
大模型安全挑战和安全要求解读
日期:2024年07月02日 阅:42
引言
随着人工智能技术的飞速发展,大模型技术以其卓越的性能和广泛的应用前景,正在重塑人工智能领域的新格局。然而,任何技术都有两面性,大模型在带来前所未有便利的同时,也引发了深刻的安全和伦理挑战。
大模型,作为深度学习领域的杰出代表,通过海量数据的训练,拥有了惊人的语言理解、图像识别等能力,极大地推动了人工智能技术在各个领域的创新应用。然而,这一技术的强大能力同时也带来了潜在的威胁。从个人隐私泄露到虚假信息生成,再到对抗样本攻击,大模型及其衍生的安全风险不容忽视。
在数字化时代,数据安全与隐私保护已成为人们关注的焦点。大模型在处理海量数据的过程中,不可避免地会涉及到用户的个人信息。如何确保这些信息的安全,防止数据泄露和滥用,成为我们必须面对的重要问题。
此外,大模型的强大能力也可能被恶意利用。一旦不法分子掌握了这项技术,他们就能够利用大模型生成虚假信息,进行网络攻击和社会工程,对国家安全、社会稳定和个人权益造成威胁。
在此背景下,各国政府和相关机构纷纷加强了对大模型行业的监管。我国以《网络安全法》《数据安全法》以及《个人信息保护法》为基础,结合《生成式人工智能服务管理暂行办法》等规定,构建了一套相对完善的大模型监管体系。然而,面对日新月异的技术发展和复杂多变的安全形势,我们仍需不断加强研究、完善制度、提升能力,确保大模型技术的健康、可持续发展。
因此,探讨大模型安全问题的紧迫性和重要性不言而喻。网宿科技期待通过各方的共同努力,为大模型技术的发展保驾护航,让其在推动科技进步、服务人类社会的道路上走得更远、更稳。
大模型应用安全挑战和威胁
在本章节,我们将基于网宿大模型的安全实践经验,从数据安全与隐私问题、模型流转/部署过程中的安全问题、AIGC的内容合规问题以及大模型运营过程中的业务安全问题四个方向,详细解读相关的安全挑战。
数据安全与隐私问题
大模型在训练过程中需要大量的数据作为支撑,这些数据往往包含用户的敏感信息。一旦这些数据被恶意利用或泄露,将带来严重的后果。数据安全与隐私问题的挑战主要体现在以下几个方面:
数据泄露:由于大模型通常需要在云端进行训练,数据在传输和存储过程中可能面临泄露的风险。攻击者可能通过窃取数据或利用漏洞来访问敏感信息。
数据滥用:即使数据没有被直接泄露,攻击者也可能通过分析大模型的输出结果来推断出原始数据的信息,进而滥用这些数据。
隐私侵犯:大模型在处理用户数据时,可能无意中侵犯了用户的隐私权。例如,通过分析用户的文本输入,大模型可能能够推断出用户的身份、兴趣、习惯等敏感信息。
模型流转/部署过程中的安全问题
大模型在流转和部署过程中也面临着诸多安全问题。这些问题主要包括对抗攻击、后门攻击和prompt攻击等。
对抗攻击:对抗攻击是指攻击者通过精心构造的输入来欺骗大模型,使其产生错误的输出。这种攻击方式对于依赖大模型进行决策的系统来说具有极大的威胁。
