2024-8-10 22:39:0 Author: arighi.blogspot.com(查看原文) 阅读量:16 收藏
Overview
The main bottleneck of scx_rustland, a Linux scheduler
written in Rust, is the communication between kernel and user space.
Even if the communication itself has been improved a lot using ring
buffers (BPF_MAP_TYPE_RINGBUF /
BPF_MAP_TYPE_USER_RINGBUF) the multiple level of queues is
inevitably leading to the scheduler operating in a less work-conserving
way.
This has the double effect of making the vruntime-based scheduling policy more effective (being able to accumulate more tasks and prioritizing those that have more strict latency requirements), but the queuing of tasks also has the downside of not using the CPUs at their full capacity, potentially causing regressions in terms of throughput.
To reduce this “bufferbloat” effect I have decided to re-implement
scx_rustland fully in BPF, getting rid of the user-space
overhead, and name this new scheduler scx_bpfland.
Implementation
scx_bpfland uses the same logic as
scx_rustland for classifying interactive and regular tasks.
It identifies interactive tasks based on the average number of voluntary
context switches per second, classifying them as interactive when this
average surpasses a moving threshold. Additionally, tasks that are
explicitly awakened are immediately marked as interactive and remain so
unless their average voluntary context switches fall below the
threshold.
There are per-CPU queues that are used to directly dispatch tasks to idle CPUs. If all CPUs are busy, tasks are either dispatched to a global priority queue or a global regular queue (depending if a task has been classified “interactive” or “regular”).
Tasks are then consumed from the per-CPU queues first, then from the
priority queue and lastly from the regular queue. This means that
regular tasks could be potentially starved by interactive tasks, so to
prevent indefinite starvation scx_bpfland has a “starvation
time threshold” parameter (configurable by command line) that forces the
scheduler to consume at least one task from the regular queue when the
threshold is exceeded.
Having a separate queue for the tasks classified as “interactive” that is consumed before the global regular queue allows to immediately process “interactive” events in an interrupt-like fashion.
Lastly, scx_bpfland assigns a variable time slice to
tasks, as a function of the amount of tasks waiting in the priority and
shared queues: the more tasks a waiting the shorter the time slice is.
This ensures that over a max time slice period all the queued tasks will
likely get a chance to run (depending on their priority and their
“interactiveness”).
Testing
The logic of the scheduler is quite simple, but it proves to be quite effective in practice. Of course it does not perform well in every possible scenario, but the whole purpose of the scheduler is to be extremely specialized to prioritize latency-sensitive workloads over CPU-intensive workloads.
For this reason scx_bpfland should not be
considered a replacement for the default Linux scheduler (EEVDF), that
still remains the best choice in general.
However, in some special cases, where latency matters,
scx_bpfland can deliver an improved and consistent level of
responsiveness.
This run of a selection of tests from the Phoronix Test Suite
mostly aimed at measuring latency and response time shows some of the
benefits of the aggressive prioritizaton of interactive tasks performed
by scx_bpfland.
Results

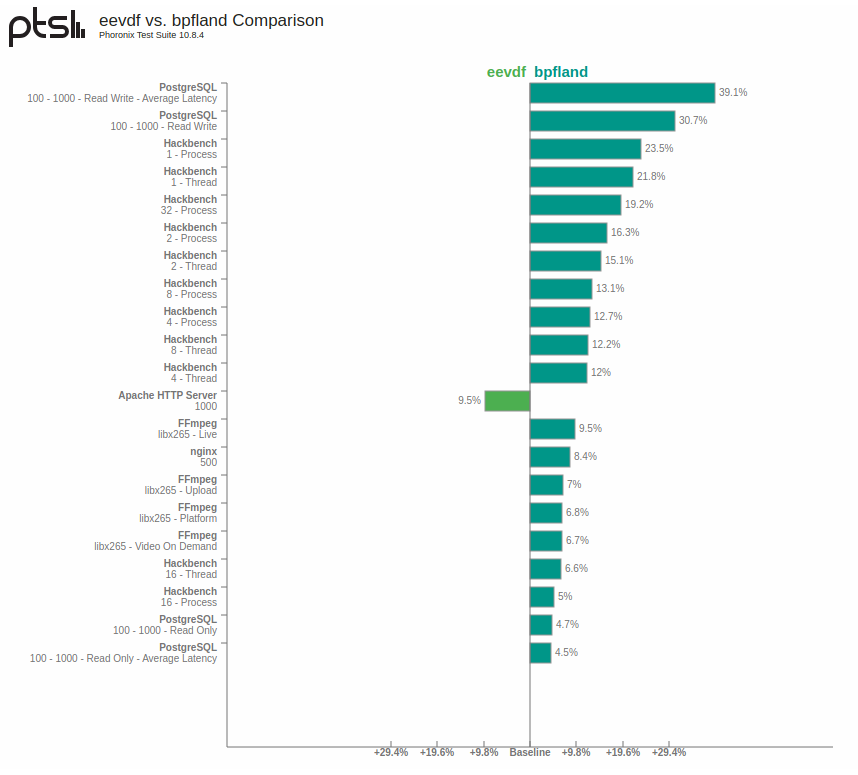
Both PostgreSQL and Hackbench show a significant boost compared to the default scheduler (up to 39% for read/write latency with PostgreSQL), since their workload is purely latency bound.
