
2024-8-10 22:0:21 Author: hackernoon.com(查看原文) 阅读量:7 收藏
Authors:
(1) Yujie Hu, Department of Geography, University of Florida, Gainesville, FL 32611 and UF Informatics Institute, University of Florida, Gainesville, FL 32611;
(2) Changzhen Wang, Department of Geography & Anthropology, Louisiana State University, Baton Rouge, LA 70803;
(3) Ruiyang Li, Children’s Environmental Health Initiative, Rice University, Houston, TX 77005;
(4)Fahui Wang, Department of Geography & Anthropology, Louisiana State University, Baton Rouge, LA 70803.
Table of Links
Concluding comments, Acknowledgement and References
Methodology
Data used in this research are all publicly available. The GIS layers include road networks, ZIP Code Tabulation Areas (ZCTAs) (as a surrogate for ZIP code areas), and census blocks with the 2010 demographic data for the entire U.S. They are extracted from the TIGER Products from the U.S. Census Bureau (2019). The block layer with the 2010 population data is used to generate population weighted centroids for ZIP code areas, which are more accurate representation of their locations than their geographic centroids (Wang, 2015:78). There are 32,840 ZIP code areas in this study. All data processing is performed in ESRI® ArcGIS 10.6.
Figure 1 outlines the workflow for measuring the nationwide ZIP-to-ZIP drive time matrix. The process includes three major steps: (1) obtaining a preliminary estimate of the centroid-to-centroid drive times between every two ZIP code areas, (2) using Google Maps to derive drive times for randomly-sampled OD pairs and adjusting the full drive time matrix based on regression models, and (3) incorporating the intrazonal drive times associated with both origin and destination ZIP code areas to finalize the estimation. Each of these steps is described as an algorithm in detail below.

where (a, b) and (c, d) represent the pair of longitude and latitude in radians of location i and j, respectively, and R is the average radius of the Earth. Network distance is the distance through the shortest path via a road network. Finally, network time is the travel time (here drive time) through the fastest path via a road network.
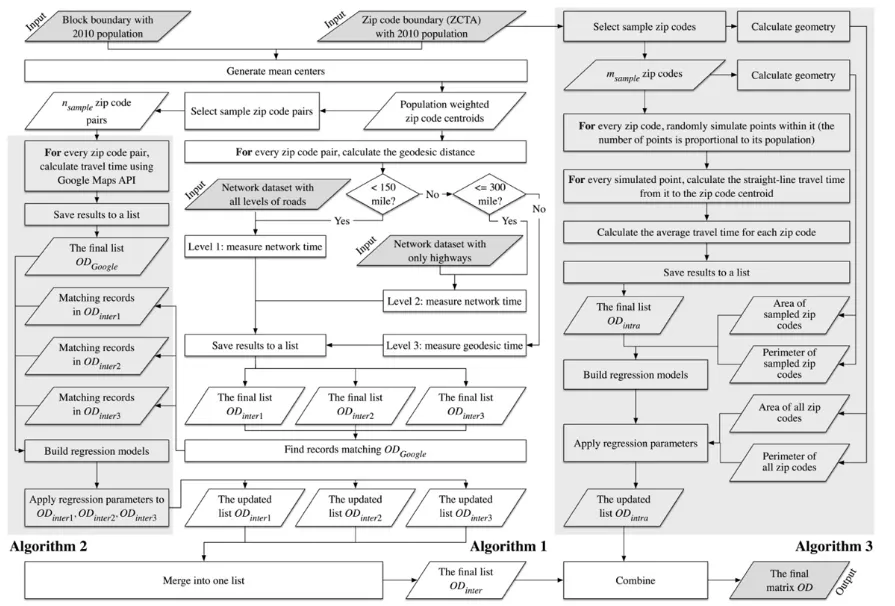
Algorithm 1: preliminary estimate of interzonal times
Algorithm 1 is developed to provide a preliminary estimate of interzonal drive times for each OD pair of ZIP codes nationwide. It consists of three levels with incremental measurement accuracy corresponding to various trip lengths. This hierarchical design is to account for varying desirability of accuracy in drive time estimation and find a balance between our need for accuracy and fast computation. For short trips, travelers consider all levels of roads in routing since their spatial behaviors are sensitive to a minor difference in drive times. For medium-range trips, most parts are completed via major roads as travelers may not plan the drive times down to precise minutes. For very long trips, travelers may only need a ballpark number in drive times to assist their decisions. Therefore, this study designs three levels of trip lengths for our purpose. Level 1 is for short-range ZIP code pairs with the highest estimation accuracy, Level 2 for middle-range ZIP code pairs with moderate accuracy, and Level 3 for long-range pairs with the least accuracy. Considering a substantial number of ZIP code pairs being long-range at the national scale, this hierarchical design drastically reduces the computation time and enables us to calibrate the national ZIP-to-ZIP time matrix on a desktop PC within a reasonable amount of time.
Level 1 utilizes the complete road network including interstates, U.S. and state highways, major roads, and local roads to calculate drive times for short-range ZIP code pairs. For computational efficacy, ZIP code pairs are screened by geodesic distance to be assigned to Level 1 if they are within 150 miles (241 km) in geodesic distance, which is equivalent to 3 hours apart with a constant speed of 50 mph (80 km/h). The 3-hour drive time cutoff is often used by health care analysts as six hours are considered the limit for a patient to make a round trip between one’s home and a health care facility and obtain services in one day (Shi et al. 2012; Onega et al. 2017). For each eligible OD pair, both trip ends are snapped onto the closest drivable streets within a 3.11-mile (5-km) search threshold. The network drive times between the snapped network locations are then measured via ArcGIS Network Analyst.
Level 2 measures the network drive times for medium-range ZIP code pairs by utilizing a road network of only interstates, U.S. and state highways. The screening for assignment of ZIP code pairs to this level is based on a range of 150-300 mile (241-483 km) in geodesic distance (equivalent to 3-6 hours with a 50 mph speed). Using the same search threshold, both origin and destination ZIP code centroids are snapped onto the simplified road network, and the network drive times are then estimated. As listed in Table 1, compared to Level 1, Level 2 trims the road network to a reasonable level of details and hence demands less computation time for each OD pair.

