2024-7-6 00:9:48 Author: hackernoon.com(查看原文) 阅读量:4 收藏
Authors:
(1) Xueguang Ma, David R. Cheriton School of Computer Science, University of Waterloo;
(2) Liang Wang, Microsoft Research;
(3) Nan Yang, Microsoft Research;
(4) Furu Wei, Microsoft Research;
(5) Jimmy Lin, David R. Cheriton School of Computer Science, University of Waterloo.
Table of Links
Conclusion, Acknowledgements and References
3 Experiments
We conduct experiments on MS MARCO passage ranking and document ranking datasets to investigate the effectiveness of the multi-stage text retrieval pipeline built using RepLLaMA and RankLLaMA for both passage and document retrieval.
3.1 Passage Retrieval
Dataset We train our retriever and reranker models with LLaMA on the training split of the MS MARCO passage ranking dataset (Bajaj et al., 2016), which consists of approximately 500k training examples. As discussed in Section 2.2, the incorporation of hard negatives is crucial for the effective training of the retriever. In our case, we use a blend of BM25 and CoCondenser (Gao and Callan, 2022b) hard negatives to ensure that the hard negatives are derived from both sparse and dense retrieval results, thereby enhancing the diversity of the samples. For the reranker, we select the hard negatives from the top-200 candidates generated by the retriever.
We evaluate the effectiveness of our models using the development split of the MS MARCO passage ranking task, comprising 6980 queries. Effectiveness is reported using MRR@10 as the metric. In addition, we also evaluate our models on the TREC DL19/DL20 passage ranking test collections (Craswell et al., 2020, 2021), which include 43 and 54 queries, respectively. These collections utilize the same passage corpus as MS MARCO, but provide query sets with dense, graded human relevance judgments. Following standard practice, we adopt nDCG@10 as the evaluation metric in our experiments.
In addition, we assess the zero-shot effectiveness of RepLLaMA and RankLLaMA on BEIR (Thakur et al., 2021), which is a compilation of 18 datasets that spans a variety of domains (e.g., news, medical) and retrieval tasks (e.g., fact verification, question answering). We focus our evaluation on the 13 datasets that are publicly available.
Implementation Details We initialize our models with the LLaMA-2-7B checkpoint2 and train on 16 × 32G V100 GPUs. For RepLLaMA, we extract the final layer representation of the token as the dense representation, which has a dimensionality of 4096. Additionally, we normalize these dense representations into unit vectors during both the training and inference stages, ensuring that their L2-norms are equal to 1. After pre-encoding the entire corpus, we end up with a 135G flat index for brute-force search.

