基本信息
原文名称:Prompt Fuzzing for Fuzz Driver
Generation
原文作者:Yunlong Lyu; Yuxuan Xie; Peng Chen;
Hao Chen
原文链接:http://arxiv.org/abs/2312.17677
发表期刊:ACM CCS 2024会议(接收但未发表)
开源代码:https://github.com/PromptFuzz/
PromptFuzz
一、引言
二、研究动机
库模糊测试需要一个模糊测试驱动(Fuzz Driver)来将库提供的API转化成一个可执行程序,从而对库进行模糊测试(如图1)。为了节省编写驱动的人力成本,并提升库模糊测试的覆盖率,学术界进行了许多自动化生成fuzz driver的尝试。
与手动编写的模糊测试驱动程序相比,自动化生成技术通过从源代码或运行时反馈中学习库API的使用来导出模糊测试驱动程序。FUDGE、FuzzGen和UTopia静态提取源代码中的API使用代码,而APICraft和WINNIE则从进程的执行轨迹中动态记录API调用序列。然而,由于轨迹仅包含消费者代码调用的API调用序列,这种方法无法学习消费者代码中不存在的有效API使用。最新的模糊测试驱动生成解决方案Hopper将库模糊测试问题转化为解释性模糊测试问题,从API调用的动态反馈中学习有效的API使用。尽管它可以覆盖大多数API函数,但在广阔的搜索空间中找到到达深层状态的有用API调用序列需要进行许多尝试。
近年来兴起的大语言模型(LLM)技术在代码生成领域表现卓越。借助大语言模型,论文可以很轻易地生成对于特定库而言合法的API调用序列,而不需要进行长时间的探索。之前基于LLM的库模糊测试工具,其提示词所涵盖的内容和场景相对有限,于是本文希望扩充提示词的空间,通过变异提示词的方式来实现对于库深层状态的探索。
三、概述
(1) PromptFuzz 从 C/C++ 库的头文件中提取函数签名和类型定义,并使用它们来构建提示,以指导大型语言模型(LLM)生成调用这些函数的程序。
(2) PromptFuzz 执行生成的程序,根据其运行时行为进行验证,并淘汰错误的程序。在执行过程中,PromptFuzz 还收集代码覆盖率。
(3) PromptFuzz 将通过验证的程序存储在种子库中,然后使用它们的代码覆盖率作为反馈,变异提示以向更有可能探索新代码路径的 API 函数推进。这个迭代过程会持续进行,直到 PromptFuzz 发现没有新路径或耗尽查询预算。
(4) 最后,PromptFuzz 推断种子程序中库 API 函数所施加的约束。它将 LLM 生成的库 API 调用参数从常量转换为变量,这些变量可以接受由模糊测试器提供的任意值,同时保留推断出的约束。为检测库中的错误,PromptFuzz 将所有转换后的种子程序整合到一个模糊测试驱动程序中,然后调度每个种子程序进行模糊测试,使用模糊测试器提供的随机字节进行测试。
任务(task) 上下文(library context) 规范(library specification)
其中规范是可选项,仅在某些库需要额外说明的时候添加。
任务部分要求LLM为指定的库生成包含特定API集合的模糊测试驱动。
上下文部分包括了包含上述API的头文件、API的签名、API所使用的类型定义。上下文部分是对于所选API集合的补充说明。
可以说,PromptFuzz的提示词由所选的API集合唯一确定。这样一来,本文所设定的变异提示词的目标就转化为了API集合的变异问题。
图 3 PromptFuzz提示词模板
受训练数据偏差和LLM代码生成能力不完善的限制,LLMs生成的代码可能会有错误。一个好的模糊测试目标至少应该是代码本身没有任何错误,以便所有运行时错误都归因于目标调用的库代码。论文使用如下技术来识别由LLMs生成的错误程序,如图4所示。
图 4 错误程序识别方法
错误程序识别包括如下过程:
(1) 它删除了由 C/C++ 编译器识别出的语法错误程序。
(2) 它将剩余的程序编译成可执行文件,并结合多个运行时监视器,这些监视器捕捉并分析偏离预期行为模式的情况。
