By Justin Jacob
Cryptography is a fundamental part of electronics and the internet that helps secure credit cards, cell phones, web browsing (fingers crossed you’re using TLS!), and even top-secret military data. Cryptography is just as essential in the blockchain space, with blockchains like Ethereum depending on hashes, Merkle trees, and ECDSA signatures, among other primitives, to function. Innovative techniques like pairings, fully homomorphic encryption, and zero-knowledge proofs have also made their way into the blockchain realm.
Cryptography seems like a complex and perplexing “mathemagical” puzzle for many. As a blockchain security engineer, I’ve always been fascinated by cryptography but never dived deeply into the topic. Luckily, my colleagues at Trail of Bits are world-class cryptography experts! I asked them ten questions to help you unravel some of cryptography’s mysteries. Keep in mind that some questions are reasonably advanced and may require extra background knowledge. But if you’re an aspiring crypto enthusiast, don’t be discouraged—keep reading!
1. Can you outline the most common commitment schemes employed for SNARKS?
A polynomial commitment scheme is a protocol where a prover commits to a certain polynomial and produces a proof that the commitment is valid. The protocol consists of three main algorithms:
- Commit
- Open
- Verify
In the commit phase, the prover sends their commitment—i.e., their claimed value of an evaluation of a polynomial f at a given point (so a value a such that f(x) = a). The commitment should be binding, meaning that once a prover commits to a polynomial they cannot “change their mind,” so to speak, and produce a valid proof for a different polynomial. It could also be hiding, in the sense that it is cryptographically infeasible to extract the value x such that f(x) = a. In the opening phase, the prover sends a proof that the commitment is valid. In the verification phase, the verifier checks that proof for validity. If the proof is valid, we know that the prover knows x such that f(x) = a, with high probability.
We are already familiar with one type of vector commitment, a Merkle tree. The properties of polynomial commitment schemes are similar, but they apply to polynomials instead. The most common commitment schemes being used in production are:
- KZG (Kate-Zaverucha-Goldberg), used, for example, for danksharding in EIP 4844
- FRI (Fast Reed-Solomon Interactive Oracle Proofs of Proximity) used in STARKs
- Commitments like Pedersen commitments are used in proof systems like Bulletproofs (used by Monero and Zcash)
KZG commitments leverage the fact that if a polynomial f(x0) = u at some point x0, then f(x) - u must have a factor of (x - x0). By the Schwartz-Zippel lemma, if we choose a large enough domain, it is very unlikely for a different polynomial g(x) - u to be divisible by (x - x0). At a high level, we can leverage this to commit to the coefficients of f(x) and generate a proof, which the verifier can check extremely fast without revealing the polynomial itself through an elliptic curve pairing.
FRI uses error correcting codes to “boost” the probability that a verifier will discover an invalid commitment. We can then commit to the evaluations of the error corrected polynomial using a Merkle tree. Opening involves providing a Merkle authentication path to the verifier.
Pedersen commitments use the discrete logarithm problem. Precisely, we can commit to coefficients a0, … an given a basis of group elements (g0, g1, … gn) as C = g0 * a0 + g1 * a1 + … + g1 * an. We can combine this with the Inner Product Argument (which is out of this post’s scope) to generate a polynomial commitment scheme with open and verification algorithms based on the inner product argument.
KZG has very small proof sizes consisting of one group element. However, this involves a trusted setup, and one must delete the trusted setup parameter, or else anyone can forge proofs. FRI requires no trusted setup and is plausibly post-quantum secure yet has very large proof sizes. Lastly, Pedersen commitments and IPA do not require a trusted setup but require linear verification time.
Other commitment schemes exist, such as Dory, Hyrax, and Dark, but they are much less used in practice.
To learn more about these commitments, check out our ZKDocs page.
2. Hashing is ubiquitous, yet few people grasp its inner workings. Can you clarify popular constructions (e.g., MD, Sponge) and highlight their differences?
Most hash functions people are familiar with, like MD5 and SHA1, are Merkle-Damgard constructions. The keccak256 function that we all know and love is a sponge construction.
