
Table of contentsIntroductionContextExpectationsImplementationScrapingGrammarParsingStoring and usin 2024-7-9 00:0:0 Author: blog.lexfo.fr(查看原文) 阅读量:64 收藏
Table of contents
Introduction
This blog post introduces a tool that extracts stolen credentials from text files coming in varying formats in order to address CTI and Red Teaming needs.
Context
Information stealers (or more commonly “infostealers” or “stealers”) are malwares designed to collect sensitive data from infected systems such as:
- Web browsers data (email addresses, usernames, passwords, cookies, search history, and so forth);
- Credit cards information;
- Cryptocurrency wallets;
- Desktop files;
- Installed software and machine data;
- And much more.
In most cases, infostealers are sold as Malware-as-a-Service (MaaS). This is then no surprise they are simple to use. The most famous ones include RedLine, its successor META, Raccoon, or Stealc.
Infostealer attacks are motivated by financial gain. Stolen data, also called “logs” in this context, is put up for sale on the dark web or messaging platforms such as Telegram. Some threat actors build communities (“logs cloud” or “cloud of logs”) to share archived logs as ZIP or RAR files. Because there are as many paid-access channels as there are free ones, logs quality and recentness can vary a lot.
Expectations
Automating infostealer logs processing could prove useful for two of our teams. It is easy to find scripts for that online, like on GitHub, but they do not handle enough file formats. Thus, developing our own tool seemed a reasonable choice.
First, LEXFO has expertise in data breach detection. Our specialized team searches for client information exposed on the different layers of the web and notices them if a leakage is confirmed. This task, when done manually, is very time-consuming as it involves many steps, such as browsing hundreds of channels, downloading tons of zipped archives, searching them for specific domain names and keywords, and so on. Therefore, automation would be a huge help.
Next, this kind of tool could provide valuable assets to Red Teamers. Since logs contain credentials, it would be interesting to build a search engine similar to Intelligence X or DeHashed.
To meet these requirements, we have to:
- Identify and extract interesting information;
- Represent it with generic models (use the same structure for all credentials regardless of their source so that adding new types of leaks remains seamless);
- Store it in database;
- Send analysts a daily summary of leaked client data;
- Provide a way to search data and filter results by date, domain name, URL, and so on.
This blog post focuses only on the extraction part. It will detail how to create a stealer logs parser.
Implementation
1. Scraping
The first step is to create a Telegram account that will join logs clouds. The scraper will use it to connect and download every logs archive received thanks to an event listener.
Note that sometimes the archives are password-protected. The password can be found in the corresponding Telegram message's text content.

2. Grammar
One archive can contain thousands of directories and subdirectories. Each stands for a compromised system and often looks like this:
├── Autofills
│ ├── Google_[Chrome]_Default.txt
│ └── Microsoft_[Edge]_Default.txt
├── Cookies
│ ├── Firefox_123456.default-release.txt
│ ├── Google_[Chrome]_Default Network.txt
│ └── Microsoft_[Edge]_Default Network.txt
├── DomainDetects.txt
├── FileGrabber # Desktop files
│ └── Users
│ └── ...
│ └── Desktop
│ └── ...
├── ImportantAutofills.txt
├── InstalledBrowsers.txt
├── InstalledSoftware.txt
├── Passwords.txt # Stolen credentials
├── ProcessList.txt
├── Screenshot.jpg
└── UserInformation.txt # Information about the compromised system
Every stealer has its own directory structure and text files formatting. Although close, they are different enough to require more than a ten-line script.
Credentials
In every system directory, there is usually a text file that groups stolen credentials. Most of the times, it is named as follows:
password.txt;Password.txt;All passwords.txt;AllPasswords_list.txt;_AllPasswords_list.txt.
