
"I can accept failure. Everyone fails at something. But I can't accept not trying."
- Michael Jordan
First off, I really want to thank the team over at Korelogic for putting together a truly impressive contest. Korelogic always uses the CMIYC contest to push for change/improvements in password cracking tools and this event in particular was jam packed with different challenges that forced teams to really stretch their skills vs. letting their GPUs go Brrrrrrrrrrrr.
Second, I'd like to compliment the skill shown by all the players. One thing Korelogic mentioned after the contest was that the Street challenges were the same level of difficulty as those given to the Pro teams. Looking at the scoreboard and seeing street teams succeed like they did highlights the the level of ability on display. As far as the number of players who just popped on to learn something new, that's also impressive There's a ton of stuff going on during Defcon and the fact that someone decided to try their hand at a password cracking competition vs. one of the other million neat things happening is really special.
One thing that really struck me about this year's CMIYC competition was the amount of content in it. In past years I felt like I had a chance to really experience about 50-70% of the contest (the slow hashes always gave me a problem). This year I felt the number was closer to 10%. I'd see a new PCAP get dropped and go "Wow, that would be fun to decrypt. I'm sure it would give tips and/or new hashes to crack, but I have no free time to mess with that so moving on..." That's where having a blog is nice. I can revisit these challenges at my leisure, as well as incorporate lessons learned from other players' experiences and writeups. To that end I'm going to try and make a number of smaller blog posts focusing on individual aspects of the contest. Now there is going to be a lot of overlap since everything is related, but hopefully this can keep things more manageable for me so that I actually post something vs. having an entry sit in my draft folder for the next several years.
Important Links, Tools, and References for this Post:
- My JupyterLab Password Cracking Framework
- Link: https://github.com/lakiw/Jupyter-Password-Cracking-Framework
- Reason: This contest was the first time I really got to use the Jupyter Lab Password Cracking Framework in real time during a competition. While there were a lot of rough spots, it proved very helpful for dealing with the Radmin and Striphash challenges. A lot of the code I'm going to show in this blog entry is a screenshot from the tool which you can download. My apologies for not including text, but I don't know of a way to reliably render code blocks in Google blogger. Long story short, being able to download, run, and view the JupyterLab notebooks will help add context around a lot of the items discussed in this blog post.
- Disclaimer: I need to clean my Notebooks from the contest up before I push them to Github. So it may be a week or so before I actually update the repo with the examples I'm showing here.
- radmin3_to_hashcat.pl
- Link: https://github.com/hashcat/hashcat/blob/master/tools/radmin3_to_hashcat.pl
- Note: This tool is part of the base Hashcat install
- Reason: This is the primary tool to convert the Radmin3 dump that Korelogic provided to hashes that Hashcat can crack. This isn't applicable to the Striphash challenges, but I figured I'd leave it here until I write a blogpost covering cracking them.
- Example Hashcat Formatted Hashes
- Link: https://hashcat.net/wiki/doku.php?id=example_hashes
- Reason: You really should have this page bookmarked regardless of if you are competing in a competition or not. Whenever I'm starting a non-standard password cracking session I find myself referring back to this site to try to figure out what type of hash I'm dealing with, or to understand how I need to format it so I can crack it with Hashcat.
- Example John the Ripper Formatted Hashes
- Link 1: https://openwall.info/wiki/john/sample-hashes
- Link 2: https://pentestmonkey.net/cheat-sheet/john-the-ripper-hash-formats
- Reason: Just like with Hashcat, it's helpful to have some examples when trying to crack newly encountered hash formats in John the Ripper. These sites are a bit harder to read and search than Hashcat's site, but they are still a super helpful resource.
- Korelogic Score Page
- Link: https://contest-2024.korelogic.com/stats.html
- Reason: This was how I figured out what hash types were being provided to us to crack
- ADSync Hash Format
- Link: https://aadinternals.com/talks/Attacking%20Azure%20AD%20by%20abusing%20Synchronisation%20API.pdf
- Reason: Not super applicable to these challenges, but I wanted to put it here so I won't forget about it when talking about cracking ADSync hashes later.
- ThatOnePasswordWas40Passwords CMIYC2024 Writeup:
- Link: https://github.com/ThatOnePasswordWas40Passwords/crackmeifyoucan/tree/main/2024
- Reason: An excellent writeup by the winner of this year's Street competition. I highly recommend checking it out. I'm certainly still going through it and trying to learn from their experiences!
Loading the Mixed Hash Lists:
Description of Hash Lists:
At the start of the contest Korelogic provided two PGP password encrypted files as well as the decryption password. The first file, cmiyc-2024_pro_passwd_1, was a standard mixed hash list consisting of various different hash types in the general format:
- username:hash
The hashes themselves were not identified so it was up to players to figure out what hash format they were targeting. Admittedly you can often let your cracking tool autodetect hash formats, but like everything this contest provided some "twists" which meant you couldn't just rely on your password cracker's autodetect feature.
The second challenge file was a PGP password encrypted tar file, which Korelogic also provided the password for. This tar file contained a number of different encrypted hint files as well as a Windows registry entry containing Radmin password hashes. For now though, let's focus on the first mixed hash list.
Identifying Hash Types and Loading Them In the Framework:
One quick way to know what hash formats might show up in that mixed hash list is to simply look at the Korelogic scoreboard. There they listed a number of different formats:

I'll admit while some of these formats were familiar, a lot of them such as striphash, radmin3 and adsync I've never really heard of or played with before. So at the start of the contest I ended up spending a lot of time trying to figure out how to identify the hash formats and add it to the autodetection scrips in the JupyterLab Framework. To do that I heavily relied on the HashCat and John the Ripper hash example websites listed above, as well as a healthy degree of googling for things like "hashcat adsync".
To share my findings, in the JupyterLab Framework there is a file called hash_fingerprint.py that is responsible for detecting the hash type given a raw password hash. This python code uses two different ways to detect a password hash type. The first method is to look for distinctive formatting options of the hash itself. This basically boils down to a lot of "if/then" statements such as what's below:
elif raw_hash.startswith("$radmin3$"):
hash_info['jtr_mode'] = "unknown"
hash_info['hc_mode'] = "29200"
hash_info['type'] = "radmin3"
hash_info['cost'] = "medium"
This code will identify the following has as type Radmin3:
- $radmin3$75007300650072006e0061006d006500*c63[Results Truncated]
The second way to identify hash types is based on the length of the hash. This is much more problematic since many different hash types have the same length. For example MD4 and MD5 hashes have the exact same length. Therefore you can feed the Python script a list of the hash types you expect to find in the dataset your are processing to help deconflict hashes of the same length.
Now this isn't ideal. First of all, this is code I'm maintaining so there's huge gaps in the hashes it supports. I basically ended up spending a bunch of time at the start of the contest updating the script to support new hash types vs. actually doing cracking. Also, the detection logic and code quality leave a lot of room for improvements. That's one area where I was really excited to learn from "That One Password was 40 Passwords" writeup (linked above). They mentioned a python library called "Name That Hash" [Link] that I was not previously aware of. I need to check that out to see if I can outsource some of that work to other tools and limit the amount of work I need to do to intake contest hashes.
Question: Are you aware of any other scripts or library for autodetecting hash formats that doesn't involve just running Hashcat/JtR/MDXFind and letting them try to load and crack the hashes?
- Reason: I'd love to make use of an existing toolset/effort vs. trying to implement and maintain my own Python code. So if you have any suggestions, please let me know!
That's a lot of words to say that once I loaded cmiyc-2024_pro_passwd_1 into my JupyterLab framework I got three main warnings/errors.
- It did not find any Radmin3 hashes despite the fact that I put them down as a potential target
- This makes sense, since there is a huge file of Radmin3 hashes in the second challenge file (the tar archive).
- No hashes of type Striphash were found
- This also makes sense since I couldn't find any reference to an official hash format called striphash. So I hadn't added a signature for it into the hash autodetect script
- An absolute ton of uncategorized hashes were found, ranging from length 33 to length 40 bytes long.
- Based on the name "Striphash", I suspected that striphash represented truncated password hashes.
To that end I created a custom length helper for each length of striphash (aka striphash34, striphash35, etc), since I figured there might be some unique features of cracking each hash length so I wanted to keep them in different categories for cracking/analysis. Once I did that I was able to read in the full mixed hash list into my JupyterLab framework. This was nice since not only did it let me quickly be able to access the hashes and metadata and write custom Python scripts, but I could also print out a scoreboard and track how many hashes were in each category without having to depend on the public Korelogic scoreboard. I'll talk about this more later, but this helped when I was troubleshooting different attacks against the striphashes.

