少年 18 岁时的梦
记得我 18 岁那年高考完在家,还没放松几天就被我爸催着去找份暑假工作。当时我对工作一点概念也没有,糊了份简历就在 58 同城上乱投,投完第二天跟一家公司约了线下聊聊,结果还真让我聊到个在家兼职的工作。(后来发现其实巨不靠谱)
工作内容大致是开发微信小程序,我当时仅有一点自学的微信小程序的开发经验和 PHP CodeIgniter 后端经验,差不多能 Hold 住对面的需求,甚至还在 GitHub 上给一个小程序前端组件库提了 PR。(现在回过头看当初写的代码,真的是“满目疮痍”——前端 UI 没对齐,后端 SQL 注入满天飞,黑历史了属于是)
直到大学开学前,暑假的两个月里我给那边开发了两个微信小程序。因为每次都要用 CodeIgniter 框架写功能类似的后端,年少的我在想能否把 MVC 的 Model 操作数据库,Controller 处理逻辑,View 返回响应给封装成一个线上的服务,我在图形化的 Web 页面上点点点就可以实现建表、验证表单、定义 API 接口等操作。
我被自己这个天才般的点子所鼓舞,用 PHP 写了 WeBake ,当时的想法是用来快速构建微信小程序后端。年少的我以为自己在做前人从来没做过的东西,沉浸其中并暗自窃喜。直到进入大学的前一天夜里,我在知乎上偶然看到了一家同类型的 SaaS 应用推广,也是在跟我做相同的东西,并且已经开始了商业化,我才知道业内有很多公司都已经在做了。那天晚上我直接心态爆炸。关于 WeBake 这个项目后面也就理所当然的弃坑了。
后来发生的事,大家也都知道了:微信后面发布了「微信云开发」的一站式后端解决方案,直接官方必死同人。再后来 “LowCode 低代码”的概念开始流行,LeanCloud 被心动游戏收购,国外 AirTable、国内黑帕云、维格表 Vika 等产品开始流行起来…… 而那个当时让我心态爆炸的做小程序后端的 SaaS 产品,在互联网上几乎找不到它的痕迹了。
开始填坑
我在 2021 年的时候看到了 Hooopo 的文章 Let’s clone a Leancloud,里面介绍了使用 Postgres 实现类似 LeanCloud 的 Schemaless Table 的特性。我直呼好家伙,没想到 Postgres 的视图和 JSON 数据类型还可以这样玩出花来。我当时对着文章用 Go 实现了个小 Demo,感觉确实有意思。但是因为没有具体的需求,那个 Demo 一直躺在我的 GitHub 里。
今年我放弃 WordPress 使用 Hugo 重构了本博客,一直没找到个能满足我需求的静态博客评论组件,便想自己造轮子写一个。但是评论服务的后端,不就跟留言板一样,都是些很基础很无脑的 CRUD 吗?我已经不想再用 Go 无脑写 CRUD 了!要不我把需求抽象一层,直接写个“低代码数据中台”出来?好像有点意思哦……?
