一. 前言
近年来,流量加密技术被广泛应用于保护互联网用户的隐私和匿名性。然而,这也给流量分类带来了巨大的挑战,恶意软件流量和网络犯罪分子可以通过增强隐私的加密技术逃避监测系统。相关的方法如指纹检测中的指纹很容易被篡改,统计方法很难设计通用的统计特征来应对日渐复杂的大规模应用,深度学习模型则依赖于大规模监督数据来获取有效的特征。
本文介绍一种不依赖任何明文信息、不需要人为设计特征且不依赖于大量标记数据的方法ET-BERT【1】,它从大规模未标记数据中预训练,能够利用开放世界无标记的流量通信数据学习,具有较强的泛化能力,进而在特定任务的少量标记数据上进行微调,在多种加密流分类任务中表现出较好的性能。
二、ET-BERT
加密流量分类需要从内容不可见、不均衡的流量数据中获取具有区别性的和鲁棒性的流量表示以便进行准确分类。现有解决方案的主要局限性是它们高度依赖于深度特征,而深度特征过度依赖于数据大小,并且很难对未知数据进行泛化。
预训练模型在自然语言处理、计算机视觉等领域都有很大的突破,基于预训练的方法首先采用开放世界中大规模无标记数据学习无偏数据表示,然后在有限数量的标记数据上微调,可以轻松地将此类数据表示传输到下游任务。ET-BERT正是一种新的用于分类加密流量的预训练模型,旨在从大规模未标记加密流量中学习通用的流量表示。
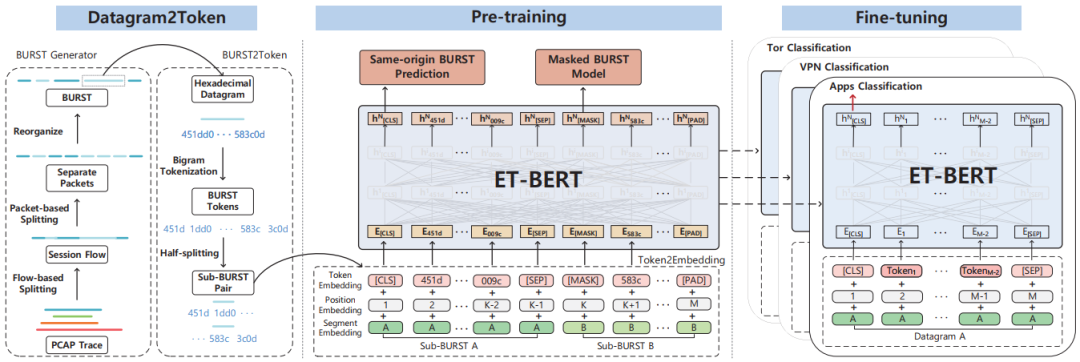
ET-BERT的框架如图1所示,主要包括Datagram2Token、预训练和微调三个部分。模型架构由12个多层双向Transformer编码器组成,编码器由多头自注意层组成,有助于捕获数据报关键部分之间的更多依赖关系,每个自注意层中有12个注意头。
图1 ET-BERT框架
2.1
Datagram2Token流量表示
首先将网络流量中的会话流转换为类似于NLP中的token,每个通信流量都由一个传输导向结构表示,表示为BURST,它作为后续预训练的输入。Datagram2Token分为三步:
(1)BURST Generator:提取会话流的部分完整信息,即单向连续报文。
BURST被定义为一组时间相邻的网络数据包,这些数据包来自单个会话流中的请求或响应。提出BURST的基本原理是,在上行链路或下行链路上批量出现的数据包之间的关系是紧密的,例如,下载图像对象时产生的多个碎片数据包将具有相同的重组所需要的识别记录。在不同的网站中,不同大小的对象可能分布在网页的不同位置,这将导致客户端所加载资源的行为发生重大变化。在这种情况下,BURST能够根据网络流量映射这种变化。
(2)BURST2Token:将每个BURST中的数据包特征化为token,此外,它将BURST分为两段,用于同源BURST预测。
为了将前面提到的BURST表示法转换为用于预训练的token表示法,将十六进制BURST分解为一个单元序列。为此,使用二进制编码十六进制序列,其中每个单元由2个字节组成,进而使用字节对编码作为词嵌入。
通过对每个token进行切片并计算单个字符的频率,生成更合适的高频邻接序列词汇表,这是无语义表示流量的理想方法。此外,还添加了特殊token [CLS]、[SEP]和[PAD]。每个序列的第一个标记总是[CLS],此标记关联的是最终隐藏层状态,用于表示分类任务的完整序列。子BURST对将由[SEP]分隔。token [PAD]是使输入满足最小长度要求的填充符号。每个数据包选择120的有效token长度,以尽可能多地表示BURST信息,最终每个token都是查找表的一行,通过预训练随机初始化和学习。
(3)Token2Emebdding:将token、token位置和BURST片段的级联嵌入纳入预训练模型,通过对这三个嵌入进行求和来构建完整的token表示。
token嵌入:从查找表中学习到的token表示称为token嵌入。
位置嵌入:由于流量数据的传输与顺序密切相关,使用位置嵌入来确保编码器能够专注于每个token的排列不变性。
分段嵌入:将第一个子BURST表示为A段,将第二半部分表示为B段,作为预训练的输入。在微调阶段,将数据包或流表示为单个段。
2.2
预训练ET-BERT
这里涉及两个预训练任务,一个是通过预测掩码token来捕获流量字节之间的上下文关系,另一个是预测同源BURST来获取正确的传输顺序。
(1)掩码BURST模型:这个任务类似于BERT所使用的掩码语言模型,关键区别在于,没有明显语义的流量token被合并到ET-BERT中,以捕获数据包字节之间的依赖关系。在预训练时,输入序列中的每个token都被随机屏蔽,概率为15%。作为选择的token,以80%的几率将其替换为[MASK],或选择一个随机token替换它,或以10%的几率保持不变。