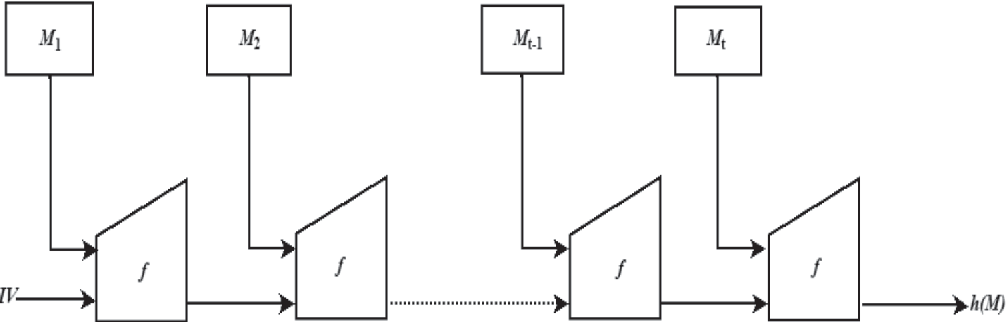
In the Merkle-Damgard construction, an arbitrary-length message gets parsed into blocks with a certain size.The key part is that a compression function gets applied to each block, using the previous block as the next compression function’s key (for the first block, we use an IV, or initialization vector, instead). The Merkle-Damgard construction shows that if the compression function is collision resistant, the whole hash function will be as well.

Figure 1: Merkle-Damgard construction
In contrast, sponge constructions don’t use compression functions. The core of the sponge construction consists of two stages: an “absorb” phase, where parts of the message get XOR’d with an initial state while a permutation function is applied to it, and then a “squeeze” phase where parts of the output are extracted and outputted as a hash.

Figure 2: Sponge construction
Notably, compared to Merkle-Damgard constructions, sponge constructions are not vulnerable to length extension attacks, since not all of the end result is used as an output to the hash function.
3. Elliptic curve cryptography (ECC) is even more enigmatic and considered a major “black box” in cryptography. Numerous pitfalls and technical attacks exist. Can you shed light on some theoretical assaults on elliptic curves, like Weil descent and the MOV attack?
ECC is often seen as a complex and somewhat mysterious part of cryptography, with potential vulnerabilities to various technical attacks. Two notable theoretical attacks are Weil descent and the MOV attack. Let’s demystify these a bit.
In essence, the security of ECC relies on the difficulty of solving a certain mathematical problem, known as the discrete logarithm problem, on elliptic curves. Standard elliptic curves are chosen specifically because they make this problem hard to crack. This is why, in practice, both Weil descent and the MOV attack are generally not feasible against standard curves.
- Weil descent attack: This method involves using concepts from algebraic geometry, particularly a technique called Weil descent. The idea is to transform the discrete logarithm problem from its original form on an elliptic curve (a complex algebraic structure) to a similar problem on a simpler algebraic structure, like a hyperelliptic curve. This transformation can make the problem easier to solve using known algorithms like index calculus, but only if the original elliptic curve is simple enough. Standardized curves are usually complex enough to resist this attack.
- MOV attack: This attack uses a mathematical function known as the Weil pairing to transform the elliptic curve discrete logarithm problem (ECDLP) into a discrete logarithm problem in a finite field, a different mathematical setting. The feasibility of this attack depends on a property called the embedding degree, which essentially measures how ‘transformable’ the ECDLP is to the finite field setting. If the embedding degree is low, the MOV attack can significantly weaken the security by moving the problem to a domain where more effective attack methods exist. However, commonly used elliptic curves are chosen to have a high embedding degree, making the MOV attack impractical.
In summary, while these theoretical attacks on elliptic curves sound daunting, the careful choice of elliptic curves in standard cryptographic applications usually renders the attacks ineffective.
4. As technology ramps up and the threat of quantum computers looms over us, efforts have been made to create post-quantum cryptosystems, like lattice-based cryptography and isogeny-based cryptography. Could you provide an overview of these systems?
Lattice-based cryptography uses lattices (obviously), which are integer linear combinations of a collection of basis vectors. There are many hard problems concerning lattices, such as the shortest vector problem (given a basis, find the shortest vector in the lattice) and the closest vector problem (given a lattice and a point p outside the lattice, find the closest point to p in the lattice). The following diagram, taken from this presentation at EuroCrypt 2013, illustrates this:

Figure 3: The shortest vector problem
Interestingly, it can be shown that most hard problems regarding lattices are actually as difficult as the shortest vector problem.The known algorithms for these problems, even quantum ones, take exponential time. We can leverage these hard problems to build cryptosystems.