就这样,Sayrud 诞生了。
Schemaless 特性
Schemaless,中文机翻为「无模式」,让人听得云里雾里的,让我们一步步来。
首先,数据库语境的 Schema 可以简单的理解为是数据库的表结构定义,我有一张学生表,表里有学号、姓名、班级三列,然后学号是主键…… 这些就是 Schema 。在关系型数据库中,我们得写 SQL 语句来定义这张表:
CREATE TABLE students (no TEXT, name TEXT, class TEXT);
后面需求改了,要再新增一列记录“出生日期”,那我们得写 SQL 修改表结构:
ALTER TABLE students ADD COLUMN birth_date DATE;
如果改得多了,那这就有点烦了。况且在实际的项目里我们还得去编写数据库迁移的 SQL 并在线上运行迁移的 Migration 程序。聪明的你估计想到了我们可以用 MongoDB 来做呀!要新增一列直接在 JSON 中加一个字段就行,无所谓什么“表结构”的概念。表结构的概念没了,也就是 Schema 没了。英文中形容词 -less 后缀指 without ,这就有了 Schemaless 这个词。简单来说就是跟 MongoDB 一样不受表结构定义的条条框框,想加字段就加字段。
市面上的很多 Schemaless 特性的产品,其后端大多都使用 MongoDB 实现。但我前文中提到了 Hooopo 那篇文章,再加上我对 Postgres 的热爱,我决定另辟蹊径使用 Postgres 来实现。
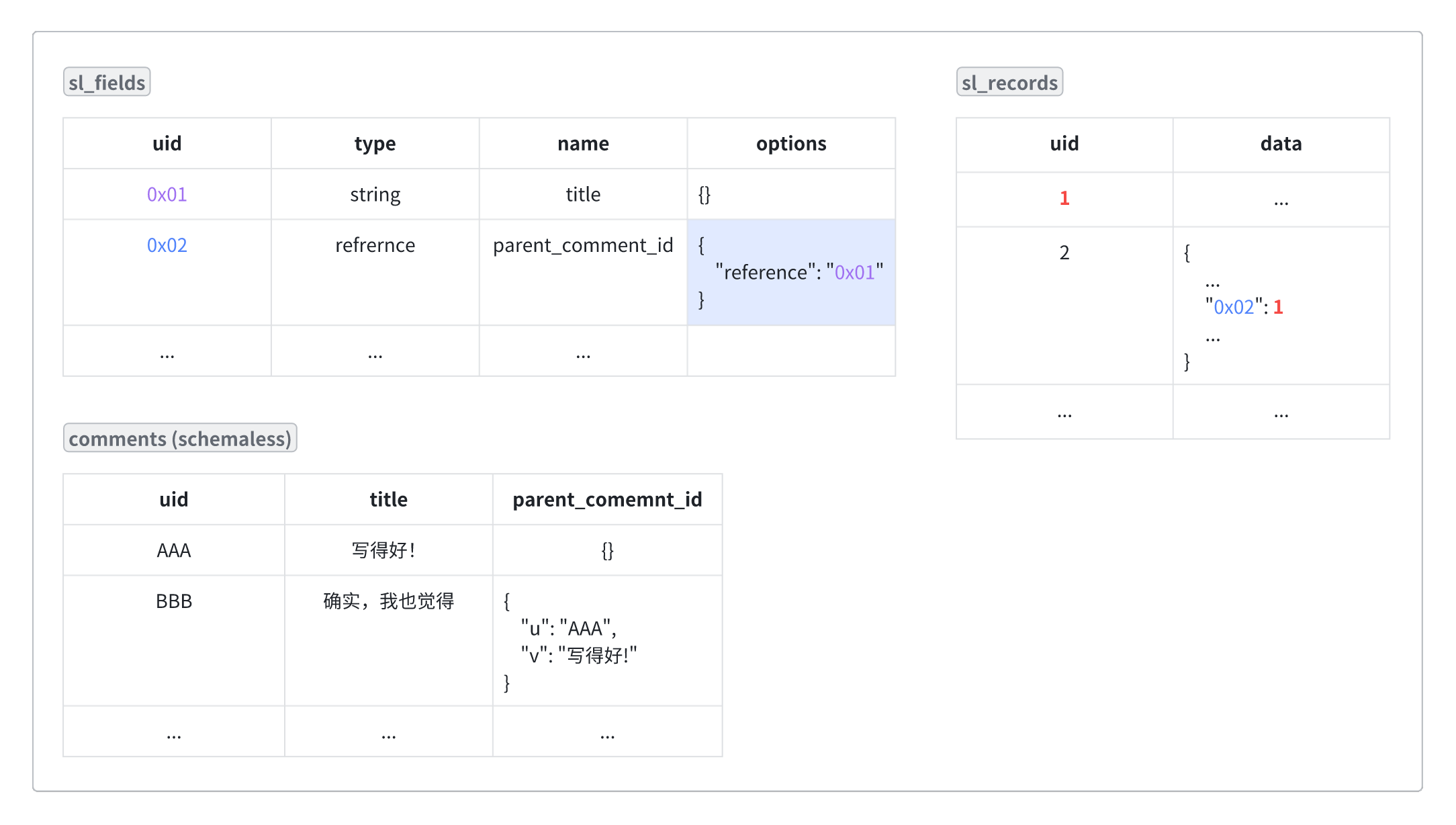
我们平时写后端,需要先建表,定义表里有哪些字段,最后往表里插数据,对应到 Sayrud 使用 sl_tables sl_fields sl_records 三张表来存储。(以下列出的表结构精简了项目分组、gorm.Model 里包含的字段)
sl_tables: Schemaless 表
| 字段名 | 类型(Go) | 说明 |
|---|---|---|
| name | string | 表名,给程序看的 |
| desc | string | 表备注名,前端给人看的 |
| increment_index | int64 | 记录当前自增 ID |
sl_fields:Schemaless 字段
| 字段名 | 类型(Go) | 说明 |
|---|---|---|
| sl_table_id | int64 | 属于哪张表 |
| name | string | 字段名 |
| label | string | 字段备注,前端给人看的 |
