2024-7-29 21:0:52 Author: hackernoon.com(查看原文) 阅读量:5 收藏
In today's complex software systems, identifying anomalies in log files is crucial to maintaining system security and health. This is the first of three part series that explain how to build a real-time log anomaly detection system using Spring Reactor & Spring State Machine.
We'll construct the foundation for our log anomaly detection system in this first post, emphasizing the fundamental ideas and preliminary configuration.Spring Reactor is used for reactive processing and Spring State Machinefor managing states. We'll look at how Spring Reactor helps us handle log inputs in a reactive, non-blocking way, and how Spring State Machine can efficiently manage the different states of our detection process.
By the time this series ends, you will have a thorough understanding of how to use Spring Suites to create a scalable, reliable log anomaly detection system.
System Overview:
Our technique starts with reading log entries in a reactive manner. This means that we can start our investigation without waiting for the whole log file to load. Instead, we process log entries as they become available using the concepts of reactive programming. This can effectively manage logs of any size, from tiny files to enormous streams of continuous data.
A log entry is instantly run through a state machine when it has been read. The actual process of detecting anomalies is the second phase of our procedure. Here, we apply our pre-established criteria to the processed log entry. Every log entry that is processed has the potential to cause state transitions. For instance, we might go from a "normal" condition to an "alert" state in response to several warning messages.
Let's dissect it step-by-step.
Step 1: Setup the external dependency
Include Spring Web Flux project and Spring SSM in pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
<version>${spring-boot.version}</version>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>${reactor-core.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.statemachine</groupId>
<artifactId>spring-statemachine-core</artifactId>
<version>${spring-statemachine.version}</version>
</dependency>
Step 2: Define State Machine Configuration
We set Normal as the initial state and include all values of the log states
@Configuration
@EnableStateMachineFactory
public class StateMachineConfig extends StateMachineConfigurerAdapter<LogState, LogEvent> {
@Override
public void configure(StateMachineStateConfigurer<LogState, LogEvent> states) throws Exception {
states
.withStates()
.initial(LogState.NORMAL)
.states(EnumSet.allOf(LogState.class));
}
Step 3: Define State Transition
State transition occurs for following events:
-
From NORMAL to KEYWORD_ALERT, when a KEYWORD_DETECTED event occurs.
-
From KEYWORD_ALERT back to NORMAL when a NORMAL_ACTIVITY event occurs.
@Override
public void configure(StateMachineTransitionConfigurer<LogState, LogEvent> transitions) throws Exception {
transitions
.withExternal()
.source(LogState.NORMAL).target(LogState.KEYWORD_ALERT)
.event(LogEvent.KEYWORD_DETECTED)
.and()
.and()
.withExternal()
.source(LogState.KEYWORD_ALERT).target(LogState.NORMAL)
.event(LogEvent.NORMAL_ACTIVITY)
}
Step 4: Define Model Class
-
LogEvent
This lists the kinds of events that our system is capable of finding from the log entries.
public enum LogEvent {
KEYWORD_DETECTED, NORMAL_ACTIVITY
}
- KEYWORD_DETECTED: Triggered when a specific keyword or pattern is found in a log message.
- NORMAL_ACTIVITY: Represents standard log pattern.
-
LogEntry:
This record class represents a single log entry in our system. It encapsulates key information about each log.
public record LogEntry(LocalDateTime timestamp, String apiEndpoint, String message) {
}
- timestamp: When the log entry was created.
- apiEndpoint: The API endpoint involved in the logged event.
- message: The actual log message content.
- isError: A boolean flag indicating whether this log entry represents an error.
"Using a record allows for a concise, immutable data structure, perfect for log entries that should remain unchanged once created."
-
LogState:
This enum defines the possible states of our anomaly detection system:
public enum LogState {
NORMAL, KEYWORD_ALERT
}
- Normal: The default state when no anomalies are detected.
- Keyword Alert: when a keyword triggering an alert is detected.
-
AnomalyResult:
This record represents the outcome of our anomaly detection process for a given log entry:
public record AnomalyResult(LogEntry entry, LogState state) {}
Step 5: Analyze at regular Intervals
public Flux<AnomalyResult> detectKeywordBasedAnomalies(Flux<LogEntry> logEntries) {
return logEntries.window(Duration.ofMinutes(10)).flatMap(this::processLogsForGivenWindow)
.filter(result -> result.state() != LogState.NORMAL);
}
The method takes a flux of LogEntry objects as input.. Next, we organize log entries into 10-minute chunks using the window operator. As a result, a Flux<flux> is created, with log entries for a duration of 10 minutes. Then we use the flatMap method, which flattens the Flux of Flux<LogEntry> to a Flux<LogEntry>. Finally, we filter out any results that have a NORMAL state. This ensures that we only return actual anomalies, not normal log entries.
