemented by keeping an auto-increment identifier field in the database alongside randomly created and sorting returned values in the backend by adding respective sorting clauses to generated SQL-like requests to DB relative to user-specified content for frontend interaction. The auto-increment field is then used in the same manipulations but kept invisible by never being sent over API.
Further security of information stored in databases can be achieved by determining the architecture of the endpoints tree for API. Pursuing a zero-tolerance policy about sharing access to data associated with user A to user B should be set as a priority. In case the API GET endpoint is structured as /../api/v2/transactions/{transaction_id} and no extra authentication rules are applied when returning database content for specified transaction_id, it is then possible to get information on other users’ transactions by knowing its identifier or brute-forcing it, or when it is proved to be generated with auto-increment rule simply checking sequences of consecutive numbers to receive data on ones that exist in system as real transactions.
A technical solution to the vulnerability is to implement an extra layer of authentication rules when accessing a database storing respective data to check if it does not break set logic sequences, like users being able to view only their own transactions. Practical implementation of SQL generated in the backend in response to GET request asking to return data on set transaction_id can be change from state 1) to state 2) as follows:
-- 1)
SELECT *
FROM Table
WHERE transaction_id = *transaction_id*
-- 2)
SELECT *
FROM Table
WHERE transaction_id = *transaction_id*
AND user_id = *user_id*
A deeper rework of endpoints might include removing any urls where set global ID values are sent overall to eliminate any attempts of unauthorized access to any sensitive data by changing it to locally generated for each user by handling its link to the global identifier in the backend and thus never present any auto-increment or random-generated ID field at all.
Conclusion
The results of the research behind this paper confirm that openly including auto-increment fields from databases is an insecure method of transmitting data as it can be used for competitive analysis of operational statistics about the company in question. Extracting such insights has the potential for detrimental long-term effects when used to develop strategic changes to win market share from other players. There are straightforward methods for improving information security for API architecture, including changing open auto-increment identifiers for randomly generated and linking them only in the backend and restructuring endpoints trees to prevent unrestricted large-scale parsing and unauthorized access. To further learn about what identifiers to use in your backend architecture, you can check out my Hackernoon article about UUID generation best practices preventing it from being vulnerable and as obviously analyzed as auto-increment ones described here:
如有侵权请联系:admin#unsafe.sh