| type | string | 字段类型,包括 int text bool float timestamp reference generated 等 |
| options | json.RawMessage | 字段额外的属性,如默认值、约束条件等 |
| position | int | 字段在表中的顺序 |
sl_records:Schemaless 数据
| 字段名 | 类型(Go) | 说明 |
|---|---|---|
| sl_table_id | int64 | 属于哪张表 |
| data | json.RawMessage | JSON 存数据,Key 为字段的 ID,Value 为字段的值 |
然后神奇的事情就来了~ 我们按照 Hooopo 上述文章里所介绍的,为每一个 Schemaless 表当创建一张视图。以下是一个视图的 SQL 定义示例:
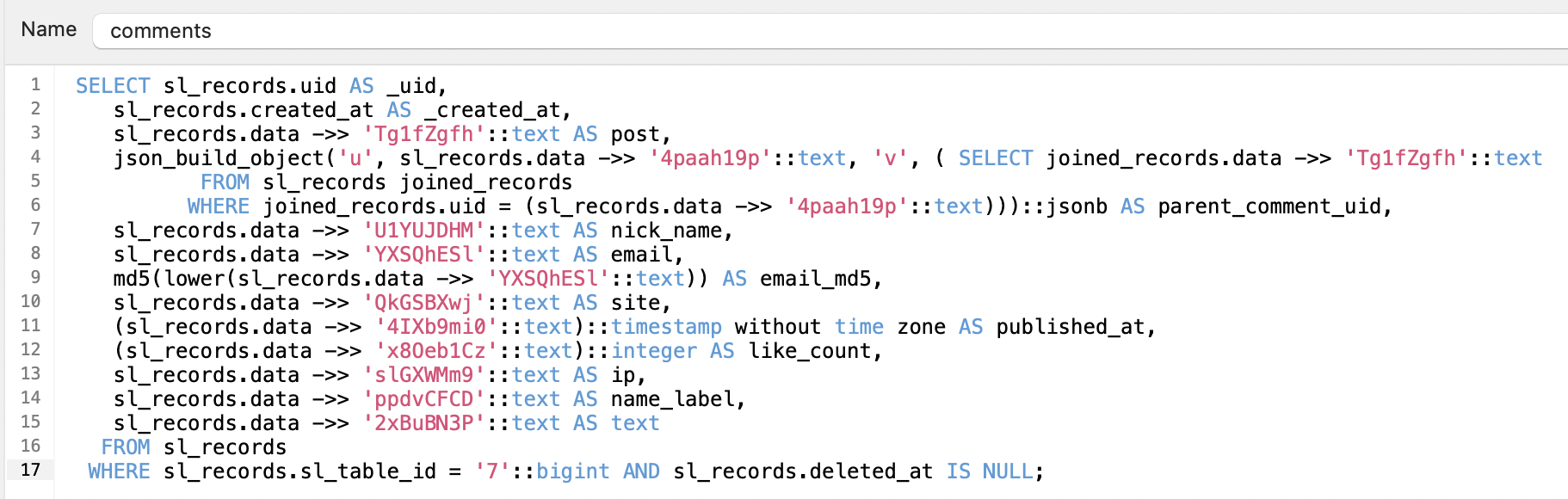
得益于 Postgres 对 JSON 类型的强大支持,我们可以从 sl_records 表中提取 JSON 字段的值作为内容,构建出一张“表”,效果如下:

当用户需要查询 Schemaless 表中的数据时,我们直接查询这张视图就行。对于 GORM 而言,这就跟查询一张普通的表一样!它都不会意识到这是由三张表拼凑提取出来的数据。更神奇的是,当你对着这张视图删除一条记录时,对应的 sl_records 原始表中的记录行也会被删除!Postgres 居然能把这俩关联起来。
具体到代码实现上,我们需要动态构造创建视图的 SQL 语句。而像字段、表名这类关键字在 SQL 语句中是不支持 SQL 预编译传入的,为了避免潜在的 SQL 注入风险,我使用了 github.com/tj/go-pg-escape 库来对字段名和表名进行转义。
正如 Hooopo 文章中所提到的,我将这个视图创建在了另一个 Postgres Schema 下,与默认的 public 进行区分,这也是一种简易的多租户实现了。
有坑注意! 之前看到过这篇文章: 《我们使用 Postgres 构建多租户 SaaS 服务时踩的坑》,文中提到使用 Postgres Schema 构建多租户时,如果每个 Postgres Schema 下都是同样的表结构,同时对所有 Postgres Schema 中的表结构变更会有性能问题。但上述场景在我们这里不存在,可以忽略该问题。
引用列、生成列、字段约束的实现
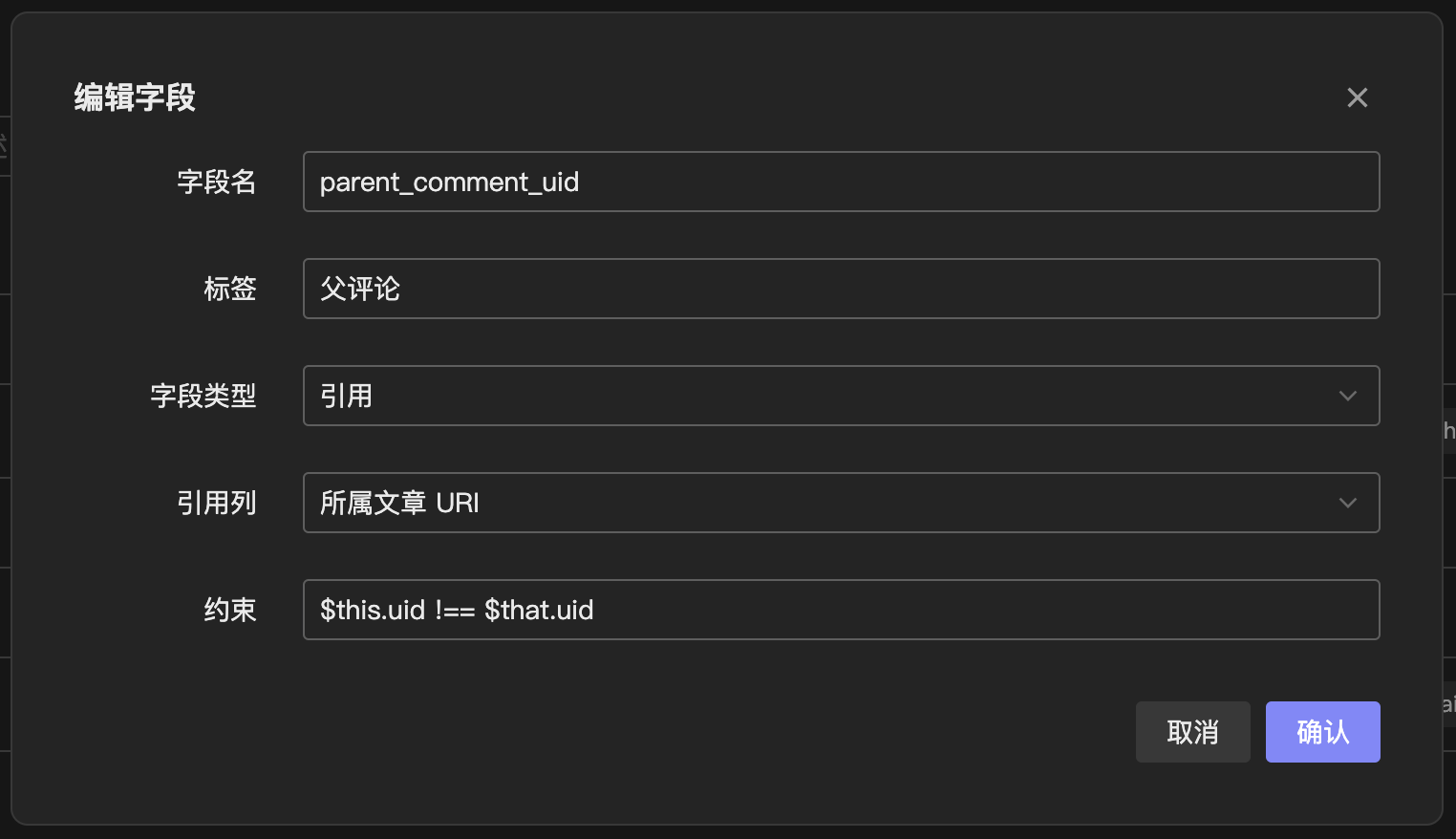
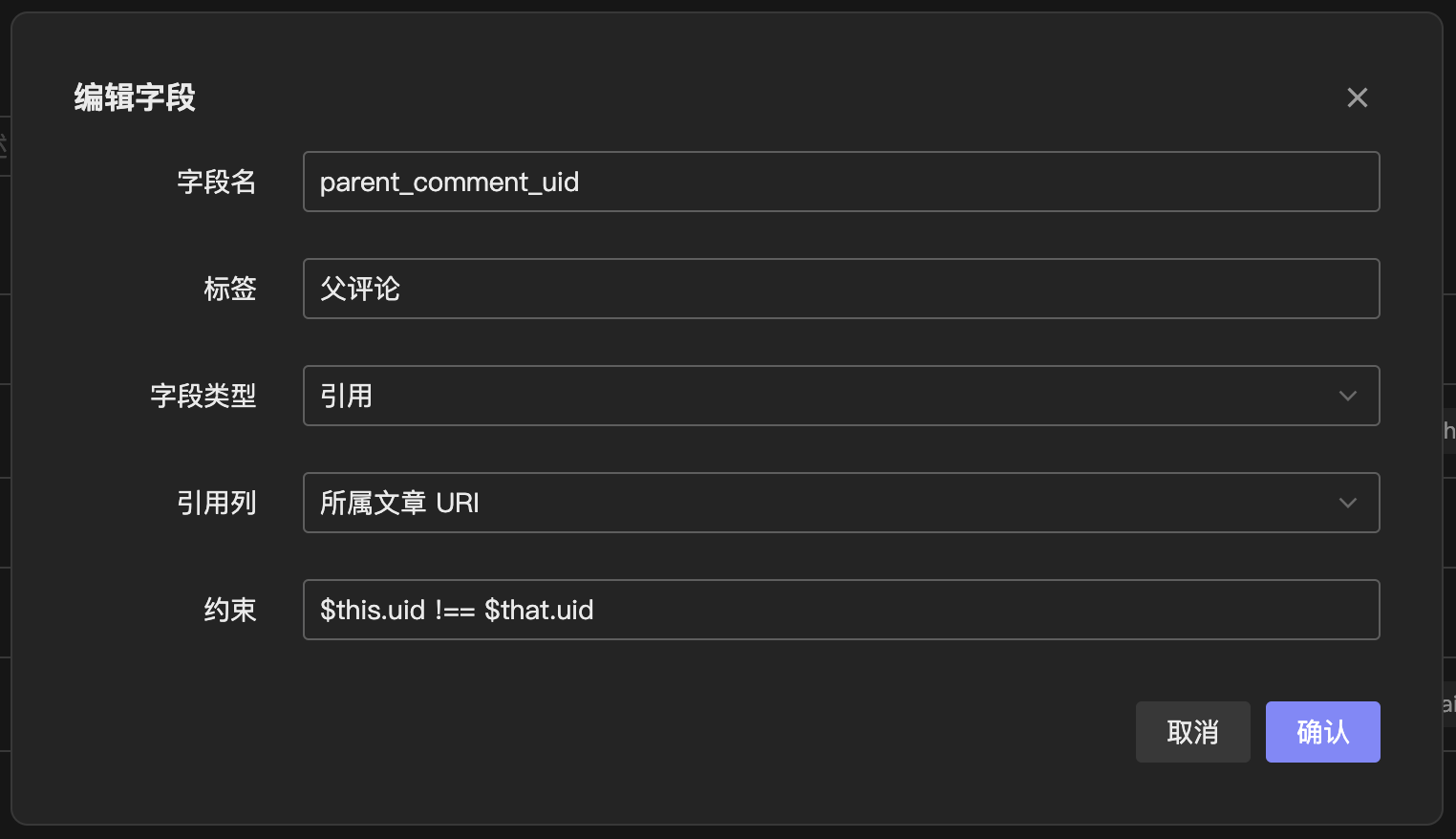
当我们开发一个博客评论后端时,功能上需要支持回复他人的评论,即数据之间会存在引用关系,我们一般会在 comments 表中加一列 parent_comment_id 来存储父评论的 ID。对应到 Schemaless 的字段类型里,就需要有 reference 这样一种引用类型。