Step 6: Integrate with State Machine
private Flux<AnomalyResult> processLogsForGivenWindow(Flux<LogEntry> entries) {
StateMachine<LogState, LogEvent> stateMachine = stateMachineFactory.getStateMachine();
return stateMachine.startReactively()
.thenMany(entries.flatMap(entry -> detectAnomaly(entry, stateMachine)))
.doFinally(signalType -> stateMachine.stopReactively());
}
This method implements a cascading anomaly detection strategy for each log entry:
private Mono<AnomalyResult> detectAnomaly(LogEntry entry, StateMachine<LogState, LogEvent> stateMachine) {
return detectKeywordBasedAnomoly(entry, stateMachine)
.switchIfEmpty(Mono.just(new AnomalyResult(entry, LogState.NORMAL)));
}
Step 7: Implement keyboard-based Detection
This feature looks through the log message for predefined keywords. A KEYWORD_DETECTED event is triggered in the state machine if a keyword is found. After that, it moves to a KEYWORD_ALERT state and determines if the state machine received the event. The transition produces an AnomalyResult, with KEYWORD_ALERT. It gives an empty result if the state transition doesn't happen or if no keyword is discovered.
private Mono<AnomalyResult> detectKeywordBasedAnomoly(LogEntry entry, StateMachine<LogState, LogEvent> stateMachine) {
return Mono.justOrEmpty(keywordsToDetect.stream()
.filter(keyword -> entry.message().toLowerCase().contains(keyword)).findFirst().map(__ -> {
Message<LogEvent> eventMessage = MessageBuilder.withPayload(LogEvent.KEYWORD_DETECTED).build();
Flux<StateMachineEventResult<LogState, LogEvent>> results = stateMachine
.sendEvent(Mono.just(eventMessage));
return results.next().flatMap(result -> {
if (result.getResultType() == StateMachineEventResult.ResultType.ACCEPTED) {
return Mono.just(new AnomalyResult(entry, LogState.KEYWORD_ALERT));
} else {
return Mono.empty();
}
});
})).flatMap(mono -> mono);
}
Step 8: Expose as an API to the outside world:
Here, flux utilization is essential. It makes it possible for our API to process potentially infinite data streams in a reactive, non-blocking way.
@RestController
public class AnomalyDetectionController {
private final AnomalyDetectionService anomalyDetectionService;
public AnomalyDetectionController(AnomalyDetectionService anomalyDetectionService) {
this.anomalyDetectionService = anomalyDetectionService;
}
@PostMapping("/detect-anomalies")
public Flux<AnomalyResult> detectAnomalies(@RequestBody Flux<LogEntry> logEntries) {
return anomalyDetectionService.detectAnomalies(logEntries);
}
}
Step 6: Testing:
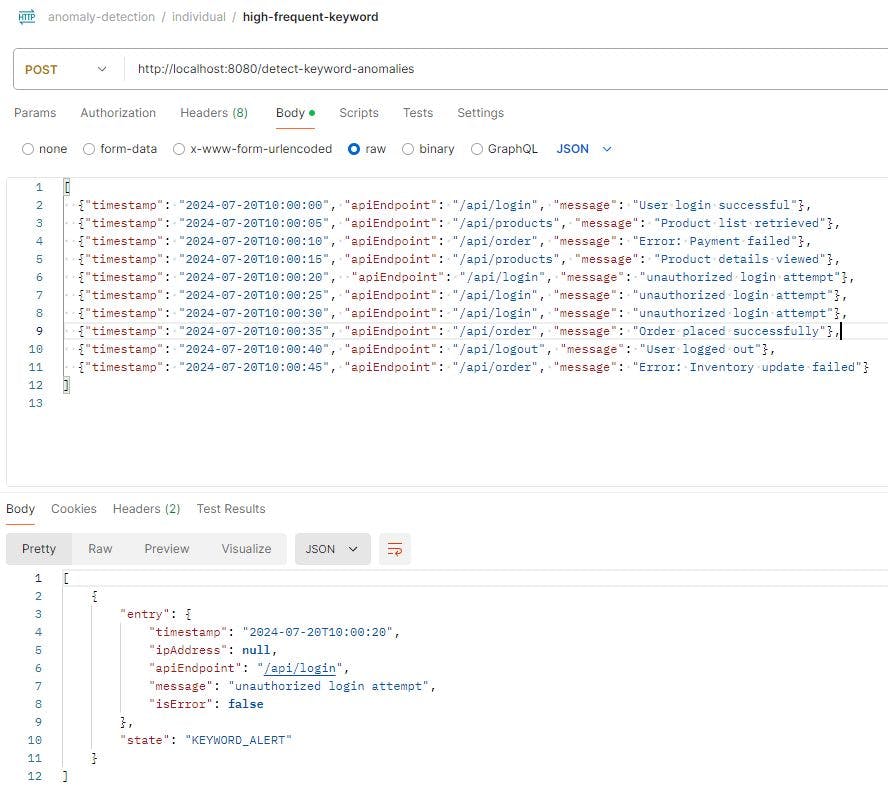
To test the API, Postman is the recommended tool for this purpose.

Step 7: Conclusion:
By leveraging the Spring State Machine, we've developed a good starting point for managing the various states of our anomaly detection process. Spring Reactor has enabled us to handle log entries reactively, ensuring our system can efficiently process high volumes of data.
Stay tuned for Part 2, where we'll dive into error rate detection and how it can provide early warnings of system issues or potential security threats. We'll explore techniques for setting dynamic thresholds and handling different types of errors, further enhancing the power and flexibility of our log anomaly detection system.
如有侵权请联系:admin#unsafe.sh