The remaining great number of long-range trips at Level 3 for ZIP code pairs of more than 300 miles (i.e., 6 hours) apart in geodesic distance. It is difficult for analysts with limited computational resources to estimate drive times for the OD pairs in this level via a road network—even one with reduced complexity. As stated previously, accuracy in drive times for these distant OD pairs is also less important. Therefore, this study uses the geodesic distance with a constant 50 mph speed to establish a baseline estimate of drive times in this level.
Integration of the results from the three levels yields a massive OD time matrix with 1,078,432,760 (= 32,840 * 32,839) records. A total of 32,840 (=32,840 * 1) records are missing due to the fact that most routing software packages, such as ArcGIS Network Analyst and Google Maps API, cannot measure travel distances or times from a place to itself. These remaining records are essentially intrazonal trips and will be estimated by Algorithm 3. Each record saves the origin ZIP code, destination ZIP code, preliminary estimated drive time (in minutes), distance (in miles), and the hierarchical level where time and distance are measured. Refer to Table 2 for more details, where ZIP code is simply referred to as “ZC” in the algorithms hereafter.



Algorithm 2: calibrating interzonal times on randomly sampled OD pairs by Google Maps API
In essence, Algorithm 1 returns free-flow drive times without considering traffic and road congestion for short- and medium-range OD pairs, and yields a very primitive baseline estimate for long-range OD pairs. The time estimates tend to be downward biased. Algorithm 2 improves the estimates by using Google Maps API to account for actual experiences on the road including traffic condition (Wang and Xu, 2011). Google’s most recent pay-as-you-go pricing plan supports free usage of Distance Matrix API up to 40,000 OD records per month (Hu and Downs, 2019). It is cost prohibitive to use this method to calibrate drive time for all OD pairs. We apply it only to a small subset of randomly-sampled OD pairs.
Algorithm 2 is described as the following:
-
randomly selecting a ZIP code centroid zci from ZC (iÎ[1, 32,840]) as an origin location;
-
randomly choosing a ZIP code centroid zcj from ZC (jÎ[1, 32,840] and j ≠ i) as a destination location;
-
measuring drive time tij and distance dij from zci to zcj by sending a request to Google Maps Distance Matrix API; and

Once collected, the relations between drive times derived by Algorithms 1 and 2 on the sampled subset are established through three regression models, corresponding to the three hierarchical levels in Algorithm 1. The three empirically-derived regression models are then applied to the remaining OD pairs for adjusting the preliminary estimates of drive times (and distances). Both algorithms use Google Maps drive time as the true reference values for adjusting the estimation. When no departure time is specified, such time is average time across various traffic conditions independent of time of a day or day of a week.
Algorithm 3: measuring intrazonal times
Intrazonal trips (from a ZIP code area to itself) are usually neglected in time and distance estimation models (Kordi et al., 2012; Bhatta and Larsen, 2011), including Algorithms 1 and 2, because drive time and distance are often approximated through a centroid-tocentroid approach. Built upon the method developed by Hu and Wang (2016), Algorithm 3 is proposed to measure intrazonal drive times. Similar to Algorithm 2, this process is applied to a randomly-sampled subset of ZIP code areas, as described below:

As intrazonal drive time and distance are reported to be positively related to the perimeter and area of a zone (Frost et al., 1998; Horner and Murray, 2012; Hu and Wang, 2019), several regression models are tested to identify the relations. The best fitting model is then applied to populate intrazonal drive times and distances for the remaining ZIP code areas.

The above three algorithms are coded in Python. All the analyses are carried out in a desktop PC with an Intel Core i7 processer and a 16 GB RAM.

如有侵权请联系:admin#unsafe.sh