我的设计是,当字段类型为 reference 时,其字段值存储的是所引用记录的 UID,字段额外属性 options 里记录它实际展示的列,如下图所示:
在生成视图时,使用 Postgres json_build_object 来构造 reference 类型字段展示的 JSON。(再次感叹 Postgres 真是太强大了!)JSON 中的字段 u 为关联记录的唯一 UID,方便前端处理时找到这一条记录。v 为关联记录的展示字段,用于在前端 Table 表格上展示给用户看。
在实际的博客评论记录中,一条评论是不能将自己作为自己的父级评论的。即我们要对 reference 字段的引用值进行约束。我给 reference 字段加了一个 constraint 属性,用户可以输入 JavaScript 表达式来自定义约束行为。JavaScript 表达式返回 true / false ,来表示数据校验是否通过。背后的实现是接了 goja 这个 Go 的 JavaScript Engine 库。我将当前记录传入 JavaScript 运行时的 $this 变量中,将被关联的记录传入 $that 变量中,对于上述需求,我们只需要写 $this.uid !== $that.uid 就可以约束一条评论的父评论不能是它自身。
除了能引用他人的评论,在博客评论中还需要展示评论者的头像,通常的做法是使用评论者的电子邮箱去获取其 Gravatar 头像进行展示。即将评论者的电子邮箱地址全部转换为小写后,再做 MD5 哈希,拼接到 https://gravatar.com/avatar/ 或者其他镜像站地址之后。在 Postgres 里我们可以使用生成列(Generated Columns)来很轻松的做到这一点:
CREATE TABLE comments (
email TEXT,
email_md5 TEXT GENERATED ALWAYS AS (md5(lower(email))) STORED
);
但在 Schemaless Table 里呢?一开始我的想法是像上面做字段约束一样接 JavaScript Engine,在添加数据时跑一遍 JavaScript 表达式计算出生成列的值就行。但这存在一个问题:如果 JavaScript 表达式被修改了,那就得全表重新跑重新更新刷一遍数据,这是无法接受的。
最后还是选择让用户编写 Postgres SQL 语句片段,用作创建视图时生成列的定义,就像前面视图的 SQL 定义那张图里的:
md5(lower(sl_records.data ->> 'YXSQhESl'::text)) AS email_md5,
