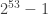
2024-7-22 06:6:3 Author: modexp.wordpress.com(查看原文) 阅读量:24 收藏
Table Of Contents
- Introduction
- Symmetric vs Asymmetric
- History
- Diffie-Hellman Key Exchange
- Crypto API
- Binary Exponentiation Methods
- Arbitrary-precision Arithmetic
- Addition
- Subtraction
- Multiplication
- Division
- Exponentiation
- Modular Multiplicative Inverse
- Modular Addition
- Modular Multiplication
- Modular Exponentiation
- Counting Bits
- Comparing
- Bignum Implementation
- 32-bit x86 Assembly Implementation
Appendix
1. Introduction
The first issue of Bruce Schneier’s monthly Crypto-Gram internet newsletter was published on May 15th, 1998. It includes an article called The Secret Story of Non-Secret Encryption that provides some background into the early development of asymmetric encryption like Diffie-Hellman key exchange and RSA encryption. After reading it again recently, I decided to restore an old blog post that was originally published in 2015 about Modular Exponentiation, a function that’s important for classical asymmetric crypto.
Two assembly libraries were particularly helpful for understanding the implementation aspect. One is the RSA library published in 2000 by Z0MBiE/29A that he discussed in “RSA for the programmer”. It can be used for verification of RSA digital signatures, encryption and key exchange. Another helpful source is the BN library by Drizz. There are definitely other sources I found helpful that have since become very difficult nowadays to find online sadly.
Another paper which served as a baseline is An Encrypted Payload Protocol and Target-Side Scripting Engine by Dino Dai Zovi. The author of that paper used ElGamal key exchange which is closer to RSA key exchange than Diffie-Hellman.
NOTE: Some of the LaTeX included here doesn’t render correctly in WordPress. It renders fine in a browser using HTML and the MathJax extension. Unfortunately it runs off the page here.
2. Symmetric vs Asymmetric
For those who don’t know, there are two main types of encryption: symmetric and asymmetric. The former depends on a pre-shared secret to protect messages while the latter uses key pairs: a public and private key. For RSA encryption, the public key is used to encrypt while the private key is used to decrypt. The same process applies to the signing and verification of digital signatures. Here’s a more detailed list of steps how they both work:
2.1 Encryption with RSA
- Alice wants to send a confidential message to Bob. She encrypts the message using Bob’s public key.
- Bob receives the encrypted message and decrypts it using his private key.
In this scenario, only Bob can decrypt the message because only he has the private key that corresponds to his public key.
2.2 Digital Signatures with RSA
- Alice wants to send a message to Bob and ensure he knows it came from her. She generates a cryptographically secure hash of the original message.
- Alice encrypts this hash with her private key to create a digital signature.
- Alice sends the original message and the digital signature to Bob.
To authenticate the message:
- Bob generates a hash of the received message.
- Bob decrypts the digital signature using Alice’s public key.
- Bob compares the decrypted hash with the generated hash. If they match, the message is authenticated as being from Alice and has not been altered.
In classical cryptography, Modular Exponentiation is the one-way function used for encrypting and decrypting messages. When implemented correctly, it makes algorithms such as Diffie-Hellman (DH) key exchange and RSA encryption secure. The security of DH depends on the difficulty of solving the “>Discrete Logarithm Problem (DLP), while RSA depends on the difficulty of factoring large composite numbers that are the product of two large primes.
Books that go into more detail include the Crypto101 book and Handbook of Applied Cryptography. I intended to discuss both classical and elliptic curve as part of a small update, but the latter will now be discussed in a follow up to this.
3. History
The story begins in the 60’s. The management of vast quantities of key material needed for secure communication was a headache for the armed forces. It was obvious to everyone, including me, that no secure communication was possible without secret key, some other secret knowledge, or at least some way in which the recipient was in a different position from an interceptor. After all, if they were in identical situations how could one possibly be able to receive what the other could not? Thus there was no incentive to look for something so clearly impossible. – James H. Ellis, 1997
Before computers and the internet, cryptography was mainly used by the military and intelligence agencies. Therefore, it’s not surprising the idea of public key exchange was first conceived by people working in those fields. The Story Of Non-Secret Encryption published in 1997 by James Ellis documents early research by GCHQ employees into what we now refer to as Public Key Cryptography. Below is a list of papers/reports referenced in it.
| paper/report | authors | date |
|---|---|---|
| Final Report on Project C43 | Bell Telephone Laboratory | 1944 |
| The Possibility of Secure Non-Secret Digital Encryption | James H. Ellis (GCHQ) | January 1970 |
| A Note on Non-Secret Encryption | Clifford C. Cocks (GCHQ) | November 1973 |
| Non-Secret Encryption Using a Finite Field | Malcolm J. Williamson (GCHQ) | January 1974 |
| Thoughts on Cheaper Non-Secret Encryption | Malcolm J. Williamson (GCHQ) | August 1976 |
| New Directions in Cryptography | Whitfield Diffie and Martin E. Hellman | November 1976 |
| A Method for Obtaining Digital Signatures and Public-key Cryptosystems | Ron L. Rivest, A. Shamir, L. Adleman | February 1978 |
Inspired by the Project C43 report, Ellis conceived the idea of Non-Secret Encryption (NSE) in the late 1960s and formally documented his thoughts in 1970 while working at GCHQ. There was no practical solution at the time and it wasn’t until 1973 when another cryptographer and mathematician working at GCHQ by the name of Clifford Cocks provided a mathematical proof of concept. This was classified until the death of Ellis in 1997. Publicly of course, the concept of non-secret encryption was first proposed by Ralph Merkle in his 1974 paper Secure Communications over Insecure Channels. This later became the basis of the Diffie-Hellman key exchange protocol described by Whitfield Diffie and Martin Hellman in their paper New Directions In Cryptography. Another GCHQ cryptographer Malcolm J. Williamson wrote about the same key exchange algorithm three months before the publication of the Diffie-Hellman paper. According to Ellis, the algorithms were identical with the only difference was that DH restricted q to be prime.
4. Diffie-Hellman Key Exchange
The following outlines each step of the protocol.
And the following is Python code to demonstrate. This is only for illustration. A 768-bit prime is okay to withstand attacks from a desktop computer but not from a cluster of computers working in parallel.
import secrets
# Oakley Group 1 parameters (768-bit MODP Group)
# Prime number (p)
p = int(
"FFFFFFFFFFFFFFFFC90FDAA22168C234C4C6628B80DC1CD1"
"29024E088A67CC74020BBEA63B139B22514A08798E3404DD"
"EF9519B3CD3A431B302B0A6DF25F14374FE1356D6D51C245"
"E485B576625E7EC6F44C42E9A63A3620FFFFFFFFFFFFFFFF", 16)
# Generator (g)
g = 2
# Generate private key
def generate_private_key():
return secrets.randbelow(p)
# Generate public key
def generate_public_key(private_key):
return pow(g, private_key, p)
# Compute shared secret
def compute_shared_secret(received_public_key, private_key):
return pow(received_public_key, private_key, p)
# Diffie-Hellman Key Exchange
def diffie_hellman():
# Alice's keys
alice_private_key = generate_private_key()
alice_public_key = generate_public_key(alice_private_key)
# Bob's keys
bob_private_key = generate_private_key()
bob_public_key = generate_public_key(bob_private_key)
# Exchange public keys and compute shared secrets
alice_shared_secret = compute_shared_secret(bob_public_key, alice_private_key)
bob_shared_secret = compute_shared_secret(alice_public_key, bob_private_key)
# Both shared secrets should be the same
assert alice_shared_secret == bob_shared_secret
return alice_shared_secret
As you can see, implementation is relatively simple. The pow() function is performing the encryption and decryption.
5. Windows Crypto API
Initially, Windows API was examined and it provides at least two official ways: RSA or Diffie-Hellman. These both use Crypto API or the more recent upgrade introduced in Vista. The following is merely an example of how to use legacy Crypto API to perform DH key exchange in C on Windows. Again, it’s using a 768-bit key which isn’t recommended for anything serious.