FFMpeg also shows some improvements (9% with live-streaming and 7% with the upload profile), mostly due to the fact that the workload is not purely encoding, but there’s also message passing involved (in a producer-consumer fashion).
nginx shows an improvement of 8.4%, also due to the fact that the benchmark is mostly stressing short-lived connections (measuring connection response time).
Apache, instead, shows a 9% performance regression with
scx_bpfland, compared to EEVDF.
Both the nginx and the Apache benchmarks rely on wrk, an
HTTP benchmarking tool with a multithreaded design and scalable event
notification systems via epoll and kqueue.
To better understand what is happening from a scheduler’s perspective, we can look at the distribution of the runqueue latency (the time a task spends waiting in the scheduler’s queue) of the clients (wrk) in both scenarios during a 30s run period:
[nginx - EEVDF]
@usecs:
[1] 21 | |
[2, 4) 1590 |@@@@ |
[4, 8) 6090 |@@@@@@@@@@@@@@@@@ |
[8, 16) 18371 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[16, 32) 7527 |@@@@@@@@@@@@@@@@@@@@@ |
[32, 64) 8514 |@@@@@@@@@@@@@@@@@@@@@@@@ |
[64, 128) 1915 |@@@@@ |
[128, 256) 1695 |@@@@ |
[256, 512) 2029 |@@@@@ |
[512, 1K) 2148 |@@@@@@ |
[1K, 2K) 2234 |@@@@@@ |
[2K, 4K) 2114 |@@@@@ |
[4K, 8K) 1729 |@@@@ |
[8K, 16K) 1274 |@@@ |
[16K, 32K) 740 |@@ |
[32K, 64K) 251 | |
[64K, 128K) 31 | |
[128K, 256K) 8 | |
[256K, 512K) 1 | |
[512K, 1M) 0 | |
[1M, 2M) 0 | |
[2M, 4M) 0 | |
[4M, 8M) 0 | |
[8M, 16M) 1 | |
[16M, 32M) 1 | |
Total samples: 58,284
[nginx - scx_bpfland]
@usecs:
[2, 4) 5552 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[4, 8) 6944 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[8, 16) 5813 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[16, 32) 4092 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[32, 64) 2433 |@@@@@@@@@@@@@@@@@@ |
[64, 128) 1840 |@@@@@@@@@@@@@ |
[128, 256) 1867 |@@@@@@@@@@@@@ |
[256, 512) 2499 |@@@@@@@@@@@@@@@@@@ |
[512, 1K) 3104 |@@@@@@@@@@@@@@@@@@@@@@@ |
[1K, 2K) 1902 |@@@@@@@@@@@@@@ |
[2K, 4K) 936 |@@@@@@@ |
[4K, 8K) 432 |@@@ |
[8K, 16K) 143 |@ |
[16K, 32K) 104 | |
[32K, 64K) 63 | |
[64K, 128K) 37 | |
[128K, 256K) 37 | |
[256K, 512K) 14 | |
[512K, 1M) 22 | |
[1M, 2M) 8 | |
[2M, 4M) 1 | |
[4M, 8M) 2 | |
[8M, 16M) 2 | |
[16M, 32M) 1 | |
[32M, 64M) 1 | |
Total samples: 37,849
[Apache - EEVDF]
@usecs:
[1] 22688 |@@@@@@ |
[2, 4) 178176 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[4, 8) 78276 |@@@@@@@@@@@@@@@@@@@@@@ |
[8, 16) 96198 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[16, 32) 24042 |@@@@@@@ |
[32, 64) 6795 |@ |
[64, 128) 5518 |@ |
[128, 256) 6581 |@ |
[256, 512) 7415 |@@ |
[512, 1K) 8184 |@@ |
[1K, 2K) 8709 |@@ |
[2K, 4K) 9001 |@@ |
[4K, 8K) 5881 |@ |
[8K, 16K) 2933 | |
[16K, 32K) 1255 | |
[32K, 64K) 364 | |
[64K, 128K) 72 | |
[128K, 256K) 111 | |
[256K, 512K) 50 | |
[512K, 1M) 8 | |
[1M, 2M) 0 | |
[2M, 4M) 1 | |
Total samples: 462,258
[Apache - scx_bpfland]
@usecs:
[2, 4) 1153 |@ |
[4, 8) 6057 |@@@@@@@@@ |
[8, 16) 5591 |@@@@@@@@ |
[16, 32) 4188 |@@@@@@ |
[32, 64) 5526 |@@@@@@@@ |
[64, 128) 12015 |@@@@@@@@@@@@@@@@@@ |
[128, 256) 25987 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[256, 512) 33505 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[512, 1K) 9405 |@@@@@@@@@@@@@@ |
[1K, 2K) 575 | |
[2K, 4K) 585 | |
[4K, 8K) 838 |@ |
[8K, 16K) 900 |@ |