(3) PromptFuzz 使用提供的语料库对这些程序进行模糊测试,并删除任何被监视器检测到偏差的程序。在模糊测试过程中,PromptFuzz 将触发独特行为的输入添加到语料库中,扩展语料库以进行更彻底的基于运行时的验证。模糊测试后,PromptFuzz 计算这些程序达到的代码覆盖率,并删除那些未达到代码覆盖标准的程序,表明库 API 函数得到了充分的利用。
在Fuzz验证的过程中,PromptFuzz收集能够触发新路径的输入,作为该种子程序(seed program)的在最终模糊测试过程中的初始种子。Fuzz验证过程中的覆盖率标准为是否触发关键路径(critical path),这里的关键路径是指生成的种子程序中包含API调用最多的路径。
为了让覆盖率反馈作用于提示词的变异,也就是API的选取,本文设计了如下两个指标:API的能量(energy)和种子程序的质量(quality)。
API能量的定义如下所示。其中表示库中的第个API。表示该API被探索的程度,其中的分支覆盖统计了API 及其所调用或间接调用的所有API函数内的分支覆盖率。 表示了该API继续被探索的价值。表示包含该API的种子程序的个数,表示包含该API的提示词的个数。探索程度越高energy 越低,探索次数越多energy越低。
在每次模糊测试的迭代过程中,PromptFuzz 会探索种子库并更新这些种子程序的质量。利用库 API 的能量反馈和种子质量,PromptFuzz 应用算法1来选择在下一次迭代中使用的新API组合。如果当前迭代中的种子程序不足,PromptFuzz 进入预热阶段(算法1的第3-7行),随机选择高能量API函数以探索之前未发现的库使用。在变异阶段(算法1的第9-23行),PromptFuzz 使用种子程序关键路径上的API调用序列作为变异的枢纽,丢弃那些不与其他API调用交互的调用。将变异集中在枢纽上,使PromptFuzz能够探索复杂的API使用。最后,PromptFuzz 使用新的API组合构建下一次程序生成的提示。
这一阶段分为两步:
(1) 对于种子程序的修改:将种子程序中,库API调用中的常数转变为一个同类型的随机变量。并实现与一个FuzzedDataProvider,从模糊测试引擎的输入中分割出特定字节并赋值给对应的随机变量。在这一步中,还进行了参数约束的提取,详情参见论文原文。
(2) 将为特定库生成的所有种子程序统合成一个Fuzz Driver。通过模糊测试引擎输入的前几字节的值来决定调度哪一个种子程序进行模糊测试。
另外,最终的模糊测试过程的初始种子来自于:
(2) 常数转化阶段,转化之前的常数值。
四、评估
1.总体效果
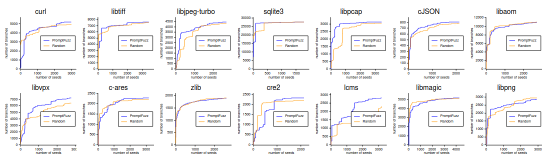
图 5 PromptFuzz在几个C/C++库上的总体效果
PromptFuzz成功地在204小时内为这14个库生成了3785个种子程序,查询LLMs的成本为63.14美元(平均每个库4.15美元)。总体而言,PromptFuzz生成的模糊测试驱动程序在测试库上实现了40.07%的分支覆盖率,比OSS-Fuzz高1.61倍,比Hopper高1.63倍,并在24小时的实验中检测到了30个之前未知的错误。所有发现的错误均已报告给相应的社区。
2.漏洞检测有效性
图 6 PromptFuzz 发现的漏洞
如图所示,PromptFuzz在24小时运行中发现了30个bug,在继续运行两周后发现了3个bug。
漏洞检测的准确性(精确率)探究。论文分析了前几次模糊测试产生的无效警告的根本原因。在14个无效警告中,有8个警告是由于库API调用返回的空指针解引用引起的。对库API调用的参数进行转换显著增强了模糊测试驱动程序的漏洞发现能力,但也增加了库API调用进入错误状态并返回空指针的可能性。如果随后的库API调用访问这些空指针而未实现对这些空指针参数的处理,可能会导致虚假崩溃。论文不认为这些崩溃是PromptFuzz在漏洞检测中的误报。相反,它们是由于库API函数未能处理传递的空指针而引起的鲁棒性问题。在排除了由于库API鲁棒性问题导致的8个警告后,仅有6个崩溃被识别为PromptFuzz漏洞检测中的误报。论文认为PromptFuzz实现了86.36%(38/44)的检测准确率。在这6个误报中,有2个崩溃是由于PromptFuzz未能从库中推断出的约束条件引起的。这些约束条件未能得出,是因为语言模型未能为相应的库API函数生成正确的使用方法,因此导致其参数的转换触发了违规行为。剩下的4个误报被视为目标库的误用,因为它们通过复杂的触发机制逃过了PromptFuzz的验证。例如,在zlib中发现的一个误报只能通过特殊值2触发,而在libpng中发现的问题则需要向png_write_png3传递一致的参数集。