#include <windows.h>
#include <wincrypt.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#pragma comment(lib, "advapi32")
#define MAX_DH_KEY_BITS 768
#define MAX_DH_KEY_BYTES (MAX_DH_KEY_BITS/8)
BYTE
oakley_modp_768_p[MAX_DH_KEY_BYTES] = {
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0x20, 0x36, 0x3A, 0xA6, 0xE9, 0x42, 0x4C, 0xF4,
0xC6, 0x7E, 0x5E, 0x62, 0x76, 0xB5, 0x85, 0xE4,
0x45, 0xC2, 0x51, 0x6D, 0x6D, 0x35, 0xE1, 0x4F,
0x37, 0x14, 0x5F, 0xF2, 0x6D, 0x0A, 0x2B, 0x30,
0x1B, 0x43, 0x3A, 0xCD, 0xB3, 0x19, 0x95, 0xEF,
0xDD, 0x04, 0x34, 0x8E, 0x79, 0x08, 0x4A, 0x51,
0x22, 0x9B, 0x13, 0x3B, 0xA6, 0xBE, 0x0B, 0x02,
0x74, 0xCC, 0x67, 0x8A, 0x08, 0x4E, 0x02, 0x29,
0xD1, 0x1C, 0xDC, 0x80, 0x8B, 0x62, 0xC6, 0xC4,
0x34, 0xC2, 0x68, 0x21, 0xA2, 0xDA, 0x0F, 0xC9,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF
};
BYTE oakley_modp_g[MAX_DH_KEY_BYTES] = { 2 };
typedef struct DH_ctx {
PBYTE pubKey;
DWORD pubLen;
DATA_BLOB P, G;
HCRYPTPROV hProvider;
HCRYPTKEY hPrivate, hSession;
DWORD dwKeyLen;
ALG_ID aiEncryption;
} DH_ctx;
void
init_ctx(DH_ctx *c) {
c->aiEncryption = CALG_RC4;
c->dwKeyLen = MAX_DH_KEY_BITS;
CryptAcquireContext(
&c->hProvider,
NULL,
MS_ENH_DSS_DH_PROV,
PROV_DSS_DH,
CRYPT_VERIFYCONTEXT | CRYPT_SILENT);
// create a private key
CryptGenKey(
c->hProvider,
CALG_DH_EPHEM,
c->dwKeyLen << 16 | CRYPT_EXPORTABLE | CRYPT_PREGEN,
&c->hPrivate);
// set p prime
c->P.pbData = oakley_modp_768_p;
c->P.cbData = sizeof(oakley_modp_768_p);
CryptSetKeyParam(c->hPrivate, KP_P, (PBYTE)&c->P, 0);
// set g generator
c->G.pbData = oakley_modp_g;
c->G.cbData = sizeof(oakley_modp_g);
CryptSetKeyParam(c->hPrivate, KP_G, (PBYTE)&c->G, 0);
}
void
destroy_ctx(DH_ctx* c) {
if (c->pubKey) free(c->pubKey);
if (c->hSession) CryptDestroyKey(c->hSession);
if (c->hPrivate) CryptDestroyKey(c->hPrivate);
if (c->hProvider) CryptReleaseContext(c->hProvider, 0);
}
// generate a public key and export as public key blob
void
getPublicKey(DH_ctx* c) {
CryptSetKeyParam(c->hPrivate, KP_X, NULL, 0);
CryptExportKey(c->hPrivate, 0, PUBLICKEYBLOB, 0, NULL, &c->pubLen);
c->pubKey = (PBYTE)malloc(c->pubLen);
CryptExportKey(c->hPrivate, 0, PUBLICKEYBLOB, 0, c->pubKey, &c->pubLen);
}
// import public key from remote user and set session key for encryption + decryption
void
setSessionKey(DH_ctx* c, const BYTE* pbData, DWORD dwDataLen) {
// import public key and create session key
CryptImportKey(
c->hProvider,
pbData,
dwDataLen,
c->hPrivate,
0,
&c->hSession);
// set encryption algorithm
CryptSetKeyParam(
c->hSession,
KP_ALGID,
(PBYTE)&c->aiEncryption,
0);
}
// encrypt using session key
BOOL
encrypt(
DH_ctx* c,
const PBYTE pbInData,
DWORD dwInDataLen,
PBYTE* pbOutData,
PDWORD dwOutDataLen)
{
// allocate buffer for ciphertext
DWORD len = dwInDataLen;
PBYTE buf = (PBYTE)malloc(len + 32);
// copy plaintext to buffer
memcpy(buf, pbInData, dwInDataLen);
// encrypt in place
BOOL res = CryptEncrypt(c->hSession, 0, TRUE, 0, buf, &len, len + 32);
*dwOutDataLen = len;
*pbOutData = buf;
return res;
}
// decrypt using session key.
BOOL
decrypt(DH_ctx* c, PBYTE pbData, PDWORD dwDataLen) {
return CryptDecrypt(c->hSession, 0, TRUE, 0, pbData, dwDataLen);
}
int
main() {
DH_ctx bob={0},alice={0};
init_ctx(&bob);
init_ctx(&alice);
// get a public key for Alice
getPublicKey(&alice);
// get a public key for Bob
getPublicKey(&bob);
//
// Alice and Bob exchange public keys over communication channel.
//
// Alice imports public key from Bob to create session key.
setSessionKey(&alice, bob.pubKey, bob.pubLen);
// Bob imports public key from Alice to create session key.
setSessionKey(&bob, alice.pubKey, alice.pubLen);
//
// Alice and Bob can now encrypt and decrypt messages between each other.
//
BYTE inbuf[] = "Hello, world!";
DWORD inlen = sizeof(inbuf);
PBYTE enc = NULL;
DWORD enclen;
BOOL res = FALSE;
do {
if (!encrypt(&alice, inbuf, inlen, &enc, &enclen)) {
printf("Encryption failed...\n"); break;
}
if (!decrypt(&bob, enc, &enclen)) {
printf("Decryption failed...\n"); break;
}
res = TRUE;
} while(0);
printf("Server successfully decrypted message from client: %s\n", res ? "OK" : "FAILED");
if(enc) free(enc);
destroy_ctx(&bob);
destroy_ctx&alice);
return 0;
}
6. Binary Exponentiation Methods
Modular exponentiation is essentially a process of repeated multiplications within a finite range. When writing shellcode, our goal is to implement something with the least amount of code while maintaining a balance between size with speed to ensure it’s still useful. Here are some methods to consider before writing an implementation:
The last one in the list is simply a right-to-left method with both exponentiation and multiplication combined.
At this point, it’s important to be aware of the limits to the prototype functions. Given that we’re using 32-bit integers for the base, exponent, and modulus, overflows can occur depending on the input values. To avoid generating incorrect results, we need to ensure the modulus m does not exceed 
![[1,m]](https://s0.wp.com/latex.php?latex=%5B1%2Cm%5D&bg=ffffff&fg=333333&s=0&c=20201002)

6.1 Direct method
This is the simplest and requires the least amount of code. It’s also the slowest. It’s fine for a toy implementation of RSA where the exponent is really low like 3 or 65537.
uint32_t
modexp(uint32_t b, uint32_t e, uint32_t m) {
uint32_t r = 1;
while (e--) {
r = r * b % m;
}
return r;
}
The following is just to illustrate implementation in 32-bit x86 assembly. It could probably be used for some type of obfuscation.
mov ecx, [esp+8] ; ecx = e
xor edx, edx ; r = 1
inc edx
jecxz mxp_exit ; while(e)
mxp_loop:
imul edx, [esp+4] ; r *= b
mov eax, edx ;
xor edx, edx ;
div dword[esp+12] ; r /= m
sub ecx, 1 ; e--
jne mxp_loop
mxp_exit:
xchg eax, edx
ret
6.2 Recursive
This is a divide-and-conquer approach. It works fine for 32-bit integers, but I’ve not implemented for anything else mainly because it uses a lot of stack. Recursive functions tend to eat up a lot of stack, specially when you’re dealing with large numbers.
uint32_t
modmul_r(uint32_t a, uint32_t b, uint32_t m) {
uint32_t r = 0;
if (b) {
r = modmul_r(a, b >> 1, m);
r = addmod(r, r, m);
if (b & 1) {
r = addmod(r, a, m);
}
}
return r;
}
uint32_t
modexp_r(uint32_t b, uint32_t e, uint32_t m) {
uint32_t r = 1;
if (e) {
r = modexp_r(b, e >> 1, m);
r = modmul_r(r, r, m);
if (e & 1) {
r = modmul_r(r, b, m);
}
}
return r;
}
6.3 Left-to-right
Processes bits of the exponent from the Most Significant Bit (MSB) to the Least Significant Bit (LSB).
uint32_t
mulmod_l2r(uint32_t a, uint32_t b, uint32_t m) {
uint32_t r = 0;
int i = 32 - 1;
do {
r = addmod(r, r, m);
if (_bittest(&b, i)) {
r = addmod(r, a, m);
}
} while(--i >= 0);
return r;
}
uint32_t
modexp_l2r(uint32_t b, uint32_t e, uint32_t m) {
uint32_t r = 1;
int i = 32 - 1;
do {
r = mulmod_l2r(r, r, m);
if (_bittest(&b, i)) {
r = mulmod_l2r(r, b, m);
}
} while (--i >= 0);
return r;
}
6.4 Right-to-left
Processes bits of the exponent from the Least Significant Bit (LSB) to the Most Significant Bit (MSB).
uint32_t
mulmod_r2l(uint32_t a, uint32_t b, uint32_t m) {
uint32_t r = 0;
for (int i=0; i<32; i++) {
if (_bittest(&b, i)) {
r = addmod(r, a, m);
}
a = addmod(a, a, m);
}
return r;
}
uint32_t
modexp_r2l(uint32_t b, uint32_t e, uint32_t m) {
uint32_t r = 1;
for (int i=0; i<32; i++) {
if (_bittest(&e, i)) {
r = mulmod_r2l(r, b, m);
}
b = mulmod_r2l(b, b, m);
}
return r;
}
6.5 Z0MBiE Right-to-left and Left-to-right
Z0MBiE used a right-to-left method for the exponentiation and left-to-right for multiplication. The following is just a prototype version of the assembly code for anyone interested. The reason for using less than or equals in the z_modexp loop is because bitscan returns the i’th bit instead of i + 1. A left shift is used in z_mulmod for r but addition works too.
int
bitscan(uint32_t x) {
for (int i = 32-1; i>=0; i--) {
if (_bittest(&x, i)) return i;
}
return 0;
}
// left-to-right
uint32_t
z_mulmod(uint32_t a, uint32_t b, uint32_t m) {
uint32_t r = 0;
int i = bitscan(b);
do {
r = r << 1;
if (r >= m) r -= m;
if (_bittest(&b, i)) {
r += a;
if (r >= m) r -= m;
}
} while(--i >= 0);
return r;
}
// right-to-left
uint32_t
z_modexp(uint32_t b, uint32_t e, uint32_t m) {
uint32_t r = 1;
int msb = bitscan(b);
for (int i=0; i <= msb; i++) {
if (_bittest(&e, i)) {
r = z_mulmod(r, b, m);
}
b = z_mulmod(b, b, m);
}
return r;
}
6.6 Combining Right-to-left
Based on the similarities, it’s possible to combine exponentiation and multiplication into one function. A flag parameter will indicate whether addition or multiplication should be used. If we’re not concerned about the speed of the code, we can also fix the size of integers to 32-bits which results in a slower function but one that still works in practice.