但既然用户能直接编写原生 SQL,SQL 还会被拼接进来创建视图,那我这不直接 SQL 注入被注烂了!就算用黑名单来过滤字符串特殊字符与关键字,保不齐后面出来个我不知道的方法给绕了。这里我使用了 auxten/postgresql-parser 这个库(Bytebase 也在用)来将用户输入的 SQL 语句解析成 AST,然后 Walk 遍历树上的每个节点,发现有 UNION JOIN 以及白名单外的函数调用就直接禁止提交。如果有人 bypass 了这个库的解析规则绕过了我的检验,那也就等同于他找到了 CockroachDB 的洞(这个 AST 解析库是从 CockroachDB 源码中拆出来的),那我直接拿去水个 CVE。😂
在具体代码实现中,由于 postgresql-parser 这个库只能解析完整的 SQL 语句,而用户输入的是 md5(lower(email)) 这样的 SQL 片段,我会在用户输入前拼一个 SELECT 再解析。而像 email 这种字段名,由于提供没有上下文,会被解析成 *tree.UnresolvedName 节点。我需要将这些 *tree.UnresolvedName 节点的值替换成 sl_records.data ->> 'YXSQhESl'::text 这样的 JSON 取值语句,直接修改节点的话出来的语句会是:
md5(lower("sl_records.data ->> 'YXSQhESl'::text"))
它将这整一块用双引号包裹,会被 Postgres 一整个当做列名去解析。我也没能找到在 Walk 里修改节点属性的方法,最后只能用一个比较丑陋的 HACK:替换节点内容时前后加上一段分隔符,在最后生成的 SQL 语句中找到这个分隔符,将分隔符和它前面的 " 引号去掉。(不由得想起 PHP 反序列化字符逃逸……)
最终实现大致如下,目前函数白名单仅放开了极少数的哈希函数和字符串处理函数。我还写了不少单元测试来测这个函数的安全性,希望没洞吧……
var whiteFunctions = []string{
"md5", "sha1", "sha256", "sha512",
"concat", "substring", "substr", "length", "lower", "upper",
}
func SterilizeExpression(ctx context.Context, input string, allowFields map[string]string) (string, error) {
w := &walk.AstWalker{
Fn: func(ctx interface{}, node interface{}) (stop bool) {
switch v := node.(type) {
...