A challenge in fine-tuning LLMs for retrieval is the high GPU memory costs associated with contrastive learning, as it requires large batch sizes for in-batch negatives. To address this, we employ recent memory efficiency solutions, including LoRA (Hu et al., 2022), flash attention (Dao, 2023), and gradient checkpointing to reduce GPU memory usage. Both the retriever and reranker are trained with a batch size of 128, with 15 hard negative passages sampled for each query. At inference time, RepLLaMA retrieves the top-1000 passages from the corpus and RankLLaMA reranks the top-200 passages retrieved by RepLLaMA. To explore whether increases in model size can further improve effectiveness, we also train a version of RankLLaMA using LLaMA-2-13B initialization.3
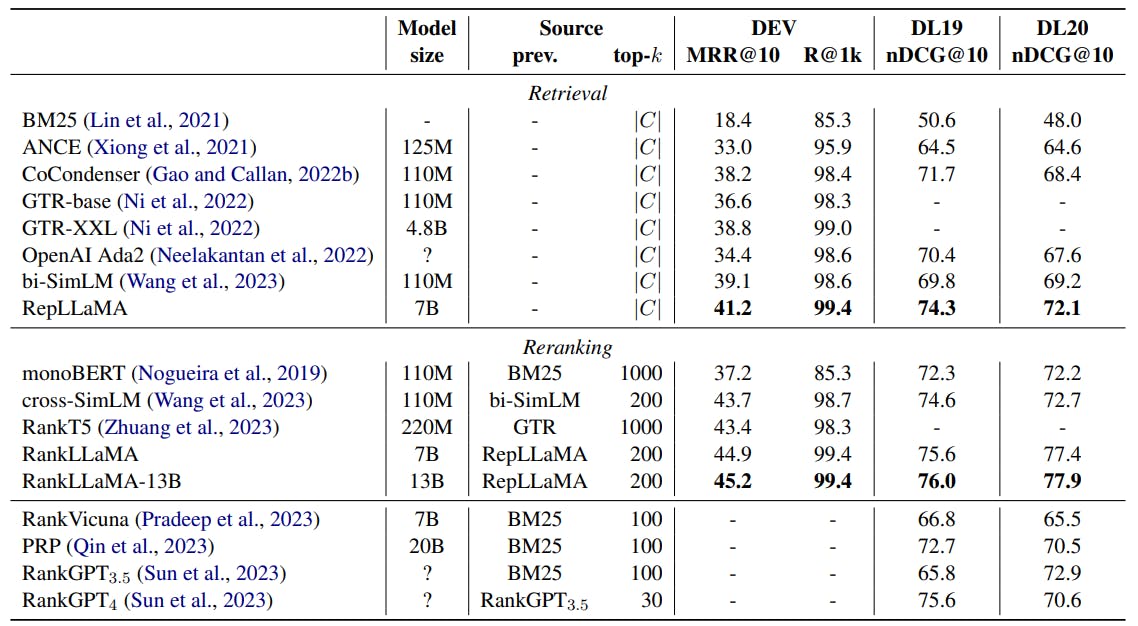
In-Domain Evaluation Table 1 presents the effectiveness of RepLLaMA and RankLLaMA on the MS MARCO passage corpus in comparison to existing methods.
For retrieval, RepLLaMA outperforms all competing methods, achieving the highest effectiveness. The closest system in terms of effectiveness is bi-SimLM (Wang et al., 2023), which RepLLaMA outperforms by 2 points MRR@10 on the dev queries. However, bi-SimLM involves a pretraining stage for enhancing the text representation. In contrast, RankLLaMA directly uses the off-theshelf LLaMA model as initialization. When compared to the GTR-XXL retriever, which also uses a model with billions of parameters based on the T5- encoder (Ni et al., 2022), our model achieves higher MRR@10 and Recall@1k on the dev queries and on TREC DL19/DL20. Specifically, RepLLaMA achieves 2.4 points higher MRR@10 and 0.4 points higher Recall@1k than GTR-XXL.
It is worth noting that recent studies have shown the potential to further improve dense retrieval models by learning from soft labels provided by a reranker via optimizing KL-divergence. However, in this study, we train our model with only binary judgments. Training RepLLaMA by knowledge distillation will likely lead to further improvements, but we save this for future work.
For reranking, RankLLaMA reranks the top-200 passages from RepLLaMA, resulting in the highest end-to-end effectiveness of any multi-stage retrieval system that we are aware of. Our complete RepLLaMA–RankLLaMA pipeline beats the previous state-of-the-art reranker, RankT5 (Zhuang et al., 2023), by 1.5 points MRR@10. Furthermore, our RankLLaMA-13B model outperforms the 7B model, achieving 0.3 points higher MRR@10 and slightly higher nDCG@10 on both DL19 and DL20. This indicates the potential for further improvements with even larger models.

Compared to RankGPT4 (Sun et al., 2023), which prompts GPT-4 to perform passage reranking through permutation generation within a multistage retrieval pipeline, our RepLLaMA–RankLLaMA pipeline outperforms it by 0.4 and 7.3 nDCG@10 points on DL19 and DL20, respectively. As a pointwise reranker, RankLLaMA can rerank candidate passages in parallel, which means that inference can be accelerated to reduce latency as compared to RankGPT, which depends on a sequential sliding-window strategy to rerank.
