扫码订阅《中国信息安全》
邮发代号 2-786
征订热线:010-82341063
近几年,大模型推动人工智能技术迅猛发展,极大地拓展了机器智能的边界,展现出通用人工智能的“曙光”。如何准确、客观、全面衡量当前大模型能力,成为产学研用各界关注的重要问题。设计合理的任务、数据集和指标,对大模型进行基准测试,是定量评价大模型技术水平的主要方式。大模型基准测试不仅可以评估当前技术水平,指引未来学术研究,牵引产品研发、支撑行业应用,还可以辅助监管治理,也有利于增进社会公众对人工智能的正确认知,是促进人工智能技术产业发展的重要抓手。全球主要学术机构和头部企业都十分重视大模型基准测试,陆续发布了一系列评测数据集、框架和结果榜单,对于推动大模型技术发展产生了积极作用。然而,随着大模型能力不断增强和行业赋能逐渐深入,大模型基准测试体系还需要与时俱进,不断完善。
近日,中国信息通信研究院(简称“中国信通院”)联合多家机构发布《大模型基准测试体系研究报告(2024年)》。
点击下载:
报告首先回顾了大模型基准测试的发展现状,对已发布的主要大模型评测数据集、体系和方法进行了梳理,分析了当前基准测试存在的问题和挑战,提出了一套系统化构建大模型基准测试的框架——“方升”大模型基准测试体系,介绍了基于“方升”体系初步开展的大模型评测情况,并对未来大模型基准测试的发展趋势进行展望。面向未来,大模型基准测试仍存在诸多开放性的问题,还需要产学研各界紧密合作,共同建设大模型基准测试标准,为大模型行业健康有序发展提供有力支撑。
报告主要内容
大模型基准测试领域占比分布
2. 与传统认为Benchmark仅包含评测数据集不同,大模型基准测试体系包括关键四要素:测试指标体系、测试数据集、测试方法和测试工具。指标体系定义了“测什么?”,测试方法决定“如何测?”,测试数据集确定“用什么测?”,测试工具决定“如何执行?”
大模型基准测试体系构成
3. 虽然当前大模型基准测试发展迅速,涉及内容范围广泛,但仍存在一些挑战性问题,主要包括:建立规范化的评测体系、构建面向产业应用的基准、模型安全能力评估、评测结果与用户体验的差异、测试数据集的“污染”问题和评测数据集的“饱和”使用问题。
4. 为提供大模型基准测试体系的规范化建设思路,2023年底,中国信通院发布“方升”大模型基准测试体系。“方升”测试体系涵盖基准测试的4个关键要素,即指标体系、测试方法、测试数据集和测试工具。其从行业、应用、通用和安全能力4个维度全面评估大模型的表现,特别将重点评估大模型的产业应用效果,这对大模型的落地具有重要参考价值。
“方升”大模型基准测试体系
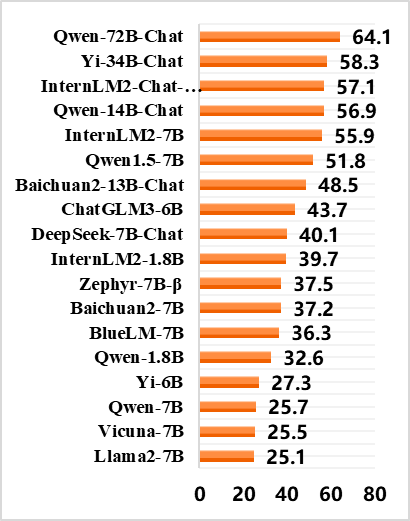
5. 中国信通院于2024年初启动“方升”首轮试评测,针对大模型的通用、行业、应用和安全能力进行全方位评测。被测对象为30多家国内外主流的闭源(商业)大模型和开源大模型,如GPT-4、Qwen-72B- Chat、LLaMA2等。报告公布了本次开源大模型的评测结果,可以发现开源大模型的表现除了依赖模型参数量,还与模型版本迭代时间相关。
开源大模型评测榜单结果
6. 大模型基准测试不应该仅仅作为大模型研发的终点,以发布测试榜单为目的,更重要的是切实发现大模型问题,驱动大模型能力的提升,指导大模型的研究方向和应用路线。因此,产学研各界应该在探索新的测试方法、构建自动化测试平台以及共享高质量评测数据集等方面协同发力。
报告目录
(一)大模型基准测试的重要意义
(二)蓬勃发展的大模型基准测试
(三)大模型评测发展共性与差异
二、大模型基准测试现状分析
(一)大模型基准测试体系总体介绍
(二)代表性的大模型基准测试体系
(三)问题与挑战
三、大模型基准测试体系框架
(一)“方升”大模型基准测试体系
(二)“方升”自适应动态测试方法
(三)“方升”大模型测试体系实践
四、总结与展望
(一)形成面向产业应用的大模型评测体系
(二)构建超自动化的大模型基准测试平台
分享网络安全知识 强化网络安全意识
欢迎关注《中国信息安全》杂志官方抖音号
《中国信息安全》杂志倾力推荐
“企业成长计划”
点击下图 了解详情
如有侵权请联系:admin#unsafe.sh