We only call modexp once. Every other call afterwards is for mulmod which invokes addmod. This is what’s used for the assembly implementation.
uint32_t
addmod(uint32_t a, uint32_t b, uint32_t m) {
uint32_t r = a + b;
if (r >= m) {
r -= m;
}
return r;
}
uint32_t
modx_r2l(uint32_t b, uint32_t e, uint32_t m, int x) {
uint32_t r = x;
for (int i=0; i<32; i++) {
if (_bittest(&e, i)) {
r = x ? modx_l2r(r, b, m, 0) : addmod(r, b, m);
}
b = x ? modx_r2l(b, b, m, 0) : addmod(b, b, m);
}
return r;
}
7. Arbitrary-precision Arithmetic
Most programming languages provide basic operators for addition, subtraction, division, and multiplication, which work well within a certain numerical range. Some languages such as Python inherently support arbitrary-precision integers. However, If you need the same support in assembly, you’ll need to use a third-party library or develop a custom implementation of your own. Here, we’re going to look at what’s required to perform arithmetic on numbers of arbitrary range in x86 assembly. There will be some optimisations in examples, but that’s largely an excerise left up to the reader.
7.1 Addition
If you’ve ever been asked to perform addition without an add operator (probably never), you can use a combination of bitwise-AND, XOR and left shift. The only reason I’ve included it here is because we’ll be using similar binary arithmetic in the coming examples. The only time I’ve seen this used in software is when obfuscating code. It’s more familiar for hardware programmers where addition isn’t supported.
uint32_t
add(uint32_t a, uint32_t b) {
uint32_t c = 0;
while (b) {
c = a & b;
a = a ^ b;
b = c << 1;
}
return a;
}
Here’s the assembly for reference.
%define a eax
%define b ecx
%define c edx
add32:
_add32:
mov a, [esp+4] ; edx = a
mov b, [esp+8] ; ecx = b
jecxz add_exit
add_main:
; c = a & b
mov c, a
and c, b ; isolate msb
; a ^= b
xor a, b
; b = c << 1;
mov b, c
shl b, 1
jnz add_main
add_exit:
ret
Of course, it’s fine to use the Add With Carry (ADC) instruction in software. I’ll be showing binary versions of multiplication and division too as it will be necessary to implement modular versions. The following is a function that calculates the sum of two numbers (a and b) using ADC.
; void bn_add(int bits, void *r, void *a, void *b);
bn_add:
pushad
mov edi, [esp+32+ 4] ; edi = r
mov esi, [esp+32+ 8] ; esi = a
mov ebx, [esp+32+12] ; ebx = b
shr ecx, 5 ; /= 32 (input bits need aligned by 32-bits)
clc ; CF=0
add_loop:
lodsd ; eax = a[i]
adc eax, [ebx] ; eax = eax + b[i] + carry
stosd ; r[i] = eax
lea ebx, [ebx + 4] ; advance b
loop add_loop ;
ret
Converting the above code to 64-bit is possible with some minor changes. To avoid using legacy instructions such as LODSD, STOSD and LOOP, you might consider using another register to hold the carry flag and set it using SETC or ADC. You can potentially use SAHF and LAHF but those are considered legacy instructions too.
7.2 Subtraction
Subtraction is essentially the same as addition except we complement one of the addends and the product.
uint32_t
sub32(uint32_t x, uint32_t y) {
return ~add32(~x, y);
}
And here’s the assembly for reference.
%define a eax
%define b ecx
%define c edx
sub32:
_sub32:
mov a, [esp+4] ; edx = = ~a
not a ;
mov b, [esp+8] ; ecx = b
jecxz sub_exit
sub_main:
; c = a & b
mov c, a
and c, b ; isolate msb
; a ^= b
xor a, b
; b = c << 1;
mov b, c
shl b, 1
jnz sub_main
sub_exit:
not a ; return ~a
ret
SUB is used in most cases but SBB (Subtract with Borrow) similar to ADC is needed for arbitrary numbers.
; void bn_sub(int bits, void *r, void *a, void *b);
bn_sub:
pushad
mov edi, [esp+32+ 4] ; edi = r
mov esi, [esp+32+ 8] ; esi = a
mov ebx, [esp+32+12] ; ebx = b
shr ecx, 5 ; /= 32
clc ; CF = 0
sub_loop:
lodsd ; eax = a[i]
sbb eax, [ebx] ; eax = eax - b[i] - CF
stosd ; r[i] = eax
lea ebx, [ebx + 4] ; advance b
loop sub_loop ;
ret
7.3 Multiplication
We don’t need ordinary multiplication for modexp, but I thought it might useful to show both. In the following example is a binary version where a implies the multiplicand and b implies the multiplier.
uint32_t
mult1(uint32_t a, uint32_t b) {
uint32_t r = 0;
while(b) {
if (b & 1) {
r = r + a;
}
a = a + a;
b >>= 1;
}
return r;
}
The only difference in the next version is that we use the BT instruction to test all 32-bits of the multiplier. It still generates the same result because r is only updated if a bit of the multiplier is set. At worst, this performs redundant additions and makes it less efficient. The only reason you might use something like this is to avoid having to obtain the MSB of the multiplier and save a little space at the expense of speed. Or maybe you can use it to waste CPU cycles too?
uint32_t
mult2(uint32_t a, uint32_t b) {
uint32_t r = 0;
int cnt = 0;
for (int i=0; i<32; i++) {
if (_bittest((int*)&b, i)) {
r = r + a;
}
a = a + a;
}
return r;
}
In the following, the right shift will set the carry flag. If the bit was set, the subtract with borrow then sets EBX to -1 or 0 if it wasn’t. The bitwise AND will either read or ignore bits in EDX before adding 0 or EDX to EAX. In more recent ISA, SHLX and SHRX won’t affect the flags. Something to consider.
%define a ecx
%define b edx
%define r eax
%define t ebx
mult32:
_mult32:
mov a, [esp+4] ; ecx = a
mov b, [esp+8] ; edx = b
push t
xor r, r ; r = 0;
mul_main:
jecxz exit_mul ; while (a)
shr a, 1 ; cf = (a >>= 1)
sbb t, t ; t = (cf) ? -1 : 0
and t, b ; t = (cf != 0) b : 0
add r, t ; r += (cf ? b : 0);
add b, b ; b <<= 1;
jmp mul_main
exit_mul:
pop t
ret
The while condition is executed after mul_main here. Unless the carry flag is set by the right shift, nothing is actually added to r, so it’s perfectly fine.
When working with big numbers, the following is example of multiplying 1024-bit numbers.
#define NUM_WORDS 32 // 1024-bits
void multiply(uint32_t *r, uint32_t *a, uint32_t *b) {
memset(result, 0, NUM_WORDS * 2 * sizeof(uint32_t));
for (int i = 0; i < NUM_WORDS; ++i) {
uint64_t carry = 0;
for (int j = 0; j < NUM_WORDS; ++j) {
uint64_t product = (uint64_t)a[i] * b[j] + result[i + j] + carry;
result[i + j] = (uint32_t)product;
carry = product >> 32;
}
result[i + NUM_WORDS] = (uint32_t)carry;
}
}
And the following is for multiplying numbers of arbitrary size. This won’t be used for modexp, but it’s still worth showing how it works.
;
; void multiply(int bits, void *r, void *a, void *b);
;
multiply:
_multiply:
pushad
xor eax, eax
mov ecx, [esp + 32+4] ; bits
shr ecx, 3 ; /= 8
push ecx ; save bytes on stack
mov edi, [esp + 32+8+4] ; r
rep stosb ; memset(r, 0, bytes);
mov edi, [esp + 32+16+4] ; edi = b
xor esi, esi ; i = 0
mul_main:
mov eax, [esp + 32+8+4] ; eax = r
xor ecx, ecx ; carry = 0
xor ebp, ebp ; j = 0
lea ebx, [eax + esi] ; ebx = r[i]
mul_loop:
mov eax, [esp + 32+12+4] ; eax = a
mov eax, [eax + esi] ; eax = a[i]
mul dword[edi + ebp] ; edx:eax = a[i] * b[j]
add ecx, eax ;
adc edx, 0 ; save carry
add [ebx + ebp], ecx ; r[i + j] += carry
mov ecx, edx ; carry = edx
adc ecx, 0 ; save carry
add ebp, 4 ; j++
cmp ebp, [esp] ; j < bytes
jb mul_loop
mov eax, [esp + 32+8+4] ; eax = r
add eax, [esp] ; r += bytes
mov [eax + esi], ecx ; save carry
add esi, 4 ; i++
cmp esi, [esp] ; i < bytes
jb mul_main
pop eax
popad
ret
7.4 Division
Although division is not used for key exchange itself, the modulo operation in steps 4 and 5 is very similar to what’s used for modular addition. To optimise the code, this would first find the MSB of N (numerator) so that we can save some CPU cycles.
