2024-8-7 09:4:40 Author: hackernoon.com(查看原文) 阅读量:1 收藏
We live in the era of large language models (LLMs), with companies increasingly deploying models with billions of parameters. These expansive models unlock new possibilities for users but come with high deployment costs and complexity, especially on personal computers. As a result, researchers and engineers often train these large models first and then compress them while trying to minimize quality loss.
Models are released in the float16 format, where 16 bits are allocated for each weight. Two years ago, technological advancement got us to the point where we can reliably compress neural networks down to 4 bits using techniques like
A little while ago, the Yandex Research team joined efforts with their colleagues from IST Austria and KAUST to introduce a new method of achieving 8x compression through the combined use of AQLM and PV-Tuning. This method has been made publicly available to software developers and researchers, with the code published in a
Examples of popular open-source models that were compressed using this method can be downloaded
We want to shed some light on how the method was developed thanks to a brief (albeit very exciting!) "rivalry" between two research teams and their state-of-the-art compression algorithms: QuIP and AQLM. Competition fuels innovation, and this rapidly evolving story is a prime example. Every other month brings breakthroughs, optimizations, and ingenious solutions. Sit back and enjoy!
Methodology
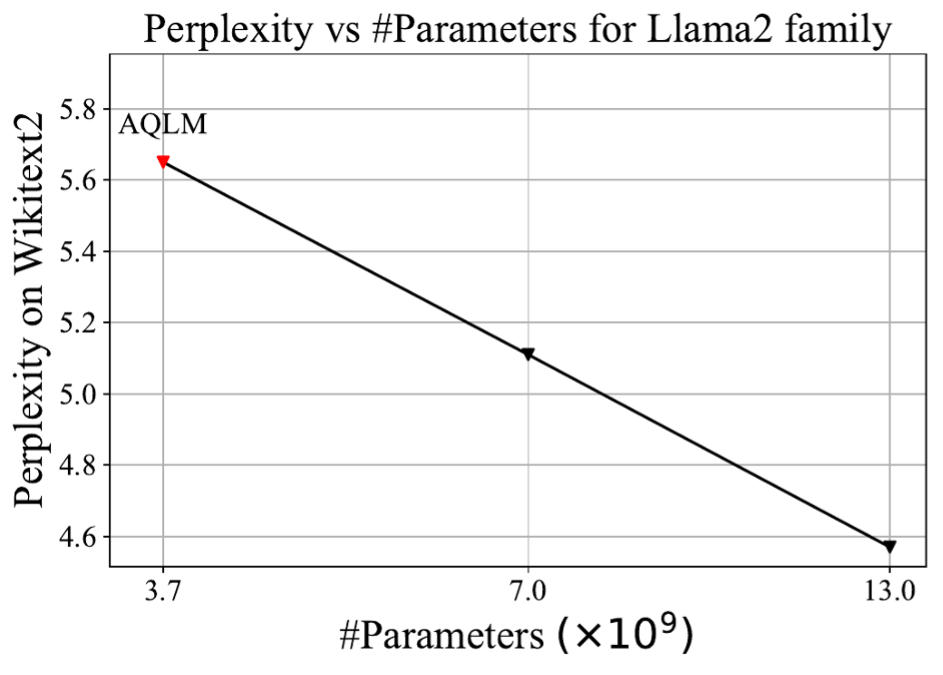
In our example, we'll be using Llama2 13b. Along with it, Meta released two more models, 7b and 70b. In academic research, perplexity is typically used to assess the quality of compressed models. This metric measures how perplexed (hence the name) a neural network gets after seeing correctly written text. Lower perplexity means a better model.
We've chosen a different primary metric for this article: effective model size. When plotting perplexity against model size, all three Llama2 models fall on the same line so that we can report a more intuitive metric.

Quantization of LLMs With Guarantees
In mid-2023, a group of scientists from Cornell University published an article titled QuIP, where the authors seriously discussed for the first time the possibility of compressing neural networks by a factor of 8 for the first time. The idea is that 99% of weights in large language models behave similarly and can be easily compressed with minimal loss.
However, the remaining 1% — outliers — significantly deviate from the norm and lead to inaccuracies during compression.
The QuIP authors devised a technique to shuffle these weights, effectively solving the outlier problem. The algorithm compresses Llama2 13b to a perplexity of 13.5. At first glance, this may seem like a poor result, as it corresponds to a model with a mere size of 0.43M parameters.
But this was the first time the perplexity remained in the double digits after compression. For reference, GPTQ compresses the same model to a perplexity of 123. So, what QuIP managed to achieve was nothing short of a breakthrough.

Extreme Compression of LLMs via Additive Quantization
Six months later, in January 2024, researchers from Yandex and the Institute of Science and Technology Austria (ISTA) published a
Ten years later, this technology was repurposed to compress large language models while maintaining maximum quality.
AQLM compresses Llama 13b to a perplexity that corresponds to the 3.7b model. This was a significant improvement over QuIP — a model like that was now actually usable.

A Close Competition — Upgrade From QuiP to QuIP#
Just a month later, researchers from Cornell struck back with a
QuIP# performed better than AQLM, improving the SOTA quantization of the Llama2-13b model to an effective size of 5.3B parameters.

A New Chapter for AQLM
In late May, a joint study by the creators of AQLM and researchers from King Abdullah University of Science and Technology (KAUST) saw light. The authors
In terms of quality, this is the best algorithm for 2-bit quantization to date. It compresses the Llama 13b model to an effective size of 6.9B, falling just a bit short of the 7b model.

Every year, neural network quantization becomes more and more efficient: inference costs are going down exponentially, and large models with open weights can now be launched on regular hardware. A few years ago, one could only dream of launching a large model like Llama3 70b on an RTX 3090. In 2024, that's already a reality.
Healthy competition among researchers is a catalyst for technological advancement, driving innovation and the development of creative approaches. How will the story unfold from here? Time will tell! And we have a feeling it won't be long.
如有侵权请联系:admin#unsafe.sh