在VR/MR或者是CG游戏等领域,构建带有精细纹理的三维模型资产是其中的重要环节。然而,现有的三维建模流程往往需要用户掌握一定的三维建模技能,使得普通用户难以完成3D内容创作。近期,随着3D AIGC技术的发展,使用文本或者图像生成3D物体降低了这一门槛,但在实际应用中存在可控性差,难以交互式生成和修改等问题。
那么,「是否有可能像小孩子搭」 「积木」 「一样,用户只需通过交互式地拼接基本3D形状,」 就可以实现可控的3D物体生成呢?
近日,来自「浙江大学」 「和」 「字节跳动」 「PICO」 「MR」研究团队在「SIGGRAPH2024」中发表了论文《「Coin3D: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning」》。该论文提出了一种使用文本描述驱动的3D模型可控生成方案Coin3D,可以根据用户搭建的粗糙几何模型与简单文本描述来生成带纹理的三维模型,在功能上类似于3D版本的ControlNet。
「论文链接:」 「https://arxiv.org/abs/2405.08054」
「项目主页:」 「https://zju3dv.github.io/coin3d/」
背景
为了提升算法的实用性,3D物体生成需要兼顾可控性、交互性以及生成效率。然而,现有的三维模型生成方案无法做到交互式三维可控的生成,其主要有两个技术难点:
难以精准控制:主流3D物体生成算法只支持图片/文本控制,无法在3D上直接施加控制生成过程。 无法即时交互:现有快速生成方案在生成好物体后,难以支持精细的局部编辑修改操作;或是支持局部修改但需要数小时重建才能预览修改效果,这使得在实际交互式三维建模中失去实用性。
方法
Coin3D提出的框架可以让用户以手工搭积木般先构建一个粗糙模型,并利用这一粗糙模型,从三维上直接控制最终生成模型的大致外观轮廓。基于这一设计,Coin3D提出了一种新颖的交互式生成工作流,允许用户在单次生成好物体后,对局部纹理或者几何进行生成式编辑(如修改纹理,增加新的形状块等),且不影响其余部分的几何与纹理,同时用户的生成式编辑操作可在数秒内实现快速预览。最后,Coin3D将基于粗糙模型的三维控制生成算法与神经辐射场重建技术相结合,有效提升最终导出的带纹理网格的重建质量。
「粗模引导的3D控制生成」
❝用户无需复杂建模,只需在3D建模软件中组装基本形状即可。
❞
Coin3D将3D粗糙几何模型与用户文本提示结合,控制多视图扩散生成过程。不同于常规2D扩散,这种方法在所有预设视角上同步执行去噪迭代操作,实现跨视图相关性和视图相关自注意力的整合。
为了应用粗糙几何模型于3D生成任务,Coin3D提出双路径条件预处理。首先,在粗模网格上采样表面点,用于3D控制;其次,Coin3D使用粗模的渲染轮廓和用户的文本提示生成多个2D候选图像,供用户交互式选择。
Coin3D引入3D适配器,将3D控制添加至多视图扩散流程,生成遵循粗模形状的多视图图像。Coin3D构建了一个3D控制体素,将3D体素上下文传递至扩散流程。3D适配器接收粗模特征体素和多视图图像融合体素两个输入,先体素化粗模采样点填充零初始化的占用网格,然后通过反投影和融合多视图图像,生成多视图特征量。
在每个去噪步骤中,Coin3D在体素上执行3D卷积,并将输出添加至多视图特征体素,生成3D控制体素。然后,在2D扩散模型进行多视图去噪时,通过投影来对齐相应的视图以获得2D特征图,然后将其与CLIP嵌入的候选图像特征和相机姿态嵌入输入到扩散UNet中。