void
divmod(uint32_t N, uint32_t D, uint32_t *q_out, uint32_t *r_out) {
uint32_t r=0, q=0;
// 1. For 32-bits
for (int i=31; i>=0; i--) {
// 2. Is i'th bit set for N?
uint8_t cf = _bittest((const int*)&N, i);
// 3. Double remainder plus carry
r = (r << 1) + cf;
// 4. If remainder exceeds divisor
if (r >= D) {
// 5. Subtract
r = r - D;
// 6. Add 1 to quotient
_bittestandset((int*)&q, i);
}
}
// 7. Return remainder and quotient
*q_out = q;
*r_out = r;
}
Converting the above to handle 32-bit integers, we have something like this:
;
; void divmod32(uint32_t N, uint32_t D, uint32_t *r_out, uint32_t *q_out);
;
divmod32:
_divmod32:
%define N ebx
%define D ebp
%define i ecx
%define r eax
%define q edx
%define r_out esi
%define q_out edi
pushad
mov N, [esp+32+4] ; N = Numerator or dividend
mov D, [esp+32+8] ; D = Denominator or divisor
mov q_out, [esp+32+12]
mov r_out, [esp+32+16]
xor r, r ; r = 0;
xor q, q ; q = 0;
push 32 ; only performs 32-bit division
pop i
div_main:
dec i ; --i;
js div_exit ; i >= 0;
bt N, i ; _bittest((const int*)&N, i);
rcl r, 1 ; r = ((r << 1) + cf);
cmp r, D ; if(r >= D)
jb div_main
sub r, D ; r -= D;
bts q, i ; _bittestandset((int*)&q, i);
jmp div_main
div_exit:
mov [q_out], q
mov [r_out], r
popad
ret
And then converting this to 32-bit assembly so it handles arbitrary numbers, we have:
; ecx = Total bits
; eax = Buffer for remainder
; edx = Buffer for quotient
; esi = N = Numerator or dividend
; edi = D = Denominator or divisor
divmod:
_divmod:
pushad
lea ebp, [ecx - 1] ; ebp = total bits minus 1
shr ecx, 3 ; get number of bytes.
mov ebx, ecx
; r = 0
mov edi, eax ; edi = r
xor eax, eax ; eax = 0
rep stosb
; q = 0
mov edi, edx ; edi = q
mov ecx, ebx ; ecx = words
rep stosb
dm_main:
; 2. Is i'th bit set for N?
mov eax, [esp+pushad_t._esi] ; eax = N
bt [eax], ebp ; _bittest((const int*)&N, i);
; 3. Double remainder plus carry
mov ecx, ebx ; ecx = words
mov edi, [esp+pushad_t._eax] ; edi = r
push edi
dm_dbl:
rcl byte[edi], 1 ; r[i] <<= 1;
lea edi, [edi+1]
loop dm_dbl
pop edi
; 4. If remainder exceeds divisor.
mov ecx, ebx
mov esi, [esp+pushad_t._edi] ; esi = D
dm_cmp:
mov al, [edi+ecx-1] ; r[i]
cmp al, [esi+ecx-1] ; D[i]
loope dm_cmp ; while equal
jb dm_end ; jump to dm_end if r is less than D
; 5. Subtract D
mov ecx, ebx
dm_sub:
mov al, [edi] ; t = r[i]
sbb al, [esi] ; t -= D[i]
stosb ; r[i] = t
lodsb ; advance D
loop dm_sub ; for number of words
; 6. Add 1 to quotient
bts [edx], ebp ; _bittestandset((int*)&q, i);
dm_end:
dec ebp ; --i
jns dm_main ; while i is greater than or equal to total bits
popad
ret
The main thing to focus on is step 3 where the remainder is multiplied by 2 and step 3 where if the remainder exceeds the divisor, we subtract it and update the quotient. But as you’ll see in mulmod, instead of using RCL, we use ADC because it’s essentially performing the same operation and much more efficient than using them separately.
7.5 Exponentiation
The exp() function for C/C++ returns a float or a double. A float can hold integers up to 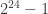

The first is a great tutorial on programming with the FPU by Raymond Filiatreault. It covers using floating point math on the x86 CPU really well. And although it hasn’t been updated since 2009, it’s still relevant today in 2024. Another excellent resource is from Agner Fog. who has been publishing information about code optimisation on the x86 platform for almost two decades. The following is a very basic implementation of exp() for 32-bit integers. Apart from the fact I can’t think of anything to use it for in encryption, I would not recommend using it in its current state.
uint32_t
exp(uint32_t b, uint32_t e) {
uint32_t r = 1;
while (e) {
if (e & 1) {
r = r * b;
}
b = b * b;
e >>= 1;
}
return r;
}
And to be consistent, here’s some assembly for reference. ECX and EDX should hold the base and exponent respectively.
exp_asm:
push 1 ; r = 1
pop eax
xchg ecx, edx
exp_main:
jecxz exp_exit ; while(e > 0)
shr ecx, 1 ; does: if(e & 1) and e >>= 1
jnc exp_sqr
imul eax, edx ; r = r * b
exp_sqr:
imul edx, edx ; b = b * b
jmp exp_main
exp_exit:
ret
7.6 Modular Multiplicative Inverse
One other function that’s used for RSA key generation but not Diffie-Hellman is the Extended Euclidean algorithm or XGCD as it’s sometimes called. To calculate the quotient and remainder, you can use divmod. For the multiplication, you have multiply(). And for the subtraction, you have bn_sub(). These are similar to what Z0MBiE used in his RSA library. What he does (correctly) at the end of the loop is check if the Most Significant Byte: If it’s 1, then the number is negative. If it’s 0, then the number is positive. Based on that, you add the modulus. Have a look at _modinv.inc in his library for a bignum implementation.
uint32_t
invmod(uint32_t a, uint32_t m) {
uint32_t j = 1, i = 0, b = m, c = a, x, y;
while (c) {
x = b / c; // Calculate quotient
y = b % c; // Calculate remainder
b = c; // Update b
c = y; // Update c to the remainder
y = j; // Store the old value of j
j = i - j * x; // Update j using the extended Euclidean formula
i = y; // Update i to the old value of j
}
if((int32_t)i < 0) {
i += m;
}
return i;
}
In this case, if you try reassign variable names, the code will not function correctly. I just wanted it to be easier to read and is not that disimilar to how a compiler might generate it.
%define a eax
%define x eax
%define y edx
%define b ebx
%define c ecx
%define i esi
%define j edi
%define m ebp
pushad
mov a, [esp+32+4] ; a = number
mov m, [esp+32+8] ; m = modulus
mov b, m
xor i, i ; i = 0
push 1 ; j = 1
pop j
inv_main:
jecxz inv_end ; while(c > 0)
; x = b / c;
; y = b % c;
xor y, y
mov x, b
div c
mov b, c ; b = c;
mov c, y ; c = y;
; t = i - x * j;
xor y, y
mul j
sub i, x
xchg i, j ; i = j, j = t
jmp inv_main
inv_end:
test i, i ; if((int)i < 0)
jge inv_exit ; signed compare
add i, m ; i += m
inv_exit:
mov [esp+28], i ; return i;
popad
ret
7.7 Modular Addition
In this example, subtracting the modulus from the sum of a and b is fine so long as a and b don’t overflow 32-bits. To prevent errors here, m should be at most 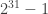
uint32_t
addmod(uint32_t a, uint32_t b, uint32_t m) {
uint32_t r = a + b;
if (r >= m) {
r -= m;
}
return r;
}
For an example in assembly, refer to divmod().
7.8 Modular Multiplication
This is repeated additions modulo m. Instead of using the modulo operator, we assume b, e and m are not going to result in an overflow and use subtraction instead.
uint32_t
mulmod (uint32_t b, uint32_t e, uint32_t m) {
uint32_t r = 0;
while (e > 0) {
if (e & 1) {
r = (r + b);
if (r >= m) r -= m;
}
b = (b + b);
if (b >= m) b -= m;
e >>= 1;
}
return r;
}
Instead of using the modulo operator, we check if r is equal to or exceeds m and subtract m if it is. It’s fine to do this so long as m is greater than both a and b, which they should be anyway for any type of cryptographic work.
%define r eax
%define e ecx
%define b edx
%define m ebp
%define t ebx
pushad
mov e, [esp+32+ 8] ; ecx = e
mov b, [esp+32+ 4] ; edx = b
mov m, [esp+32+12] ; ebp = m
xor r, r ; r = 0
mmd_main:
jecxz mmd_exit ; while (e)
shr e, 1 ; cf = (e & 1)
sbb t, t ; t = (cf) ? -1 : 0
and t, b ; t = (t != 0) ? b : 0
add r, t ; r += (cf ? b : 0);
cmp r, m ; if(r >= m)
jb mmd_L0
sub r, m ; r = r - m
mmd_L0:
add b, b ; b <<= 1;
cmp b, m ; if(b >= m)
jb mmd_main
sub b, m ; b = b - m
jmp mmd_main
mmd_exit:
mov [esp+28], r
popad
ret
7.9 Modular Exponentiation
This is used for a lot of cryptosystems, but it’s mainly famous for being used in RSA, DSA and Diffie-Hellman key exchange. The following is a toy implementation for 32-bit integers that simplies the reduction using subtraction. The following for example requires a modulus that doesn’t exceed
uint32_t
modexp (uint32_t b, uint32_t e, uint32_t m) {
uint32_t r = 1;
while (e) {
if (e & 1) {
uint64_t t = r * b;
while(t >= m) t -= m;
r = t;
}
uint64_t t = b * b;
while(t >= m) t -= m;
b = t;
e >>= 1;
}
return r;
}
We can’t use SBB like in modular multiplication because if no carry occurs, we’d calculate: r = r * 0.