case *tree.UnresolvedName:
inputFields = append(inputFields, v.String())
// HACK: We add separator to get the field name.
v.Parts[0] = "!<----!" + allowFields[v.Parts[0]] + "!---->!"
...
return false
},
}
...
// Remove the separator.
sql = strings.ReplaceAll(sql, `"!<----!`, "")
sql = strings.ReplaceAll(sql, `!---->!"`, "")
return sql, nil
}
API 接口设计
聊完了 Schemaless 特性的实现,我们再来看下自定义 API 接口的实现。这里直接上前端的操作页面,方便我来逐一介绍。
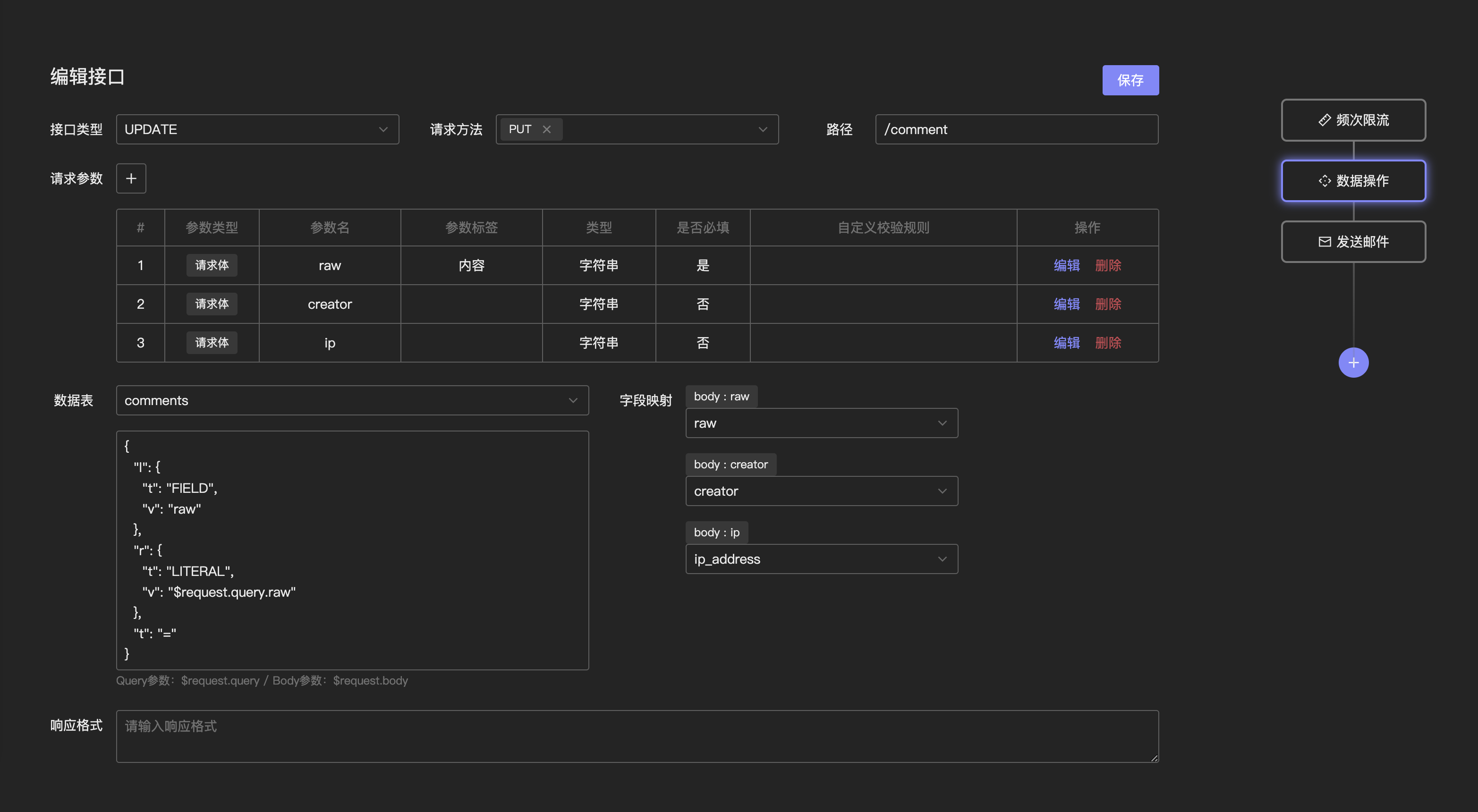
参考之前用过的 Pocketbase,我将接口分为 LIST VIEW CREATE UPDATE DELETE 五种类型。注意这与 HTTP 请求动词或数据库 DDL 操作并无关系,是偏业务上的定义。LIST 返回多条数据、VIEW 查询单条数据、CREATE 添加数据、UPDATE 修改数据、DELETE 删除数据。
就像我们写后端需要定义路由一样,每个 API 接口会有它请求方法和路径。以及会定义每个接口它从 GET Query 和 POST Body 处接收的字段。这些字段除了要有英文的参数名外,还需要有给人看的标签名,用于展示在数据校验的报错信息里。
然后我们会选择一张 Schemaless 数据表作为数据源(记得在 Dreamweaver 里叫“记录集”),把传入参数与数据表中的字段做映射,这样就完成了对数据的操作流程。而就整个请求而言,在请求开始前我们可能会想做一层限流或者验证码,请求结束后需要发送通知邮件或触发 WebHook,因此还需要支持配置路由中间件。
这里有两个值得拿来讨论的部分:数据源的筛选规则与前端拖拽配置路由中间件。
Filter DSL
我们的接口经常会有传入 ?id=1 来筛选指定一条数据的需求,确切的说是在 LIST VIEW UPDATE DELETE 四种类型下都会遇到。Schemaless 表的增删改查在代码上最终都是用 GORM 来构造 SQL 并执行的,“筛选”对应查询中的 WHERE ,对应 GORM 中的 Where 方法。用户在前端编辑好筛选条件后,需要能“翻译”成 GORM 的 Where 查询条件(一个 clause.Expression 类型的变量)。
我在这里设计了一种使用 JSON 格式来表示 Where 查询条件的方法。一个查询条件分为两种类型,一种是单操作符,仅接收一个或零个参数,如字面量 true、「非」操作 NOT xxxx ;另一种是常见的双操作符的,如「与」操作 xxx AND xxx、xxx LIKE xxx,它们接收两个参数。