Isogeny-based cryptography, on the other hand, involves using isogenies (obviously), which are homomorphisms between elliptic curves. We can essentially use these isogenies to create a post-quantum version of the standard elliptic curve Diffie-Hellman key exchange. At a 5,000-foot level, instead of sending a group element as a public key with a random integer as the private key, we can instead use the underlying isogeny as a private key and the image of the public elliptic curve as the public key. If Alice and Bob compose each other’s isogenies and compute the curve’s j invariant, they can each get a shared secret, as the j invariant is a mathematical function that is the same for isomorphic elliptic curves.
However, supersingular isogeny-based Diffie-Helman key exchange is subject to a key recovery attack that does not require a quantum computer and is therefore insecure. More research is currently being done on isogeny-based key exchange algorithms that are in fact secure against quantum computers.
5. The Fiat-Shamir heuristic is widely used throughout the field of interactive oracle proofs. What are some interesting things to note about this heuristic and its theoretical security?
Fiat-Shamir is used to turn interactive oracle proof systems into non-interactive proof systems.
As the name suggests, this allows a prover to prove a result of a computation without requiring the verifier to be online. This is done by taking a hash of the public inputs and interpreting that hash as a random input. If a hash function is truly a random oracle—that is, if the hash functions can approximate randomness—then we can emulate the verifier’s random coins in this way.
There are a couple of security-related concerns to note:
- The hash must consist of all public inputs; this concept is commonly called the strong Fiat-Shamir transform. The weak Fiat-Shamir transform consists only of the hash of one or a limited number of inputs, while the strong Fiat-Shamir transform involves the hash of all public inputs. As you can imagine, the weak Fiat-Shamir transform is insecure because it allows the prover to forge malicious proofs.
- More subtle, theoretical issues can arise even when using the strong Fiat-Shamir transform. Protocols must have a notion of “round-by-round” security, which roughly means that a cheating prover has to get lucky “all at once,” and as a result cannot grind out hashes until they receive a “lucky” input. This typically means that round-by-round protocols that use Fiat-Shamir will need to have a higher security parameter, like 128 bits for security. Luckily, systems like SumCheck and Bulletproofs are provably round-by-round secure, so the strong Fiat-Shamir heuristic can be safely used to create a non-interactive public coin protocol.
The Fiat-Shamir transform is widely used and extreme caution must be exercised when implementing it, since even minor misconfigurations can allow a malicious prover to forge proofs, which can have disastrous consequences. To learn more about Fiat-Shamir as well as potential pitfalls, see this overview blog post as well as another blog post about the Frozen Heart vulnerability.
6. There have recently been notable advancements in the PLONK Interactive Oracle Proof system. Could you elaborate on what’s being improved and how?
Interactive oracle proofs are the main information theoretic component in SNARKs that allow a prover to generate a proof that convinces a verifier of “knowledge” in such a way that fake proofs can be discovered with high probability.
A key factor between the different protocols is their improvements to both prover efficiency as well as increased flexibility. For example, the PLONK proof system typically requires a large amount of circuit gates, and many traditional computations are inefficient to encode as computations inside a circuit. In addition, the prover must then encode these gates into polynomials, which takes lots of compute time. Variants of PLONK help aim to solve these issues; these include:
- Turboplonk, which enables custom gates with more than two inputs, compared to normal PLONK, which allows for only two inputs per gate. Using Turboplonk enables more flexibility for complex arithmetic operations, such as bit shifts and XORs.
- UltraPLONK, which enables lookup tables, where the prover can just prove the “circuit hard” computations (e.g., SHA-256) and that their input/output pairs exist as part of the witness. More specifically, the additional constraints enabled on specific cells that contain these values can easily verify their validity.
- Hyperplonk, which eliminates the need for Number Theoretic Transform (NTT). The PLONK proving system typically requires a large multiplicative subgroup in order to compute a NTT, which you can think of as a cryptography-friendly version of a Discrete Fourier Transform. Hyperplonk instead uses the sumcheck protocol and multilinear commitments, which removes a large portion of prover overhead.
Currently, most of the APIs support the UltraPLONK extension (e.g., for Halo2 and Plonky2), as this supports both custom gates and lookups. Hyperplonk is promising, but it is still being fine-tuned and not used as much in common libraries. The PLONK IOP is continually being improved upon to be faster and better support recursive computation, with even more variants being developed.
7. We often hear about zkEVMs and projects building them, like Scroll, Polygon, and zkSync. Can you explain the various design decisions involved in building one? (Type 1/2/3, etc.)