The document layout depends on the stealer that harvested the data. Here are five examples from five different sources:
Soft: Google Chrome [Default]
Host: https://example.com
Login: ••••••
Password: ••••••
["Chrome" = "Default"]
Hostname: https://example.com
Username: ••••••
Password: ••••••
browser: Google Chrome
profile: Default
url: https://example.com
login: ••••••
password: ••••••
SOFT: Chrome (foo.default)
URL: https://example.com
USER: ••••••
PASS: ••••••
URL: https://example.com
Username: ••••••
Password: ••••••
Application: Google_[Chrome]_Profile 1
It shows that the stolen information is mainly the same. Only the field names that prefix them change.
| Information | Prefixes |
|---|---|
| URL or hostname | Host, URL, url |
| application (web browser, email client) | Soft, browser, SOFT, Application |
| username | Login, login, username |
| password | Password, password, PASS |
It is important to note that the prefix list above is only part of a larger one. Moreover, there is little doubt new ones will be discovered in the future.
In order to avoid struggling with a forest of if statements and write maintainable and extensible code, creating a grammar is the first thing to do, beginning with the tokens. They will be used to split the file's text content before parsing it.
%token WORD
%token NEWLINE
%token SPACE
%token SOFT_PREFIX
/* 'Soft:' | 'SOFT:' | 'Browser:' | 'Application:' | 'Storage:' */
%token SOFT_NO_PREFIX
/* '["Browser" = "Profile"]' */
%token HOST_PREFIX
/* 'Host:' | 'Hostname:' | 'URL:' | 'UR1:' */
%token USER_PREFIX
/* 'USER LOGIN:' | 'Login:' | 'Username:' | 'USER:' | 'U53RN4M3:' */
%token PASSWORD_PREFIX
/* 'USER PASSWORD:' | 'Password:' | 'PASS:' | 'P455W0RD:' */
%token SELLER_PREFIX
/* 'Seller:' | 'Log Tools:' | 'Free Logs:' */
Grammar rules come next. They are defined from the various log formats encountered.
After many iterations, these are the rules obtained:
%start passwords
%%
passwords : NEWLINE
| user_block
| seller_block
| header_line
;
header_line : WORD NEWLINE
| SPACE NEWLINE
| WORD header_line
;
seller_block : SELLER_PREFIX SPACE entry
| host_line
| seller_block NEWLINE
;
user_block : soft_line host_line user_line password_line
| host_line user_line password_line
| soft_line user_line password_line
;
soft_line : SOFT_PREFIX NEWLINE
| SOFT_PREFIX SPACE NEWLINE
| SOFT_PREFIX SPACE entry NEWLINE
| soft_line profile_line NEWLINE
| SOFT_NO_PREFIX NEWLINE
;
profile_line : 'profile:' SPACE WORD
;
host_line : HOST_PREFIX NEWLINE
| HOST_PREFIX SPACE NEWLINE
| HOST_PREFIX SPACE entry NEWLINE
;
user_line : USER_PREFIX NEWLINE
| USER_PREFIX SPACE NEWLINE
| USER_PREFIX SPACE entry NEWLINE
;
password_line : PASSWORD_PREFIX NEWLINE
| PASSWORD_PREFIX SPACE NEWLINE
| PASSWORD_PREFIX SPACE entry NEWLINE
| multiline_entry NEWLINE
;
multiline_entry : WORD
| multiline_entry NEWLINE WORD
;
entry : WORD
| entry SPACE WORD
;
However, keep in mind that new unseen or wrong formats could still be found and that this grammar is basically never finished. As they say, there is always room for improvement.
The grammar is available in our GitHub repository.
About the host
In addition to the credentials, the system directory contains a text file describing the infected machine (country, IP address, user, and so forth). Most common names include:
system_info.txt;System Info.txt;information.txt;Information.txt;UserInformation.txt.
Here is an example:
Network Info:
- IP: ••••••••••••
- Country: FR
System Summary:
- UID: ••••••••••••
- HWID: ••••••••••••
- OS: Windows 10 Pro
- Architecture: x64
- User Name: ••••••
- Computer Name: ••••••••••••
- Local Time: 2023/6/21 20:58:2
- UTC: 0
- Language: fr-FR
- Keyboards: French (France)
- Laptop: FALSE
- Running Path: ••••••••••••
- CPU: Intel(R) Core(TM) i7-3770 CPU @ 3.40GHz
- Cores: 4
- Threads: 8
- RAM: 16348 MB
- Display Resolution: 1920x1080
- GPU:
-NVIDIA GeForce GTX 1650
-NVIDIA GeForce GTX 1650
-NVIDIA GeForce GTX 1650
-NVIDIA GeForce GTX 1650
Good to Know: The IP address may sometimes be found in a separate file named
ip.txt.