后门攻击:后门攻击是指攻击者在训练大模型时嵌入特定的“后门”,使得攻击者能够在不破坏模型整体性能的情况下,通过特定的输入来操纵模型的输出结果。这种攻击方式具有隐蔽性和难以检测的特点。
prompt攻击:prompt攻击是一种新型的攻击方式,它利用大模型对prompt的敏感性来实施攻击。攻击者通过构造特定的prompt来诱导大模型产生错误的输出或泄露敏感信息。
AIGC的内容合规问题
AIGC(AIGeneratedContent)是指由人工智能生成的内容。随着大模型在内容生成领域的广泛应用,AIGC的内容合规问题也日益凸显。这些问题主要包括版权侵权、虚假信息、低俗内容等。
版权侵权:AIGC在生成内容时,可能会侵犯他人的版权。例如,未经授权使用他人的作品作为训练数据,或者生成的内容直接复制了他人的作品。
虚假信息:由于大模型在训练过程中可能接触到大量的虚假信息,因此AIGC在生成内容时也可能包含虚假信息。这些虚假信息可能会误导用户,甚至对社会造成不良影响。
低俗内容:AIGC在生成内容时,可能会产生低俗、不道德的内容。这些内容不仅可能违反社会公德,还可能对用户造成心理伤害。
大模型运营过程中的业务安全问题
大模型在运营过程中也面临着业务安全问题的挑战。这些问题主要包括数据投毒、模型误用和滥用等。
数据投毒:数据投毒是指攻击者在训练数据中故意添加错误或有害的信息,以破坏大模型的性能或引导其产生错误的输出。这种攻击方式对于依赖大模型进行决策的系统来说具有极大的威胁。
模型误用和滥用:大模型在运营过程中可能会被误用或滥用。例如,攻击者可能利用大模型进行恶意攻击、传播虚假信息等。此外,一些不法分子还可能利用大模型进行非法活动,如诈骗、洗钱等。
综上所述,大模型应用面临着多方面的安全挑战和威胁。为了保障大模型的安全性和可靠性,我们需要加强技术研发、完善法律法规、加强监管和教育宣传等方面的工作。只有这样,我们才能充分发挥大模型在推动科技进步和社会发展中的积极作用。
大模型安全基本要求解读


模型安全要求
模型生成内容安全性:要求服务提供者应对每次使用者输入的信息进行安全性监测,引导模型生成积极正向内容,并建立常态化检测测评手段,对测评过程中发现的安全问题及时处置,通过指令微调、强化学习等方式优化模型。
模型生成内容准确性:要求服务提供者采用技术手段提高生成内容的实时性与精准度。
模型生成内容可靠性:要求服务提供者采取技术措施提高生成内容格式框架的合理性以及有效内容的含量,提高生成内容对使用者的帮助作用。
安全措施要求
模型适用性
服务提供者在服务范围内应用AIGC时应充分论证模型的必要性、适用性和安全性。应设立未成年人保护措施,同时需遵守《未成年人保护法》《个人信息保护法》《未成年人网络保护条例》等规定,保障未成年人身心健康安全。
服务透明度
在网站首页等显著位置向社会公开服务适用的人群、场合、用途等信息,并公开基础模型使用情况。以可编程接口形式提供服务的,应在说明文档中公开上述信息。