You can think of the different types of zkEVMs based on how “exactly compatible” they are with Ethereum, with type 1 being the most equivalent and type 4 being the least equivalent.
Type 1 zkEVMs are equivalent to the execution and consensus layer of Ethereum in every way, which keeps compatibility with downstream tooling and allows for easy verification of L1 blocks. However, they come with the most prover overhead, since the EVM itself contains a lot of ZK-unfriendly technology (keccak, Merkle trees, stack). Currently, the PSE team and Taiko are working on building a type-1 zkEVM.
Type 2 zkEVMs aim to be EVM equivalent. The difference between Type 2 and Type 1 is that objects outside of the EVM, like the state trie and block verification, will behave differently, so most Ethereum clients themselves will not be compatible with this zkEVM. The advantage is faster proving time, while the primary disadvantage is less equivalence. For example, a Type 2 zkEVM may use a modified state trie instead of the Merkle tries used by Ethereum. Both the Scroll team and Polygon are aiming to be a Type 2 zkEVM, however in their current state it’s more appropriate to designate them as Type 3.
Type 3 zkEVMs also have faster proving time but achieve this by using even less equivalence. These VMs remove parts of the EVM that are difficult to natively perform in a circuit, like keccak256, and replace them with ZK-friendly hash functions (like Poseidon). Furthermore, they may use a different memory model instead of simply being stack-based like the EVM; for example, they may use registers instead. Linea is an example of a Type 3 zkEVM; however, like Scroll and Polygon, they are working on improvements to make it Type 2.
The last type of zkEVM is Type 4, which just aims to take a language like Solidity and Vyper and compile it to a ZK-friendly format for generating proofs. Obviously, this is the least equivalent (to the point where it may not even have EVM-compatible bytecode), but the tradeoff is that proof generation is the fastest. zkSync’s zkEVM is one example of a Type 4 zkEVM.
8. We currently have zkEVMs in production, with Scroll, zkSync, and Polygon having mainnet deployments. How many more improvements can we make to these zkEVMs to unlock consumer grade proving/verification?
Although theoretically the main challenges of building a zkEVM and creating efficient proofs can be addressed via a combination of plonkish arithmetization, lookups, and incrementally verifiable combination (IVC), a number of engineering challenges remain before we can truly create the massive scalability promised by ZK proofs. Current benchmarks for generating UltraPLONK proofs of 128K Pedersen hashes on a 32 core Intel Xeon Platinum CPU show that proving time is rather fast, taking only around three seconds; however, the memory requirement is still very high at around 130 GB. Many possible further optimizations can be done:
- Using smaller fields: Modern CPUs operate on 64 bit words, while computations inside SNARKs usually operate in elliptic curve groups, which are around 256 bits. This means that field elements inside a circuit have to be split into multiple limbs, which incurs a large computation cost. By using smaller fields like Goldilocks and performing FRI based verification (see Can you outline the most common commitment schemes employed for SNARKS?), prover computation can be sped up at the cost of larger proof sizes and slower verification.
- Hardware improvements and parallelization: Many FPGAs and ASICS can be used to optimize SNARK generation as well. SNARK proving usually involves lots of hashing and elliptic curve operations. In fact, around 60% of the proof generation comprises of Multi-Scalar- Multiplications, or MSMs. Thus, using specialized hardware designed for these operations can dramatically improve performance. In addition, specialized computing hardware can also perform NTTs more efficiently. Many teams in the ZK Space, like Ingonyama, are attempting to use FPGA/GPU hardware acceleration to speed up these operations. Furthermore, while parts of circuit synthesis cannot be parallelized, things like witness generation can be done in parallel, which further speeds up proof generation. Matter Labs’ Boojum is one such SNARK proving system that does this.
- Lastly, there are still many theoretical improvements that can further speed up both proof generation and verification. In addition to further work speeding up recursive SNARK proving such as Goblin Plonk, faster lookup arguments like Lasso will also lead to improved performance. Algorithms for elliptic curve operations themselves can be optimized. For example, scalar multiplication can be performed much faster than the standard “double-and add” algorithm through curve endomorphisms and Barrett reduction. Representing points using twisted edwards curves instead of Weierstrass form also can speed up point addition. Lastly, SNARKs like Binius use binary field towers to become more hardware-friendly.
As SNARK improvements are getting more and more advanced, it’s realistic that SNARKs will soon run on consumer-grade hardware. In the future, it may be possible to generate a zkSNARK on a smartphone.