%define r eax
%define e ecx
%define b edx
%define m ebp
modexp32:
_modexp32:
pushad
mov b, [esp+32+ 4]
mov e, [esp+32+ 8]
mov m, [esp+32+12]
push 1 ; r = 1;
pop r
mxp_main:
jecxz mxp_exit
shr e, 1 ; cf = (e & 1)
jnc mxp_L0
imul r, b ; r = r * b;
cmp r, m ; if (r >= m)
jb mxp_L0
sub r, m ; r = r - m;
mxp_L0:
imul b, b ; b = b * b;
cmp b, m ; if (b >= m)
jb mxp_main
sub b, m ; b = b - m;
jmp mxp_main ;
mxp_exit:
mov [esp+28], r
popad
ret
When you’re multiplying or dividing 32-bit integers, there’s always a risk of a result carrying over into 64-bits. This typically happens with unsigned 32-bit integers. In the previous example, it would work fine if the input was 32-bit integers and the registers were 64-bit. But because it’s both 32-bit integers and 32-bit registers, we really need to use unsigned multiplication and division to make sure the result is correct.
Just to be clear. IMUL and IDIV are only suitable for 32-bit signed multiplication and division unless the destination register is 64-bits.
%define r esi
%define e ecx
%define b ebx
%define m ebp
modexp32:
_modexp32:
pushad
mov b, [esp+32+ 4]
mov e, [esp+32+ 8]
mov m, [esp+32+12]
push 1 ; r = 1;
pop r
jecxz mxp_exit ; while(e)
mxp_main:
test e, 1 ; if (e & 1)
jz mxp_sqr
mov eax, r
mul b ; r = r * b
div m ; r /= m
mov r, edx ; save remainder
mxp_sqr:
mov eax, b ;
mul b ; b = b * b
div m ; b /= m
mov b, edx ; save remainder
shr e, 1 ; e >>= 1
jnz mxp_main
mxp_exit:
mov [esp+28], r
popad
ret
Just one more to show you why the value of b only matters when a bit of e is set. Every loop, the value of b is being multiplied modulo m. Let’s keep e, but set the number of bits to 32.
%define r esi
%define e ecx
%define b ebx
%define m ebp
%define i edi
; left-to-right
modexp32:
_modexp32:
pushad
mov b, [esp+32+ 4]
mov e, [esp+32+ 8]
mov m, [esp+32+12]
push 1 ; r = 1;
pop r
push 32 - 1 ; i = 32 - 1
pop i
mxp_main:
mov eax, r
mul r ; r = r * r
div m ; r /= m
mov r, edx ; save remainder
bt e, i ; if (e & i)
jnc mxp_end
mov eax, r ;
mul b ; r = r * b
div m ; r /= m
mov r, edx ; save remainder
mxp_end:
dec i ; i--
jns mxp_main ; while (i >= 0)
mxp_exit:
mov [esp+28], r
popad
ret
One more. We can free up eax and edx used for unsigned multiplication and division. The right-to-left method is used here.
%define r esi
%define i edi
%define b ecx
%define e ebx
%define m ebp
; eax and edx are used by mul and div
; right-to-left method with carry flag
pushad
mov b, [esp+32+ 4] ; base
mov e, [esp+32+ 8] ; exponent
mov m, [esp+32+12] ; modulus
push 1 ; r = 1;
pop r
xor i, i ; i = 0
mxp_main:
bt e, i ; if (e & i)
mxp_call:
pushfd ; save CF
mov eax, b ; select b if no carry (b = mulmod(b, b, m))
cmovc eax, r ; select r if carry (r = mulmod(r, b, m))
mul b ; eax = (cf ? r : b) * b
div m ; eax /= m
popfd ; restore CF
; in the bignum version, the next two instructions aren't required.
cmovnc b, edx ; save remainder if no carry
cmovc r, edx ; save remainder if carry
cmc ; flip CF
jnc mxp_call ; repeat until CF == 1
inc i ; i++
cmp i, 32
jnz mxp_main ; i < 32
mxp_exit:
mov [esp+28], r ; return r in eax
popad
ret
7.10 Counting Bits
You’ll notice in some of the previous examples the size of an integer is fixed to a numerical range. This is good if you want to reduce the amount code used, the complexity and remove dependency on dynamic memory allocation. But that can also be inefficient, so if you need to improve performance, it’s recommended to obtain the Most Significant Bit of an exponent or multiplier. This can be done a number of ways and we’ll only cover what’s relevant to assembly. Check bn_num_bits() in the C++ version for alternative.
Using Bit Scan Reverse (BSR), we need to set eax to -1 so that if the source operand is zero, eax remains -1. The increment at the end sets eax to zero which is the correct value to return.
mov ecx, [esp+4]
or eax, -1 ; eax = -1
bsr eax, ecx ; scan in reverse
inc eax ; eax++
ret
Another way to obtain the MSB is by using the LZCNT instruction. This is the preferred alternative to using BSR that has undefined behaviour.
LZCNT is an extension of the BSR instruction. The key difference is that LZCNT sets the destination to zero if the source operand is zero while in the case of the BSR instruction, if the source operand is zero, the content of destination operand is undefined (unless we set it). For processors that don’t support LZCNT, the instruction byte encoding is executed as BSR. 🙂
mov ecx, [esp+4] ;
lzcnt eax, ecx ; count leading zeros
neg eax ; eax = -eax
add eax, 32 ; eax += 32
ret
Here’s a poor version of using the instruction used for large arrays.
push ecx ; save number of bits on stack
shr ecx, 5 ; /= 32 to obtain number of words
cnt_loop:
lzcnt eax, dword[edx + 4 * ecx - 4] ; Count the Number of Leading Zero Bits
sub [esp], eax ; subtract count
cmp al, 32 ; 32 zeros?
loope cnt_loop ; while count is 32 and ecx is not zero
cnt_exit:
pop eax ; load remaining bits into eax
ret
The following is the simplest piece of assembly to obtain the MSB in an array. ecx should contain the maximum bits array can hold while edx should point to the array itself.
dec ecx ; minus 1 bit
cnt_loop:
bt [edx], ecx ; test bit at i position
jc cnt_exit ; bit set? exit
dec ecx ; decrease i position
jns cnt_loop ; continue until below zero
cnt_exit:
lea eax, [ecx + 1] ; add 1 to result
ret
The implementation by Z0MBiE used the BT instruction for finding the Most Significant Bit (MSB) in a large number. Surprisingly a lot of people prefer to use BSR or more recently LZCNT despite BT being more suitable. Certainly, BSR and LZCNT are fine for integers but for arrays, BT seems best. I’m aware BSR or LZCNT performs faster for smaller numbers.
7.11 Comparing
Start with the Most Significant bit, byte or word and move down to the Least Significant bit, byte or word. For now, refer to the divmod() function in assembly where comparing large numbers is required to calculate the quotient.
8. Bignum Implementation
It uses fixed-size buffers to simplify memory managment. Bear in mind, we need to avoid dynamic memory allocation much as possible in shellcode, so the implementation is fixed to support numbers no larger than 4096-bits. You can freely increase or decrease depending on what you want.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
#define BN_MAX_BITS 4096
#define BN_MAX_BYTES (BN_MAX_BITS / 8)
#define BN_MAX_WORDS (BN_MAX_BYTES / sizeof(uint32_t))
typedef union _bn_t {
uint8_t b[BN_MAX_BYTES];
uint32_t w[BN_MAX_WORDS];
} bn;
// test bit in x
int
bn_is_bit_set(bn *x, int bit_idx) {
return x->w[bit_idx >> 5] >> (bit_idx & 31) & 1;
}
// Find max bit in x
int
bn_num_bits(bn *x) {
int bits;
for (bits = BN_MAX_BITS - 1; bits >= 0; bits--) {
if (bn_is_bit_set(x, bits)) break;
}
return bits + 1;
}
// Zero initialize x
void
bn_zero(bn *x) {
memset(x->b, 0, BN_MAX_BYTES);
}
// copy s to d
void
bn_copy(bn *d, bn *s) {
memcpy(d->b, s->b, BN_MAX_BYTES);
}
// compare a and b
//
// return -1 if a < b
// return 1 if a > b
// return 0 if a == b
int
bn_cmp(bn *a, bn *b) {
int i;
for (i = BN_MAX_WORDS - 1; i >= 0; i--) {
if (a->w[i] < b->w[i]) return -1;
if (a->w[i] > b->w[i]) return 1;
}
return 0;
}
// add b to a and store in r
void
bn_add(bn *r, bn *a, bn *b) {
uint32_t i, carry = 0;
for (i = 0; i < BN_MAX_WORDS; i++) {
uint64_t sum = (uint64_t)a->w[i] + (uint64_t)b->w[i] + carry;
r->w[i] = (uint32_t)sum;
carry = sum >> 32;
}
}
// subtract b from a and store in r
void
bn_sub(bn *r, bn *a, bn *b) {
uint32_t i, borrow = 0;
for (i = 0; i < BN_MAX_WORDS; i++) {
uint64_t diff = (uint64_t)a->w[i] - (uint64_t)b->w[i] - borrow;
r->w[i] = diff;
borrow = (diff >> 63);
}
}
// modular addition where:
// 1) a, b and m are non-negative
// 2) a and b are less than m
void
bn_addmod(bn *r, bn *a, bn *b, bn *m) {
bn_add(r, a, b);
// greater than or equal to modulus?