3.PromptFuzz组件的有效性
图 7 错误程序删除和约束提取过程影响
图7展示了错误程序删除阶段删除的种子程序数量和约束提取阶段获得的正确约束的数量及占比。
错误程序删除。为了调查这些程序是否被正确地删除,论文进行了一项研究,其中论文为通过模糊验证消除的每个库随机选择了10个程序,并为通过覆盖率验证消除的10个程序。论文审查了这些程序的代码,并进行了仔细的调试,以确定它们是否已被正确删除。结果表明,几乎所有被模糊验证消除的140个程序都包含对库API函数的误用。唯一的例外是FSan在libpcap6中检测到的潜在资源泄漏。这个真正的错误源于函数pcap_create和pcap_close之间不匹配的资源分配和释放导致的文件描述符泄漏。如果没有FSan,libpcap中最常用的代码模式中这样一个隐藏的bug就永远不会被发现。对于覆盖率验证所消除的140个程序,其中108个程序被确认具有错误的库使用,并且由于存在无法访问的库API调用而被正确地消除。其中,25个是由不正确的库初始化引起的,40个是由错误的API上下文引起的,43个是由无效的库API配置引起的。剩余的32个程序被错误地删除了,因为模糊器无法生成可以到达某些库API调用的输入,而这些调用在为PromptFuzz的模糊化验证过程分配的时间预算内理论上是可以到达的。
参数约束推理。在第3.5.1节中,论文提出了推断对库API函数参数施加的约束的技术,并将库API调用参数转换为从模糊器接收随机字节。为了评估PromptFuzz约束推理的准确性,论文检查了测试库的文档,以收集API参数约束的基本事实。如表3所示,PromptFuzz在自变量约束的推理上实现了91.24%(250/274)的准确率和79.61%(250/314)的召回率。误报主要是由于库API函数的声明中缺少参数标识符。这种缺陷阻碍了LLM理解这些参数功能的能力,从而导致不准确的库API使用生成。值得注意的是,PromptFuzz推断的约束旨在限制API参数常量的错误转换。因此,推断约束中的误报不会导致额外的虚假崩溃。假阴性主要是因为LLM还没有为相关库API函数生成代码,而且它们很少在错误检测中导致假阳性。有了这些推断的约束,PromptFuzz可以转换库API参数以接收随机字节,而不会违反开发人员施加的约束。
在发现的33个bug中,有15个bug只能在开启常数参数转换的情况下被检测到。
覆盖率引导的提示词变异。图5显示了使用两种不同的变异方法配置时,生成的种子程序在PromptFuzz的模糊循环期间获得的累积覆盖分支。在给定相同的查询预算时,覆盖引导变异在14个库中的11个库中优于随机盲变异,但libaom、zlib和libpng除外。尽管在预热阶段分支覆盖的增长率较低,但由于覆盖和种子程序获得的反馈,覆盖引导变异在11个库中超过了随机盲变异。这使PromptFuzz能够改变包含API函数的有意义组合的提示,创建达到更深层库状态的程序。
图 8 覆盖引导变异和盲变异下PromptFuzz生成的种子程序分支覆盖率趋势
五、讨论
序列生成分析:论文使用了顺序优先级计算规则的指导下生成有序的函数调用序列。通过分析全局变量的数据流依赖性,计算了序列中函数调用的顺序优先级。
种子变异优化:论文使用AFL中的种子突变策略,存在产生重复和无效测试用例的问题,同时,任意突变测试输入的位可能会忽略输入中某些不应该突变的关键部分,降低了在严格条件下保护的分支的概率。因此,在后续的工作中,可以集中于使fuzzer不改变测试用例的这些关键部分,使测试触发深度和复杂的状态。
六、总结
如有侵权请联系:admin#unsafe.sh