Below is the token list produced:
%token WORD
%token NEWLINE
%token SPACE
%token DASH
%token UID_PREFIX
/* 'UID:' | 'MachineID:' */
%token COMPUTER_NAME_PREFIX
/* 'Computer:' | 'ComputerName:' | 'Computer Name:' | 'PC Name:' | 'Hostname:' | 'MachineName:' */
%token HWID_PREFIX
/* 'HWID:' */
%token USERNAME_PREFIX
/* 'User Name:' | 'UserName:' | 'User:' */
%token IP_PREFIX
/* 'IP:' | 'Ip:' | 'IPAddress:' | 'IP Address:' | 'LANIP:' */
%token COUNTRY_PREFIX
/* 'Country:' | 'Country Code:' */
%token LOG_DATE_PREFIX
/* 'Log date:' | 'Last seen:' | 'Install Date:' */
%token OTHER_PREFIX
/* 'User Agents:' | Installed Apps:' | 'Current User:' | 'Process List:' */
The grammar rules are constructed in the same manner as for credentials.
Find the full grammar in our GitHub repository.
3. Parsing
In order to implement all of this, two more things are required:
- A lexer (or tokenizer) that will segment the input text into tokens;
- And a parser that will compare the tokens against the grammars and returns structured data (commonly an AST but there is no use for it in this case). To do so, every rule will be implemented in Python.
If we take a quick look at the grammar, a line containing hostname or URL information is parsed thanks to the host_line rule:
host_line : HOST_PREFIX NEWLINE
| HOST_PREFIX SPACE NEWLINE
| HOST_PREFIX SPACE entry NEWLINE
;
# Just adding the entry rule to bring better understanding of host_line
entry : WORD
| entry SPACE WORD
;
Which translated to Python becomes:
def parse_host_line(parser: LogsParser, credential: Credential) -> bool:
"""Parse host data (website visited when user's data was stolen).
host_line : HOST_PREFIX NEWLINE
| HOST_PREFIX SPACE NEWLINE
| HOST_PREFIX SPACE entry NEWLINE
"""
if parser.eat("HOST_PREFIX"):
if parser.eat("SPACE"):
credential.host = parse_entry(parser)
extract_credential_domain_name(credential)
parser.eat("NEWLINE")
return True
return False
The result is stored in a Credential object.
Every other rule follows this logic.
4. Storing and using collected data
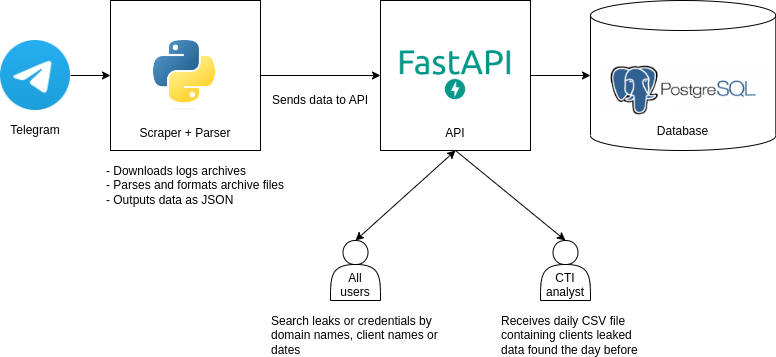
Since the data is structured, the chosen solution was PostgreSQL. A Python API (FastAPI) performs data validation and enables users to search leaks, exposing conveniently documented routes.
A CSV file is sent daily to analysts so they get an overview of the client sensitive data that leaked in the last 24 hours.
Conclusion
Looking more closely at the log files shows that they do not differ significantly. Writing a grammar seemed then the most clean and extensible choice. Whenever a new prefix is encountered, all we have to do is add it to the token list.
If you want to test the tool, a part of its code is available here.
如有侵权请联系:admin#unsafe.sh