Zero-Shot Evaluation The zero-shot evaluation of RepLLaMA and RankLLaMA on the BEIR datasets is presented in Table 2. Both models demonstrate superior zero-shot effectiveness, outperforming existing models. RepLLaMA surpasses other existing dense retrievers with billions of parameters. Specifically, it outperforms SGPT (Muennighoff, 2022) and Ada2 by 3 points and exceeds GTR-XXL by approximately 6 points. Note that these methods require an unsupervised contrastive pre-training stage before the supervised fine-tuning. In contrast, RepLLaMA uses the base pre-trained model as initialization, achieving the highest zeroshot effectiveness we are aware of while maintaining simplicity. RankLLaMA-7B further enhances the retriever’s effectiveness by an average of 1.5 points on nDCG@10. Interestingly, the larger RankLLaMA-13B model does not appear to yield any further improvements.
3.2 Document Retrieval
Dataset The document retrieval task aims to rank document-length texts, which present the challenge of handling long input sequences (Bajaj et al., 2016). As illustrated in Figure 1, the MS MARCO document ranking corpus has an average document length of around 1500 tokens. Notably, only 24% of the documents have fewer than 512 tokens, which is the maximum input length for most previous rerankers based on smaller pre-trained language models like BERT (Devlin et al., 2019).
The standard solution to manage long sequences for retrieval is the MaxP strategy (Dai and Callan, 2019), which involves dividing the document into overlapping segments and determining the document relevance score based on the segment with the highest score. However, this process involves a heuristic pooling strategy and runs the risk of losing information spread across long contexts. Recent language models pre-trained on longer sequences (e.g., 4096 tokens for LLaMA-2) offer the potential to represent document-length texts “in one go”, reducing the need for segmentation.


By default we allow the retriever and reranker to take the first 2048 tokens as input without any segmentation, which is a reasonable trade-off between input sequence length and the cost of training. This approach covers about 77% of the documents in the corpus entirely. We create the training data for the document retriever and reranker models based on the 300k training examples in the training set. Similar to the approach in passage ranking, we sample the hard negative documents to train RepLLaMA from the top-100 hard negatives from BM25 and our implementation of CoCondenser-MaxP. Here, BM25 directly indexes the entire documents, while CoCondenser retrieves documents using the aforementioned MaxP strategy. The hard negatives for RankLLaMA are selected from the top-100 results of RepLLaMA.
Evaluation of document retrieval is performed on the development split of the MS MARCO document ranking dataset, which contains 5193 queries. Additionally, we evaluate our models on the TREC DL19/DL20 document ranking tasks, comprising 43 and 45 queries, respectively.
Implementation Details We follow a similar setup as in the passage ranking task to train both document RepLLaMA and RankLLaMA, with the same computing resources. However, there are two key differences: First, the models are trained with a batch size of 128, with each query sampling 7 hard negative passages. Second, during inference, RepLLaMA retrieves the top-1000 documents while RankLLaMA reranks the top-100 documents that are retrieved by RepLLaMA. The document model also generates text embeddings with 4096 dimensions. For the MS MARCO document corpus, this results in a 49G (flat) index after pre-encoding the entire corpus.
Results Table 3 reports the effectiveness of our RepLLaMA–RankLLaMA pipeline for fulldocument retrieval on the MS MARCO document corpus. We see that both our retriever and reranker outperform existing methods. RepLLaMA achieves an MRR@100 score that is approximately 3 points higher than CoCondenser-MaxP, while RankLLaMA exceeds (to our knowledge) the current state-of-the-art document reranker, MORES+ (Gao and Callan, 2022a), by 1 point in MRR@100.
We again emphasize that both our retriever and reranker do not require document segmentation and rank score aggregation. Instead, RepLLaMA directly consumes the entire document, and RankLLaMA directly scores the relevance of the entire query–document pair.

2 https://huggingface.co/meta-llama/Llama-2-7b-hf
3 https://huggingface.co/meta-llama/ Llama-2-13b-hf
如有侵权请联系:admin#unsafe.sh