9. Can you discuss secret sharing schemes like Shamir’s secret sharing, their potential use cases, and common mistakes you’ve observed?
Shamir’s secret sharing (SSS) is a way to split a group of secrets among various parties such that a group of them can work together to recover the secret, but any number of participants fewer than the threshold cannot learn any information.
The main idea of Shamir’s secret sharing uses the fact that any set of p + 1 points uniquely determines a p degree polynomial. By using lagrange interpolation, a threshold of participants can work together to recover the shared secret (in this case, the constant term of the polynomial). Verifiable secret sharing extends SSS, and involves publishing a discrete log based commitment to the set of shares. Secret sharing is widely used in threshold signatures like tECDSA and various multi-party computation protocols.
As with all cryptographic schemes, there are a couple footguns to be aware of that could make SSS or Feldman’s Verifiable Secret Sharing completely insecure:
- Sharing the 0 point to a participant inadvertently leaks the secret. This is by definition, since the 0 point is the secret that the participants must work together to recover. However, because the polynomial is defined over a finite field, care must be taken to not generate any shares that are modularly equivalent to 0.
- Making sure the difference between shares is not 0 or modularly equivalent. To recompute the shared secret, Lagrange interpolation is used, which involves computer modular inverses of the difference between shares. If the difference between shares is 0, then the protocol fails, since 0 does not have a modular inverse.
- When creating a commitment for verifiable secret sharing, make sure to verify the degree of the committed polynomial (i.e., the number of coefficients sent by the generating party). A malicious party could send more coefficients than necessary, increasing the threshold for everyone.
10. Folding schemes for recursive proofs have become really popular lately. Could you give a rough summary on how they work?
Gladly! Folding schemes are one solution to a problem known as incrementally verifiable computation. The question behind incrementally verifiable computation (IVC) asks: given a function F and an initial input v0, where v_i = F^i(v0), can you verify the computation of F at each index i? A concrete example would be having the EVM state transition function F and a world state w0. IVC asks if it’s possible to verify the execution of the previous state transition function, up until the final state:
Previous approaches to IVC involved having the prover generate a SNARK whose verification circuit gets embedded in the function F. This approach works,but is rather inefficient, as a prover needs to generate a SNARK and the verifier needs to verify it on every iteration of F, which would require lots of circuit-expensive, non-native field arithmetic. Furthermore, folding schemes offer a ton of advantages compared to embedding a large SNARK circuit in the verifier. Batch sizes can now be dynamic, instead of having to specify a batch size during SNARK verification. In addition, proving can be done in parallel for every state transition, and the prover can start generating a proof as soon as the first transaction is observed instead of having to wait for the entire batch.
Folding schemes originated with Nova and introduced a new idea: instead of verifying a SNARK at every invocation of F, the verifier will “fold” the current instance into an accumulator. At the end of execution, the verification circuit will simply check the consistency of the accumulator. More technically, given two witnesses to a constraint system, the verifier can combine their commitments into a witness commitment for something called a relaxed R1CS, which is an R1CS instance along with a scalar u and an error vector e. The error vector is used to “absorb” the cross terms generated by combining the two commitments, and the scalar is used to “absorb” multiplicative factors. This allows us to preserve the structure of the R1CS for the next round. By repeatedly doing this, the verifier can fold every new witness instance into the accumulator, which will get checked at the end of the computation. To turn this accumulation scheme into an IVC, all the verifier has to do is verify that the folding was done correctly. Doing so verifies every invocation of F with a single check independent of the number of folded instances.
Several updates and improvements have been made to folding schemes. For example, the Sangria scheme generalizes folding to Plonkish arithmetization instead of just R1CS. HyperNova generalizes Nova to customizable constraint systems (CCS), a more general constraint system that can express Plonkish and AIR arithmetization.
The recent improvements to incrementally verifiable computation and proof-carrying data (a generalization of IVC to a directed acyclic graph) are extremely promising and could allow for extremely fast, succinct verification of blockchains. More improvements are continually being made, and it’s likely that we’ll see further improvements down the line.
Toward better cryptographic security
Cryptography continually evolves, and the gap between theory and implementation becomes increasingly smaller. More interesting cryptographic protocols and novel implementations are popping up everywhere, including multi-party computation, incrementally verifiable combinations, fully homomorphic encryption, and everything in between.
We’d love to see more of these new protocols and implementations, so please let us know if you’d like a review!