if (bn_cmp(r, m) >= 0) {
// subtract from r
bn_sub(r, r, m);
}
}
// modular multiplication
void
bn_mulmod(bn *x, bn *b, bn *e, bn *m) {
int i, bits = bn_num_bits(e);
bn t, r;
bn_zero(&r);
bn_zero(&t);
bn_copy(&t, b);
for (i = 0; i < bits; i++) {
if (bn_is_bit_set(e, i)) {
bn_addmod(&r, &r, &t, m);
}
bn_addmod(&t, &t, &t, m);
}
bn_copy(x, &r);
}
// modular exponentiation
void
bn_modexp(bn *x, bn *b, bn *e, bn *m) {
int i, bits = bn_num_bits(e);
bn t, r;
bn_zero(&r); // initialize result to zero
bn_zero(&t); // same with t
bn_copy(&t, b); // copy b to t
r.w[0] = 1; // set result to 1
// for each bit of the exponent
for (i = 0; i < bits; i++) {
// is i-th bit set?
if (bn_is_bit_set(e, i)) {
bn_mulmod(&r, &r, &t, m);
}
bn_mulmod(&t, &t, &t, m);
}
bn_copy(x, &r);
}
The above code compiled with -Os and -O2 in MSVC or -O1 in GCC results in approx. 1200 bytes of code.
9. 32-bit x86 Assembly
Originally, the plan was to use purely assembly language for the shellcode. The modular exponentiation function started with Z0MBiE/29A’s implementation, which was approximately 250 bytes and was already optimized beyond what could be achieved in C.
The mulmod and addmod functions were implemented separately, and after a rewrite, the code was reduced to about 200 bytes. I then asked Peter Ferrie if he could try optimize it further. After some new revisions, we managed to reduce it by an additional 30 bytes. At that stage, there were no more obvious reductions to be made.
However, based on the binary exponentation methods described earlier, you can observe the logic utilised by both addmod and mulmod is very similar. By merging the two into a single function, we were able to reduce the code down to 134 bytes.
; -----------------------------------------------
; Modular Exponetiation in x86 assembly
;
; size: 134 bytes or 137 for slightly faster version
;
; global calls use cdecl convention
;
; -----------------------------------------------
;%define BYTES 1
bits 32
%ifndef BIN
global _modexp
global modexp
%endif
_modexp:
modexp:
pushad
lea esi, [esp+32+ 4]
lodsd
cdq
xchg ecx, eax ; ecx = max bytes
lodsd
push eax ; save base
lodsd
xchg ebx, eax ; ebx = exponent
lodsd
xchg ebp, eax ; ebp = modulus
lodsd
xchg edi, eax ; edi = result
pop esi ; esi = base
inc edx ; edx = x=1
db 0b0h ; mov al, 0x60 to mask pushad
mulmod:
pushad ; save registers
; cf=1 : r = mulmod (r, t, m);
; cf=0 : t = mulmod (t, t, m);
push edi ; save edi
; r=x
sub esp, ecx ; create space for r and assign x
; t=b
sub esp, ecx ; create space for t and assign b
mov edi, esp
push ecx
rep movsb
pop ecx
mov esi, esp
pushad
dec ecx ; skip 1
xchg eax, edx ; r=x
stosb
xor al, al ; zero remainder of buffer
rep stosb
popad
call ld_fn
; cf=1 : r = addmod (r, t, m);
; cf=0 : t = addmod (t, t, m);
; ebp : m
; esi : t
; edi : r or t
; ecx : size in bytes
;
addmod:
%ifndef BYTES
shr ecx, 2 ; /= 4
%endif
clc
pushad
am_l1:
%ifndef BYTES
lodsd
adc eax, [edi]
stosd
%else
lodsb
adc al, [edi]
stosb
%endif
loop am_l1
popad
mov esi, ebp
push ecx
dec ecx
am_l2:
%ifndef BYTES
mov eax, [edi+ecx*4]
cmp eax, [esi+ecx*4]
%else
mov al, [edi+ecx]
cmp al, [esi+ecx]
%endif
loope am_l2
pop ecx
jb am_l4
am_l3:
%ifndef BYTES
mov eax, [edi]
sbb eax, [esi]
stosd
lodsd
%else
mov al, [edi]
sbb al, [esi]
stosb
lodsb
%endif
loop am_l3
am_l4:
ret
; -----------------------------
ld_fn:
dec edx
js cntbits
sub dword[esp], addmod - mulmod
cntbits:
xor edx, edx
lea eax, [edx+ecx*8]
cnt_l1:
dec eax
jz xm_l1
bt [ebx], eax
jnc cnt_l1
xm_l1:
; if (e & 1)
bt [ebx], edx
xm_l2:
pushfd
pushad
cdq
cmovnc edi, esi ; if (cf==0) do t = xmod(t, t, m)
mov ebx, edi ; else r = xmod(r, t, m)
call dword[esp+32+4] ; invoke mulmod or addmod
popad
popfd
cmc
jnc xm_l2
inc edx
dec eax
jns xm_l1
; return r
mov esi, edi
lea esp, [esp+ecx*2+4]
pop edi
rep movsb
popad
ret
9.1 Test Unit
To verify it works, BN_mod_exp function from OpenSSL is used to compare the results of simple Diffie-Hellman key exchange. Included in this are two p values taken from More Modular Exponential (MODP) Diffie-Hellman groups for Internet Key Exchange (IKE)
// test unit for mx.asm
// requires openssl
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stdint.h>
#include <openssl/bn.h>
#include <openssl/rand.h>
#if defined(__GNUC__) && !defined(__clang__)
#define ALLOC_ON_CODE \
__attribute__((section(".text")))
#else
#define ALLOC_ON_CODE \
_Pragma("section(\".text\")") \
__declspec(allocate(".text"))
#endif
char OAKLEY_PRIME_MODP768[]=
"FFFFFFFFFFFFFFFFC90FDAA22168C234C4C6628B80DC1CD1"
"29024E088A67CC74020BBEA63B139B22514A08798E3404DD"
"EF9519B3CD3A431B302B0A6DF25F14374FE1356D6D51C245"
"E485B576625E7EC6F44C42E9A63A3620FFFFFFFFFFFFFFFF";
char OAKLEY_PRIME_MODP1024[]=
"FFFFFFFFFFFFFFFFC90FDAA22168C234C4C6628B80DC1CD1"
"29024E088A67CC74020BBEA63B139B22514A08798E3404DD"
"EF9519B3CD3A431B302B0A6DF25F14374FE1356D6D51C245"
"E485B576625E7EC6F44C42E9A637ED6B0BFF5CB6F406B7ED"
"EE386BFB5A899FA5AE9F24117C4B1FE649286651ECE65381"
"FFFFFFFFFFFFFFFF";
#define BN_LEN 1024 // should be enough for 2048-bits
// just to test modexp asm function
typedef struct _dh_t {
uint32_t maxbits;
uint32_t maxbytes;
// p + g group parameters
uint8_t p[BN_LEN];
uint8_t g[BN_LEN];
// private keys
uint8_t x[BN_LEN];
uint8_t y[BN_LEN];
// public keys
uint8_t A[BN_LEN];
uint8_t B[BN_LEN];
// session keys
uint8_t s1[BN_LEN];
uint8_t s2[BN_LEN];
} DH_T;
//
// Dump big number to console
//
void dump_bn (const char txt[], const void *buf, int len) {
printf("%s", txt);
for (int i=len-1; i>=0; i--) {
printf ("%02X", ((uint8_t*)buf)[i]);
}
}
//
// OpenSSL uses big-endian format so this is needed to convert
// to little-endian before passing to the x86 assembly code.
//
int
BN_bn2bin_le(const BIGNUM* bn, uint8_t* buffer, size_t buffer_len) {
// Get the length of the BIGNUM in bytes
int num_bytes = BN_num_bytes(bn);
// Check if the buffer is large enough to hold the result
if (buffer_len < num_bytes) {
return -1; // Buffer too small
}
// Allocate memory for the big-endian byte array
uint8_t* big_endian = (uint8_t*)malloc(num_bytes);
if (!big_endian) {
return -1; // Memory allocation failed
}
// Convert BIGNUM to big-endian byte array
BN_bn2bin(bn, big_endian);
// Reverse the big-endian byte array to get little-endian
for (int i = 0; i < num_bytes; ++i) {
buffer[i] = big_endian[num_bytes - 1 - i];
}
// Free the big-endian byte array
free(big_endian);
return num_bytes;
}
// Modular Exponentiation in x86 assembly.
// Byte order needs to be little-endian.
// OpenSSL uses bit-endian mode.