我们定义一个 Operator 结构体,它记录了当前 WHERE 查询的操作类型 Type、单操作符的参数 Value 、双操作符的左值 Left 和右值 Right。注意左值和右值又可以是一个查询条件,构造 WHERE 条件的时候需要递归解析下去。
type Operator struct {
Type OperatorType `json:"t"`
Value json.RawMessage `json:"v,omitempty"`
Left *Operator `json:"l,omitempty"`
Right *Operator `json:"r,omitempty"`
}
对应的操作符有以下这些,你可以看到上方的双操作符都是对应着 SQL 语句中的操作,下面单操作符中有两个特殊的操作 FIELD 和 LITERAL 。其中 FIELD 会被解析为 Schemaless 表中的字段,而 LITERAL 的内容将被放到 JavaScript Engine 中运行,请求的 Query 和 Body 会被解析后注入到 JavaScript Runtime 中。你可以通过一个值为 $request.query.id 的 LITERAL 操作拿到 id 这个 Query 参数的值。
const (
// Binary operators
OperatorTypeAnd OperatorType = "AND"
OperatorTypeOr OperatorType = "OR"
OperatorTypeNotEqual OperatorType = "<>"
OperatorTypeEqual OperatorType = "="
OperatorTypeGreater OperatorType = ">"
OperatorTypeLess OperatorType = "<"
OperatorTypeGreaterEqual OperatorType = ">="
OperatorTypeLessEqual OperatorType = "<="
OperatorTypeLike OperatorType = "LIKE"
OperatorTypeIn OperatorType = "IN"
// Unary operators
OperatorTypeNot OperatorType = "NOT"
OperatorTypeField OperatorType = "FIELD"
OperatorTypeLiteral OperatorType = "LITERAL"
)
形如上面前端图中的那段 Filter:
{
"l": {
"t": "FIELD",
"v": "raw"
},
"r": {
"t": "LITERAL",
"v": "$request.query.raw"
},
"t": "="
}