训练阶段,Coin3D将每个训练物体预处理为多张图像和粗模采样,随机选择目标图像和对应的点采样,以及带有高斯噪声的时间戳。Coin3D约束网络预测添加的噪声,使用零卷积作为粗模特征卷卷积UNet,同时冻结其他层,以便在生成过程中操纵控制强度,优化目标如下:
❝简单来说,这就像是让用户在3D乐高世界里,用最简单的积木搭建出大致形状,然后Coin3D的神奇画笔(多视图扩散模型)就会根据这个形状和用户的要求,生成出多视角一致的模型照片。在这个过程中,Coin3D的3D适配器就像是一个翻译器,把用户的三维模型构建要求,转化为生成算法可以理解的语言。
❞
「交互式生成技术」
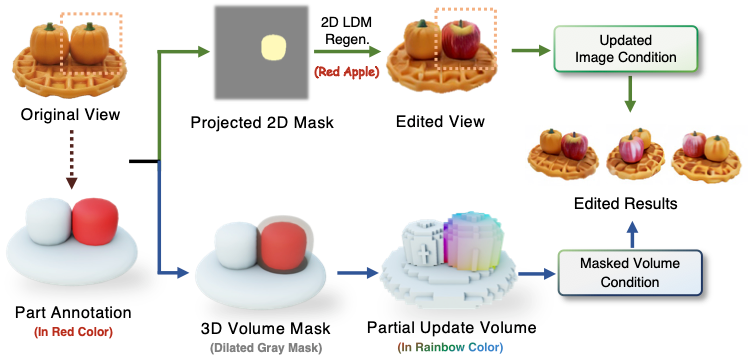
Coin3D提出了一种新颖的交互式三维生成与建模工作流程,充分利用粗模自身的可组合性来实现轻松精确的部分编辑,并重用3D控制体素进行交互式预览。具体来说,用户可以从基本形状中指定某一块区域,并重新生成这一块区域的内容。
由于多视图扩散模型同时以 3D 体素和 2D 图像为控制条件,因此,Coin3D提出了一种同时考虑2D和3D条件控制的双路径条件编辑方案。对于 2D 条件控制,Coin3D通过将遮罩粗模投影到所需的编辑视图来构建 2D 掩码,并执行基于掩码的2D重绘。然后,使用编辑后的图像作为模型去噪步骤的图像条件。对于 3D 条件控制,Coin3D首先通过略微膨胀扩大的遮罩粗模来构建 3D 体素掩码。然后,在每个去噪步骤中,Coin3D重用缓存的原始 3D 控制体素,并根据特征掩码部分更新未掩蔽的体素,如下所示:
为了保证交互生成的流畅体验,Coin3D可实现在几秒钟内预览编辑结果,并从任意角度检查编辑后的效果。具体而言,Coin3D设计了一种渐进式体素缓存机制,用于记住每个时间戳的最新3D控制体素。然后,在预览阶段,Coin3D将用户在建模软件内的视点变换迁移控制多视图扩散中的视点条件和体素投影。为了使预览功能具有快速响应,Coin3D使用缓存的 3D 控制体素,而无需重新运行 3D 适配器,并在每次去噪迭代中快速解码出每个步骤的预览预览图像,实现拖拽交互式的3D生成预览。
「基于体素蒸馏损失的纹理网格重建」
前文所述的多视图扩散模型的结果是物体的一组多视角图像(如苹果从16个环绕角度拍摄的图),因此Coin3D需要将其重建为成熟的三维表达(如带纹理的网格模型)以便于后续的 CG 应用。然而,使用生成好的多视角图像直接进行重建效果有限,而且由于视角数量较少,可能会产生不稳定的几何重建结果。因此,Coin3D设计使用三维控制体素 作为重建时的辅助监督,以提高三维重建质量,其公式如下:
简单来说,Coin3D提出了一种基于体素的分数蒸馏采样,其在神经辐射场重建的反向传播过程中嵌入了来自三维控制的梯度信息,从而实现了更好的网格重建质量。
实验与结果
这里展示了更多使用Coin3D进行可控 3D 生成的示例,其中我们使用粗模型作为控制条件,生成精细带纹理的物体。
这里展示了更多交互式生成与编辑的示例,其中用户可以精确地指定待编辑的粗模区域,并使用Coin3D进行编辑/重新生成所需的部件(例如,给企鹅添加火炬、给蛋糕添加蜡烛或将一个南瓜更换为苹果)。
同时,我们也将Coin3D与基于图像的3D生成方法(Wonder3D 和 SyncDreamer),以及提供了可控3D生成接口的方法(Latent-NeRF和Fantasia3D)进行了对比进行比较,可以看到Coin3D的生成结果能更符合用户的预期。
总结
Coin3D提出了一种三维可控的生成式3D资产制作流程,并提出了一个交互式生成的工作流,用户可以自由地改变提示词/形状控制,或重新生成指定的局部,并在几秒钟通过交互式3D预览查看修改之后的变化。
如有侵权请联系:admin#unsafe.sh