// b=base, e=exponent, m=modulus, r=result
typedef void (*modexp_t)(int maxbytes, void *b, void *e, void *m, void *r);
//void modexp(int maxbytes, void *b, void *e, void *m, void *r);
ALLOC_ON_CODE
uint8_t
mxp32[] = {
/* 0000 */ "\x60" /* pushal */
/* 0001 */ "\x8d\x74\x24\x24" /* lea esi, [esp + 0x24] */
/* 0005 */ "\xad" /* lodsd */
/* 0006 */ "\x99" /* cdq */
/* 0007 */ "\x91" /* xchg ecx, eax */
/* 0008 */ "\xad" /* lodsd */
/* 0009 */ "\x50" /* push eax */
/* 000A */ "\xad" /* lodsd */
/* 000B */ "\x93" /* xchg ebx, eax */
/* 000C */ "\xad" /* lodsd */
/* 000D */ "\x95" /* xchg ebp, eax */
/* 000E */ "\xad" /* lodsd */
/* 000F */ "\x97" /* xchg edi, eax */
/* 0010 */ "\x5e" /* pop esi */
/* 0011 */ "\x42" /* inc edx */
/* 0012 */ "\xb0\x60" /* mov al, 0x60 */
/* 0014 */ "\x57" /* push edi */
/* 0015 */ "\x29\xcc" /* sub esp, ecx */
/* 0017 */ "\x29\xcc" /* sub esp, ecx */
/* 0019 */ "\x89\xe7" /* mov edi, esp */
/* 001B */ "\x51" /* push ecx */
/* 001C */ "\xf3\xa4" /* rep movsb */
/* 001E */ "\x59" /* pop ecx */
/* 001F */ "\x89\xe6" /* mov esi, esp */
/* 0021 */ "\x60" /* pushal */
/* 0022 */ "\x49" /* dec ecx */
/* 0023 */ "\x92" /* xchg edx, eax */
/* 0024 */ "\xaa" /* stosb */
/* 0025 */ "\x30\xc0" /* xor al, al */
/* 0027 */ "\xf3\xaa" /* rep stosb */
/* 0029 */ "\x61" /* popal */
/* 002A */ "\xe8\x24\x00\x00\x00" /* call 0x53 */
/* 002F */ "\xc1\xe9\x02" /* shr ecx, 2 */
/* 0032 */ "\xf8" /* clc */
/* 0033 */ "\x60" /* pushal */
/* 0034 */ "\xad" /* lodsd */
/* 0035 */ "\x13\x07" /* adc eax, dword ptr [edi] */
/* 0037 */ "\xab" /* stosd */
/* 0038 */ "\xe2\xfa" /* loop 0x34 */
/* 003A */ "\x61" /* popal */
/* 003B */ "\x89\xee" /* mov esi, ebp */
/* 003D */ "\x51" /* push ecx */
/* 003E */ "\x49" /* dec ecx */
/* 003F */ "\x8b\x04\x8f" /* mov eax, dword ptr [edi + ecx*4] */
/* 0042 */ "\x3b\x04\x8e" /* cmp eax, dword ptr [esi + ecx*4] */
/* 0045 */ "\xe1\xf8" /* loope 0x3f */
/* 0047 */ "\x59" /* pop ecx */
/* 0048 */ "\x72\x08" /* jb 0x52 */
/* 004A */ "\x8b\x07" /* mov eax, dword ptr [edi] */
/* 004C */ "\x1b\x06" /* sbb eax, dword ptr [esi] */
/* 004E */ "\xab" /* stosd */
/* 004F */ "\xad" /* lodsd */
/* 0050 */ "\xe2\xf8" /* loop 0x4a */
/* 0052 */ "\xc3" /* ret */
/* 0053 */ "\x4a" /* dec edx */
/* 0054 */ "\x78\x04" /* js 0x5a */
/* 0056 */ "\x83\x2c\x24\x1c" /* sub dword ptr [esp], 0x1c */
/* 005A */ "\x99" /* cdq */
/* 005B */ "\x8d\x04\xca" /* lea eax, [edx + ecx*8] */
/* 005E */ "\x48" /* dec eax */
/* 005F */ "\x74\x05" /* je 0x66 */
/* 0061 */ "\x0f\xa3\x03" /* bt dword ptr [ebx], eax */
/* 0064 */ "\x73\xf8" /* jae 0x5e */
/* 0066 */ "\x0f\xa3\x13" /* bt dword ptr [ebx], edx */
/* 0069 */ "\x9c" /* pushfd */
/* 006A */ "\x60" /* pushal */
/* 006B */ "\x99" /* cdq */
/* 006C */ "\x0f\x43\xfe" /* cmovae edi, esi */
/* 006F */ "\x89\xfb" /* mov ebx, edi */
/* 0071 */ "\xff\x54\x24\x24" /* call dword ptr [esp + 0x24] */
/* 0075 */ "\x61" /* popal */
/* 0076 */ "\x9d" /* popfd */
/* 0077 */ "\xf5" /* cmc */
/* 0078 */ "\x73\xef" /* jae 0x69 */
/* 007A */ "\x42" /* inc edx */
/* 007B */ "\x48" /* dec eax */
/* 007C */ "\x79\xe8" /* jns 0x66 */
/* 007E */ "\x89\xfe" /* mov esi, edi */
/* 0080 */ "\x8d\x64\x4c\x04" /* lea esp, [esp + ecx*2 + 4] */
/* 0084 */ "\x5f" /* pop edi */
/* 0085 */ "\xf3\xa4" /* rep movsb */
/* 0087 */ "\x61" /* popal */
/* 0088 */ "\xc3" /* ret */
};
//
// This function tests the modexp function to ensure it's working correctly.
//
void
diffie_hellman_key_xchg_x86(BIGNUM *p, BIGNUM *g, BIGNUM *x, BIGNUM *y) {
DH_T dh={0};
modexp_t modexp = (modexp_t)mxp32;
int bits = BN_num_bits(p); // use prime p for maxbits
int bytes = BN_num_bytes(p);
if (BN_bn2bin_le(p, dh.p, BN_LEN) < 0) {printf("p error.\n"); exit(0);}
if (BN_bn2bin_le(g, dh.g, BN_LEN) < 0) {printf("g error.\n"); exit(0);}
if (BN_bn2bin_le(x, dh.x, BN_LEN) < 0) {printf("x error.\n"); exit(0);}
if (BN_bn2bin_le(y, dh.y, BN_LEN) < 0) {printf("y error.\n"); exit(0);}
// align up by 32-bits
dh.maxbits = (((bits + 1) + 31) & -32);
dh.maxbytes = dh.maxbits >> 3;
printf("\n\nPerforming %d-Bit DH\n", dh.maxbits);
// Alice obtains A = g ^ x mod p
modexp(dh.maxbytes, dh.g, dh.x, dh.p, dh.A);
// Bob obtains B = g ^ y mod p
modexp(dh.maxbytes, dh.g, dh.y, dh.p, dh.B);
// *************************************
// Bob and Alice exchange A and B values
// *************************************
// Alice computes s1 = B ^ x mod p
modexp(dh.maxbytes, dh.B, dh.x, dh.p, dh.s1);
// Bob computes s2 = A ^ y mod p
modexp(dh.maxbytes, dh.A, dh.y, dh.p, dh.s2);
// s1 + s2 should be equal
if (!memcmp(dh.s1, dh.s2, dh.maxbytes)) {
printf("\n\nx86 asm Key exchange succeeded");
dump_bn("\n\nx86 Session key = ", dh.s1, bytes);
} else {
printf("\nx86 Key exchange failed\n");
}
}
//
// Performs Diffie-Hellman key exchange using BN_mod_exp() from OpenSSL and modexp in x86 assembly.
//
// Note: This isn't the correct way to use OpenSSL for Diffie-Hellman key exchange.
// We're just using BN_mod_exp() directly to demonstrate how it works internally.
//
void
diffie_hellman_key_xchg(const char modp[]) {
BIGNUM *p, *g, *x, *y, *A, *B, *s1, *s2;
BN_CTX *ctx = BN_CTX_new ();
p = BN_new ();
g = BN_new ();
x = BN_new ();
y = BN_new ();
A = BN_new ();
B = BN_new ();
s1 = BN_new ();
s2 = BN_new ();
// initialise DH parameters
BN_hex2bn(&p, modp);
BN_hex2bn(&g, "2");
// Alice generates a private key x, then does g ^ x mod p
BN_rand_range(x, p);
BN_mod_exp(A, g, x, p, ctx);
printf("\n\n*** Private and public keys for Alice. ***\n");
printf("x = %s\n", BN_bn2hex(x));
printf("A = %s\n", BN_bn2hex(A));
// Bob generates a private key y, then does g ^ y mod p
BN_rand_range(y, p);
BN_mod_exp(B, g, y, p, ctx);
printf("\n\n*** Private and public keys for Bob. ***\n");
printf ("y = %s\n", BN_bn2hex(y));
printf ("B = %s\n", BN_bn2hex(B));
// *************************************
// Bob and Alice exchange A and B values
// *************************************
// Alice computes session key
BN_mod_exp (s1, B, x, p, ctx);
// Bob computes session key
BN_mod_exp (s2, A, y, p, ctx);
// check if both keys match
if (BN_cmp (s1, s2) == 0) {
printf ("\n\nKey exchange succeeded");
printf ("\n\nSession key = %s\n", BN_bn2hex (s1));
} else {
printf ("\n\nKey exchange failed\n");
}
// call the assembler function
diffie_hellman_key_xchg_x86(p, g, x, y);
BN_free (s2);
BN_free (s1);
BN_free (p);
BN_free (g);
BN_free (y);
BN_free (x);
BN_free (B);
BN_free (A);
// release context
BN_CTX_free (ctx);
}
int
main(void) {
diffie_hellman_key_xchg(OAKLEY_PRIME_MODP768);
diffie_hellman_key_xchg(OAKLEY_PRIME_MODP1024);
return 0;
}
9.3 Summary
If you’re a fan of codegolf and want to optimise the assembly further, here’s what i’d recommend.