[16K, 32K) 1166 |@ |
[32K, 64K) 1061 |@ |
[64K, 128K) 423 | |
[128K, 256K) 61 | |
[256K, 512K) 25 | |
[512K, 1M) 13 | |
[1M, 2M) 5 | |
[2M, 4M) 3 | |
[4M, 8M) 1 | |
[8M, 16M) 2 | |
Total samples: 109,085First of all let’s take a look at the amount of samples (that are collected at every task switch via bpftrace). As we can see the amount of task switches in case of Apache is much higher than nginx (around 10x).
Considering that the client is the same (wrk) the difference is clearly in the server, in fact Apache is handling reasponses in a blocking way, while nginx is handling responses in a non-blocking way.
This is also confirmed by the output of top, where we can see that nginx is using much more CPU than the client (wrk), while in the Apache case it’s the opposite.
So, in the Apache scenario both the clients and the server are
classified as “interactive” by scx_bpfland, due to their
blocking nature, while in the nginx scenario the clients (wrk) are
classified as interactive and the server (nginx) is classified as CPU
intensive, so the clients are more prioritized. This helps to improve
the overall performance of the producer/consumer pipeline, giving a
better score in the benchmark when `scx_bpfland` is used.
This is also confirmed looking at the distribution of the clients’
runqueue latency: with nginx tasks are spending less time in the
scheduler’s queue with scx_bpfland, while in the Apache
scenario it’s the opposite.
Clearly, the runqueue latency is merely a metric and doesn’t always accurately represent actual performance: tasks might spend more time in the scheduler’s queues yet still achieve improved overall performance, for instance, if the producer/consumer pipeline is better optimized. However, in this case, it seems to accurately explain the performance gaps between the two schedulers.
So, how can we improve scx_bpfland to work better also
in the Apache scenario? The performance regression can be mitigated by
not being too aggressive at scaling down the variable time slice of the
tasks in function of the waiters.
By adjusting this logic we can improve also this particular scenario,
potentially regressing others, but that’s the benefit of
sched_ext: allowing to quickly implement and conduct
experiments and implement specialized scheduler policies.
The regression with Apache shows that scx_bpfland is not
a better scheduler in general, but it highlights the fact that it’s
possible to leverage sched_ext to quickly implement and
test specialized schedulers.
Conclusion
In conclusion, prototyping new schedulers in user-space using Rust and then re-implementing them in BPF can be an effective workflow for designing new specialized schedulers.
The rapid edit/compile/test cycle provided by technologies like
sched_ext is invaluable for quickly iterating on these
prototypes, allowing developers to achieve meaningful results in a much
shorter timeframe.
scx_bpfland is a practical example of this approach,
demonstrating how initial development in a flexible Rust user-space
environment can be effectively transitioned to BPF for enhanced
performance.
This experiment not only highlights the powerful combination of
sched_ext and eBPF in enabling efficient and adaptable
scheduler development but also suggests that sched_ext
could be a fundamental step toward pluggable modular scheduling in
Linux.
如有侵权请联系:admin#unsafe.sh