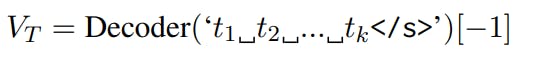
2024-7-6 00:9:41 Author: hackernoon.com(查看原文) 阅读量:3 收藏
Authors:
(1) Xueguang Ma, David R. Cheriton School of Computer Science, University of Waterloo;
(2) Liang Wang, Microsoft Research;
(3) Nan Yang, Microsoft Research;
(4) Furu Wei, Microsoft Research;
(5) Jimmy Lin, David R. Cheriton School of Computer Science, University of Waterloo.
Table of Links
Conclusion, Acknowledgements and References
2 Method
2.1 Preliminaries
Task Definition Given a query Q and a corpus C = {D1, D2, ..., Dn} consisting of n documents, the goal of text retrieval is to find the k documents that are most relevant to the query Q, with k ≪ n. In a multi-stage retrieval pipeline composed by a retriever and a reranker, the retriever’s task is to efficiently generate the top-k candidates that are relevant to the query based on the similarity metric Sim(Q, D) ∈ R. The reranker’s task is to reorder these k candidate documents further to improve the relevance order using a more effective, but typically more computationally expensive reranking model. Note that “document” in this context can refer to an arbitrary information snippet, including sentences, passages, or full documents. While a multi-stage pipeline can contain multiple rerankers, in this paper we focus on a single reranker.
Modern retrievers typically follow a bi-encoder architecture that encodes text into vector representations, with Sim(Q, D) computed as the dot product of the vector representations of the query Q and a document D (Karpukhin et al., 2020). In contrast, a (pointwise) reranker typically takes both the query and a candidate document as input to directly generate a relevance score. These scores are then used to reorder the candidates (Nogueira et al., 2019; Gao et al., 2021).
LLaMA LLaMA (Touvron et al., 2023a) is an auto-regressive, decoder-only large language model based on the Transformer architecture. The model is characterized by its billions of parameters, pre-trained on a vast amount of web data. Being uni-directional means that the model’s attention mechanism only considers the preceding elements in the input sequence when making predictions. Specifically, given an input sequence x = [t1, t2, ..., tn−1], the model computes the probability of the next token tn based solely on the preceding tokens. The prediction process can be mathematically represented as P(tn|t1, ..., tn−1), where P denotes the probability and tn represents the next element in the sequence.
2.2 Retriever
Our retriever model, called RepLLaMA, follows the bi-encoder dense retriever architecture proposed in DPR (Karpukhin et al., 2020), but with the backbone model initialized with LLaMA.
Previous work on dense retriever models often uses a bi-directional encoder-only model like BERT, taking the representation of the prepended [CLS] token as the dense representation of the text input. However, as LLaMA is uni-directional, we append an end-of-sequence token to the input query or document to form the input sequence to LLaMA. Thus, the vector embedding of a query or a document is computed as:

where Decoder(·) represents the LLaMA model, which returns the last layer token representation for each input token. We take the representation of the end-of-sequence token as the representation of the input sequence t1 . . . tk, which can be either a query Q or a document D. Relevance of D to Q is computed in terms of the dot product of their corresponding dense representation VQ and VD as Sim(Q, D) =< VQ, VD >.
The model is then optimized end-to-end according to InfoNCE loss:

Here, D+ represents a document that is relevant to the query Q (based on human labels), while {DN } denotes a set of documents that is not relevant to the query. The set of negative documents includes both hard negatives, which are sampled from the top-ranking results of an existing retrieval system, and in-batch negatives, which are derived from the positive documents and hard negative documents associated with other queries in the same training batch. In practice, dense retrieval training tends to benefit from a larger set of hard negatives and in-batch negatives.
During the inference phase, the query is typically encoded in real-time and the top-k similar documents are searched within the pre-encoded corpus using an efficient approximate nearest neighbour search library such as HNSW (Malkov and Yashunin, 2020). However, in this study, we opt to perform exact nearest neighbour search using flat indexes to evaluate model effectiveness.
2.3 Reranker
Our reranker model, referred to as RankLLaMA, is trained as a pointwise reranker. This approach involves passing a query and a candidate document together as model input, with the model generating a score that indicates the relevance of the document to the query (Nogueira et al., 2019).
In more detail, RankLLaMA reranks a query– document pair as follows:

where Linear(·) is a linear projection layer that projects the last layer representation of the end-ofsequence token to a scalar. Similar to the retriever, the model is optimized by contrastive loss. However, in this case, the negative documents do not involve in-batch negatives.
To train a reranker that is optimized to rerank candidates from a specific retriever in a multi-stage pipeline, hard negatives should be sampled from the top-ranking results from that retriever. Specifically, in our case, the hard negative training data for RankLLaMA are selected from the top-ranking results of RepLLaMA.
During the inference stage, the top candidate documents retrieved by RepLLaMA are reordered. This reordering is based on the relevance score that RankLLaMA assigns to each query–document pair, with the documents arranged in descending order of relevance.
如有侵权请联系:admin#unsafe.sh