我们从最外层开始解析,就是将左值和右值做 = 操作,左值是数据表的 raw 字段,右值是 $request.query.raw 即 Query 参数 raw,所以上述这么一长串到最后的 Go 代码里形如:
query.Where("raw = ?", ctx.Query["raw"])
十分优雅,又十分安全。只是目前前端这个 Filter 还是给你个文本框自己填 Filter JSON,后续会做成纯图形化点点点的组件。(因为评估了下不太好写,所以先咕着🕊)
前端拖拽路由中间件
路由的中间件,我一开始就想把常用的功能封装成模块,然后前端直接拖拽着使用。其中对数据操作的主逻辑为 main 中间件,这个不可删除,其它的可以自由编排。
后端的实现很简单,相信看过任意 Go Web 框架源码的小伙伴都知道,又是些被说烂了的“洋葱模型”之类的东西。说穿了就是对整个中间件的 Slice for 遍历一下,判断发现其中的某个中间件返回响应(ctx.ResponseWriter().Written() 为 true ),就直接整个返回了,这里就不贴代码水字数了。
前端我使用了 vue3-smooth-dnd 这个库,我对比了 Vue 多个拖拽库,貌似只有这一家的动画最为丝滑,并且还带自动吸附。最后实现的效果我也是十分满意:
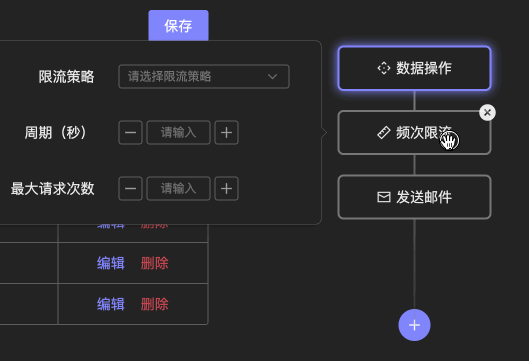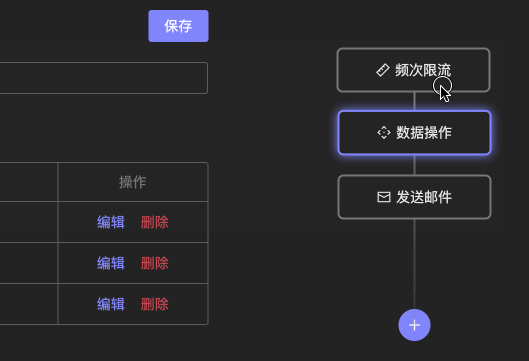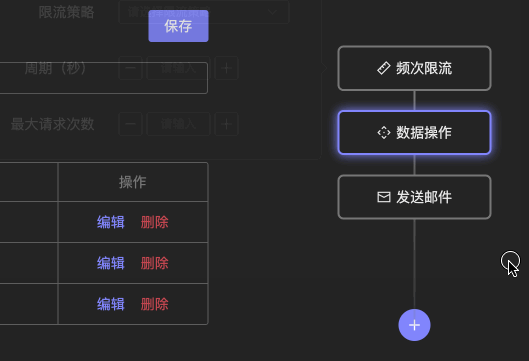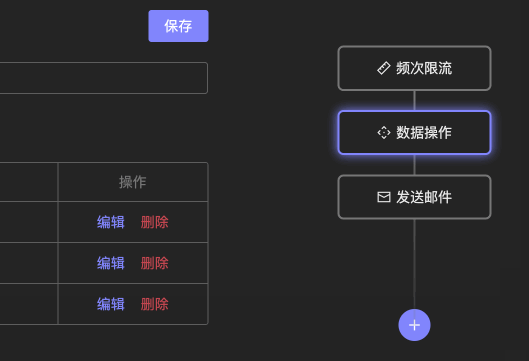
这个中间件模块的节点是我自己画的,背景设置为灰色, 然后后面放一个细长的 div 作为流程的直线。鼠标放在中间件节点上时会有一个 popup 配置中间件的具体参数。这里是直接用的 TDesign 的 Popup 弹出层组件,里面再放一个 Card 卡片组件把弹出层空间撑开即可。
最后说几句
目前 Sayrud 已经初步开发完并部署到了线上,它已经完美支持了我想要一个静态博客评论后端的需求,后面只需要接上我写得前端就可以用了!(目前我开发的博客评论组件还没上,你现在看到的还是又丑又难用的 Waline)
这个项目的开发差不多花了一个月的时间,我平时下班后如果有空就会稍微写点。(注意是下班哦,我上班可是兢兢业业干满 8 小时+,恨不得住在鹅厂)由于开发时间不连贯,再加上有时回到家里比较困脑子不清醒,经常会出现后一天否定前一天的设计的情况。最后磕磕绊绊总算是完成了!由于是纯属为满足自己的需求,再加上我对它后端字段的校验还没统一梳理测试过,我目前并不会把这个站向公众开放。而像这种二开一下就能拿去恰烂钱的东西,我当然也更不会开源。
总的来说,Sayrud 也算是圆了自己当年 18 岁时的梦,将自己当时想得东西给做出来了。你可能注意到这个项目的名字也颇耐人寻味,Say - RDU 是 CRUD 的谐音,这其实也代表着我对这个项目未来的规划。嘻嘻😝
如有侵权请联系:admin#unsafe.sh