- Optimal Method
- Redundant code
- Calling convention
There’s both right-to-left and left-to-right methods used when there only needs to be one. My own preference now would be right-to-left because it would be easier to debug.
If you’re not concerned about speed, counting the number of bits for the exponent in modexp and multiplier in mulmod isn’t required. Just fix the numbers to 1024-bits, 2048-bits..or whatever you intend to use.
Unless you intend to invoke the assembly function directly using a standard calling convention, it’s perfectly fine to use something else.
It’s currently 134 bytes. Remove the bitscan function. Use right-to-left method for both modexp and mulmod combined. Use a custom calling convention. You might shave off another 20 bytes or so.
Appendix
I wanted to avoid talking too much about the problems with Diffie-Hellman key exchange itself, but at the same time, it’s important to mention why modexp by itself is really not enough to perform secure key exchange. Mitigations are typically provided by Password Authenticated Key Exchange (PAKE) algorithms. You’ll find enough here to research the rest on your own.
1. Man In The Middle Attack
Some of you will have noticed the potential for a MITM in plain DH. Even if Alice and Bob are using a large prime number and make it computationally expensive or infeasible to discover the private keys of Alice and Bob, a much simpler attack exists that only requires control of the communication channel between Alice and Bob. A threat actor can perform a MITM attack by supplying Alice and Bob its own public keys and compromise the DH cryptosystem. The following steps outline how to do this.
There are of course other considerations such as a p number that is too weak to withstand a DLP attack. 512-bit keys for example would be too small and this is a known problem with old versions of TLS designed for the export market.
2. Password Authenticated Key Exchange (PAKE)
To mitigate against MITM attacks, several algorithms based on the use of a pre-shared secret were proposed, the first of which was by Steven M. Bellovin and Michael Merritt in their 1992 paper titled Encrypted Key Exchange: Password-Based Protocols Secure Against Dictionary Attacks. The ideas presented in this paper were the basis for many more to follow. There are four types of PAKE.
-
Balanced PAKE
- DH-EKE (Diffie-Hellman Encrypted Key Exchange) – 1992
- SPEKE (Simple Password Exponential Key Exchange) – 1996
- SRP (Secure Remote Password) – 1998
- Dragonfly/SAE (Simultaneous Authentication of Equals, used in Wi-Fi) – 2008
- J-PAKE (Password Authenticated Key Exchange by Juggling) – 2010
- SPAKE2 (Simple Password Authenticated Key Exchange) – 2015
- SRP6a (Secure Remote Password Protocol Version 6a) – 2015
- CPace (Composable Password Authenticated Connection Establishment) – 2020
-
Augmented PAKE
- Augmented EKE (Encrypted Key Exchange) – 1993
- BSPEKE (Balanced and Secure Password Exponential Key Exchange) – 2001
- B-SPEKE (Balanced Simple Password Exponential Key Exchange) – 2008
- OPAQUE (Asymmetric PAKE with Stronger Security Properties) – 2018
- SPAKE2+ (Simple Password Authenticated Key Exchange Plus) – 2018
- AMP (Augmented Multi-party Password-protected key exchange) – 2019
- AuCPace (Authenticated Key Exchange with Optimal Security against Undetectable Online Dictionary Attacks) – 2020
-
Doubly Augmented PAKE
- Double BS-SPEKE (Double Balanced and Secure Simple Password Exponential Key Exchange) – 2001
- OPAQUE-3DH (Three-Message OPAQUE with Strong Security Properties) – 2018
-
Identity-Based PAKE
- IB-SPEKE (Identity-Based Simple Password Exponential Key Exchange) – 2002
- IBPAKE (Identity-Based Password Authenticated Key Exchange) – 2003
- IBE-DHKE (Identity-Based Diffie-Hellman Key Exchange) – 2004
2.1 EKE – Encrypted Key Exchange
Bellovin and Merrit suggest some algorithms to mitigate MITM attacks, one of which includes EKE. Essentially it suggests using a pre-shared secret (PSK) to encrypt the public keys exchanged between Alice and Bob.
Here’s the revised Python code to perform DH key exchange using a PSK.
import secrets
from Crypto.Cipher import AES
import hashlib
import struct
# Oakley Group 1 parameters (768-bit MODP Group)
p = int(
"FFFFFFFFFFFFFFFFC90FDAA22168C234C4C6628B80DC1CD1"
"29024E088A67CC74020BBEA63B139B22514A08798E3404DD"
"EF9519B3CD3A431B302B0A6DF25F14374FE1356D6D51C245"
"E485B576625E7EC6F44C42E9A63A3620FFFFFFFFFFFFFFFF", 16)
g = 2
password = "password"
# Hash the password to get a fixed-length key
def derive_key(password):
return hashlib.sha256(password.encode()).digest()
# Encrypt a message using AES in CTR mode
def encrypt_message(message, key):
nonce = secrets.token_bytes(8) # 64-bit nonce for CTR mode
cipher = AES.new(key, AES.MODE_CTR, nonce=nonce)
encrypted_message = nonce + cipher.encrypt(message)
return encrypted_message
# Decrypt a message using AES in CTR mode
def decrypt_message(encrypted_message, key):
nonce = encrypted_message[:8]
cipher = AES.new(key, AES.MODE_CTR, nonce=nonce)
decrypted_message = cipher.decrypt(encrypted_message[8:])
return decrypted_message
# Generate private key
def generate_private_key():
return secrets.randbelow(p)
# Generate public key
def generate_public_key(private_key):
return pow(g, private_key, p)
# Compute shared secret
def compute_shared_secret(received_public_key, private_key):
return pow(received_public_key, private_key, p)
# Simulate EKE with Diffie-Hellman Key Exchange
def eke_diffie_hellman():
# Derive the encryption key from the password
key = derive_key(password)
# Alice's keys
alice_private_key = generate_private_key()
alice_public_key = generate_public_key(alice_private_key)
alice_encrypted_public_key = encrypt_message(alice_public_key.to_bytes((alice_public_key.bit_length() + 7) // 8, byteorder='big'), key)
# Bob's keys
bob_private_key = generate_private_key()
bob_public_key = generate_public_key(bob_private_key)
bob_encrypted_public_key = encrypt_message(bob_public_key.to_bytes((bob_public_key.bit_length() + 7) // 8, byteorder='big'), key)
# Exchange encrypted public keys and decrypt them
alice_decrypted_public_key = int.from_bytes(decrypt_message(bob_encrypted_public_key, key), byteorder='big')
bob_decrypted_public_key = int.from_bytes(decrypt_message(alice_encrypted_public_key, key), byteorder='big')
# Compute shared secrets
alice_shared_secret = compute_shared_secret(alice_decrypted_public_key, alice_private_key)
bob_shared_secret = compute_shared_secret(bob_decrypted_public_key, bob_private_key)
# Both shared secrets should be the same
assert alice_shared_secret == bob_shared_secret
return alice_shared_secret
Although this is better than the original DH, an attacker can perform an offline dictionary attack on the pre-shared key and that’s where augmented EKE comes in.
2.2 SPEKE – Simple Password Exponential Key Exchange
This paper by David Jablon in 1996 proposes a slight modification to the original DH protocol.
import secrets
import hashlib
# Oakley Group 1 parameters (768-bit MODP Group)
p = int(
"FFFFFFFFFFFFFFFFC90FDAA22168C234C4C6628B80DC1CD1"
"29024E088A67CC74020BBEA63B139B22514A08798E3404DD"
"EF9519B3CD3A431B302B0A6DF25F14374FE1356D6D51C245"
"E485B576625E7EC6F44C42E9A63A3620FFFFFFFFFFFFFFFF", 16)
password = "password"
# Derive the generator g from the password using a hash function
def derive_generator(password, p):
hash_value = hashlib.sha256(password.encode()).digest()
g = int.from_bytes(hash_value, byteorder='big') % p
return g
# Generate private key
def generate_private_key(p):
return secrets.randbelow(p - 1) + 1 # Ensure the private key is in the range [1, p-1]
# Generate public key
def generate_public_key(g, private_key, p):
return pow(g, private_key, p)
# Compute shared secret
def compute_shared_secret(received_public_key, private_key, p):
return pow(received_public_key, private_key, p)
# SPEKE Diffie-Hellman Key Exchange
def speke_diffie_hellman():
# Derive generator g from the password
g = derive_generator(password, p)
# Alice's keys
alice_private_key = generate_private_key(p)
alice_public_key = generate_public_key(g, alice_private_key, p)
# Bob's keys
bob_private_key = generate_private_key(p)
bob_public_key = generate_public_key(g, bob_private_key, p)
# Exchange public keys and compute shared secrets
alice_shared_secret = compute_shared_secret(bob_public_key, alice_private_key, p)
bob_shared_secret = compute_shared_secret(alice_public_key, bob_private_key, p)
# Both shared secrets should be the same
assert alice_shared_secret == bob_shared_secret
return alice_shared_secret
3. Acknowledgements
Individuals that helped directly or indirectly: Qkumba, Z0MBiE, WiteG, Drizz
如有侵权请联系:admin#unsafe.sh