用户数据处理
服务提供者应为用户提供便捷途径关闭输入信息用于模型训练的功能,如设置易懂选项或简洁语音控制指令。为确保便捷性,《要求》明确:通过选项关闭时,操作过程应控制在四次点击以内。同时,服务提供者应确保界面设计或用户交互中显著告知信息收集状态,并清晰展示关闭选项或指令,以符合“透明度”要求。
用户管理
实施监测机制:通过关键词筛查或分类模型等方式,对用户输入的信息进行实时监测,以便及时发现并处置不当行为;
拒绝回答机制:对于检测到的含有明显偏激或诱导生成违法不良信息的问题,服务提供者的系统应自动拒绝回答,防止传播潜在有害内容。
人工监看机制:配备专门的监看人员,及时根据监看情况提升生成内容的质量与安全性,并对第三方投诉进行收集和响应。
《办法》第十五条明确规定,服务提供者应建立健全投诉、举报机制。
服务稳定性
为维护服务稳定性,《要求》建议服务提供者采取安全措施。例如隔离训练与推理环境,防止数据泄露和不当访问。持续监测模型输入内容,预防恶意攻击。定期安全审计,识别和修复安全漏洞。建立数据、模型备份和恢复策略。
安全评估要求
为确保评估工作的可操作性,《要求》特别针对语料安全、生成内容安全、问题拒答等方面提出了量化的评估标准,具体要求请见下表。

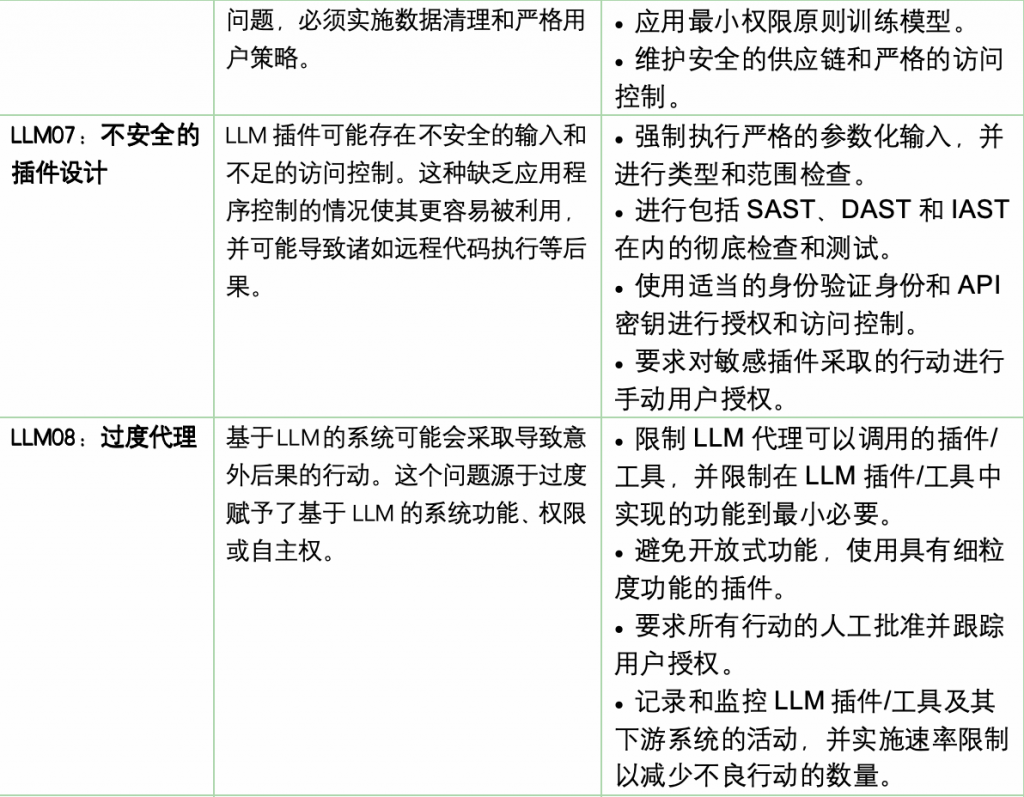
OWASP大模型TOP10安全风险
OWASP组织在2023年10月16日发布了LLM(大型语言模型)十大安全风险1.1版本,概述了针对LLM的潜在攻击方式、预防措施和攻击场景,可以帮助读者更好的理解LLM所面临的安全风险以及应对策略。



总结
大模型应用正面临严峻的安全挑战和威胁,包括数据隐私泄露、网络攻击、注入漏洞等。全国网络安全标准化技术委员会发布的《生成式人工智能服务安全基本要求》为行业提供了明确的安全指引,要求服务提供者加强语料安全、模型安全等方面的管理。网宿科技作为网络安全领域的领军企业,积极应对大模型带来的安全风险。同时,借鉴OWASP大模型TOP10安全风险清单,网宿科技致力于提升大模型应用的安全性,保护用户数据安全,为大模型的健康发展提供有力保障。

网宿安全
基于全球广泛分布的边缘节点,依托10余年安全运营和海量攻防数据,「网宿安全」构建从边缘到云的智能安全防护体系,提供DDoS防护、Web应用防护、爬虫管理、远程访问安全接入、安全SD-WAN、主机安全等全方位的安全产品及服务,覆盖云安全、企业安全和安全服务等领域,助力企业构筑基于零信任和安全访问服务边缘(SASE)模型的全新安全架构,护航网络安全,为数字时代保驾护航。 网宿科技(300017)成立于2000年,2009年于创业板首批上市,是全球领先的边缘计算及安全服务商,业务遍及全球70多个国家和地区。公司始终致力于提升用户的数字化体验,满足用户随时随地、安全、可靠的数据处理及交互需求。
如有侵权请联系:admin#unsafe.sh