(2)同源BURST预测:目的是捕获突发数据包的相关性来更好地学习流量表示,通过同源BURST预测任务学习BURST内部数据包之间的依赖关系。在预训练过程中,每个子BURST对随机替换,概率为50%。该任务使用二进制分类器来预测两个子BURST是否来自相同的BURST来源。
2.3
微调ET-BERT
微调可以很好地服务于下游分类任务,首先,预训练表示与流量类别无关,可以应用于任何类别的流量表示;其次,预训练模型的输入是数据包字节级,所以需要对数据包和流进行分类的下游任务可以转换为相应的数据包字节token,由模型进行分类;最后,预训练模型输出的特殊[CLS] token模拟了整个输入流量的表示,可以直接用于分类。与预训练相比,微调的成本相对较低。
微调和预训练的结构基本相同,将特定任务的包或流表示输入到预训练ET-BERT中,并在端到端模型中微调所有参数。在输出层,将[CLS]表示输入到多类分类器进行预测。另外,有两种微调策略来适应不同场景的分类,一种是包级别作为输入,专门用于测试ET-BERT是否能够适应更细粒度的流量数据,另一种是流级别作为输入,用于公平和客观地比较ET-BERT与其他方法,两种微调模型的主要区别是输入流量的信息量。
三、实验评估
3.1
数据集
为了评估ET-BERT的有效性和泛化性,在六个公共数据集和一个新提出的数据集上进行了五个加密流量分类任务的实验,任务和相应的数据集如表1所示,分别是通用加密应用程序分类(GEAC)、加密恶意软件分类(EMC)、VPN加密流分类(ETCV)、Tor上的加密应用程序分类(EACT)和基于TLS 1.3的加密应用程序分类(EAC1.3)。
表1 数据集的统计信息
3.2
数据预处理
删除了ARP (Address Resolution Protocol)和DHCP (Dynamic Host Configuration Protocol)的数据包,它们与传输内容的特定流量无关。由于包头可能会在具有强识别信息(如IP和端口)的有限集中引入偏置干扰,删除了以太网报头、IP报头和TCP报头的协议端口。在微调阶段,从所有数据集中的每个类中随机选择最多500个流和5000个包。每个数据集按照8:1:1的比例分为训练集、验证集和测试集。
3.3
评估
将ET-BERT与各种最先进的方法进行比较,包括指纹构建方法FlowPrint,统计特征方法AppScanner、CUMUL、BIND、k-fingerprinting (K-fp),深度学习方法deep Fingerprinting (DF)、FS-Net、GraphDApp、TSCRNN、Deeppacket,预训练方法PERT。实验结果如表2所示。
表2 ET-BERT与其他先进方法的结果比较
可以看出,尽管在个别场景的数据集下,FS-Net、Deeppacket 等传统模型具有强大性能展现,但在不同场景下的迁移性不足,而 ET-BERT 在所有场景下的性能表现波动明显优于对比模型。此外,该研究在测试集上实现了比其他方法更好的结果,这进一步证明了 ET-BERT 强大的泛化能力。
四、总结
本文介绍了一种新的加密流量表示模型ET-BERT,它可以从大规模的未标记数据中预训练深度上下文流量数据表示,然后通过少量特定任务的标记数据进行简单的微调,准确地对多个场景的加密流量进行分类。在通用加密应用分类、恶意软件加密分类、VPN加密流量分类、Tor加密应用分类、TLS 1.3加密应用分类等5种加密流量分类任务上均得到了较好的性能,展示出ET-BERT较强的泛化能力和鲁棒性。
【往期回顾:】
加密代理篇:
加密恶意流量篇:
加密webshell篇:
开放环境机器学习篇:
流量分析篇:
机器学习部署篇:
参考文献
[1] Lin X , Xiong G , Gou G ,et al.ET-BERT: A Contextualized Datagram Representation with Pre-training Transformers for Encrypted Traffic Classification[J]. 2022.DOI:10.48550/arXiv.2202.06335.
内容编辑:创新研究院 王萌
责任编辑:创新研究院 陈佛忠
本公众号原创文章仅代表作者观点,不代表绿盟科技立场。所有原创内容版权均属绿盟科技研究通讯。未经授权,严禁任何媒体以及微信公众号复制、转载、摘编或以其他方式使用,转载须注明来自绿盟科技研究通讯并附上本文链接。
如有侵权请联系:admin#unsafe.sh