Cracking Striphash:
Identifying the Base Hashing Algorithm:
Now, my original theory was that Striphash was a set of truncated hashes, but that still left the question open: What was the original hashing algorithm? How can we figure that out?
- Option #1: Use MDXFind to identify unknown hashes
- MDXFind is an amazing password cracking tool for cracking unknown and nested hashes. If you don't know how a salt is applied to a hashing algorithm, MDXFind is the go-to tool for cracking that hash. Now MDXFind isn't magic. It still requires you to configure it to run an effective/successful cracking session. But MDXFind automates all the various hash format mangling tasks that you might have to do manually otherwise.
- Tutorial: I have some base instruction on how to install and use MDXFind in the blog post linked below. It is under "Tip #4: Leverage MDXFind to identify unknown hash types".
- Link: https://reusablesec.blogspot.com/2022/05/password-cracking-tips-crackthecon.html
- Option #2: Look at the hash length, and then manually YOLO it
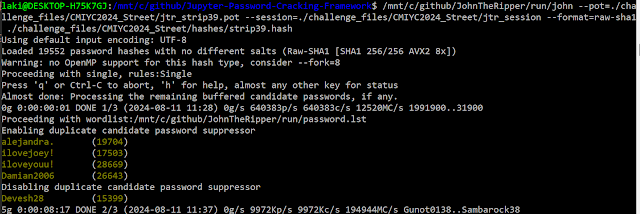
- I may have taken this approach during the contest. I'm not proud of it. But I looked at the longest Striphash being 40 bytes, went "hey that's how long a Raw-SHA1 hash is!" and then threw it into a John the Ripper cracking session using that format to see if I cracked anything.
- John the Ripper's Single mode attack can be very good for this. It combines attacks against the username (if one exists), and a pretty good "base" wordlist and mangling rules that usually will crack something on larger password dumps. It will then switch to Incremental (Markov enhanced brute force) if those attacks are not successful, giving you an even better chance of cracking a weak password.
Here is a screenshot of me YOLOing it:

Given these results, my going assumption was that Striphash was a bunch of truncated Raw-SHA1 hashes. This was additionally boosted by the very famous 2012 LinkedIn breach where in the initial dump all the hashes had their first five bytes replaced by zeros [Link]. As a spoiler, this assumption wasn't exactly right.... But it was a good place to start from.
Cracking StripHash39:
Given the 39 byte hashes were likely missing a single byte, I could recreate the hashes by simply adding on an extra byte to them. That increases their size by a factor of 16 [0-F], but is totally doable for the 1222 StripHash39 hashes. In the JupyterLab Framework I have a function called ServiceMgr.create_left_list(format, file_name, hash_type, metadata) which returns a list of hashes I haven't cracked yet while also allowing me to further limit the results based on hash types and metadata filters. I can then write a quick Python script to append a hexadecimal character to the end and write it back to a file to crack.

Easy Peasy Leamon Squeezy. The only thing remaining was to try my YOLO hash detection method (run a basic attack against this using JtR's Single mode) and see if I get any cracks....
Annnnnd nothing...
Thinking for a second, I realized maybe I should have inserted the extra hexadecimal character on the front of the hash like in the LinkedIn breach. It was a quick one line change to modify the file write in the script above. Then all I had to do was rerun the cell and conduct another YOLO JtR Single attack. This time it yielded better results.

Looking at my potfile of cracked passwords also revealed something interesting.

Looks like all of the cracked hashes started with a '0'. That would seem to make things a lot easier, as rather than increase the size of my cracking file by a factor of 16, it doesn't increase the size at all. Still, something didn't sit right with me. Going back to the hash distributions above the number of each length strip hashes was:
- raw-sha1 :884
- striphash39 :1222
- striphash38 :785
- striphash37 :332
- striphash36 :87
- striphash35 :16
- striphash34 :4
- striphash33 :1
If striphash39 was just all the hashes with a leading 0, it should be roughly 1/15th the size of striphash40 (raw-sha1). But there are more hashes for it. I'll admit in the moment I shrugged off that bad feeling thinking that Korelogic must have just increased the included hashes with a leading zero so they would be worth more relative points for figuring out how to add the 0 to the front. But I should have listened to that bad feeling more. But we'll get back to that!
Cracking StripHash38:
Given the success with StripHash39, it seems like it would be straightforward to generate hashes for StripHash38. Just add two 0's in the front of the hashes! But doing that didn't yield any cracks. Same problem with other variations, such as adding two 0's to the end of the hash, or one 0 at the front and the end. What's going on?
I was obviously missing something and that's when I thought back to the length distributions. It didn't make sense. So manually looking at the hashes I started to get a hunch. To verify that hunch I wrote a quick and dirty script to see if there were other positions besides the first hexadecimal number where 0's did not show up in the Strip40 hashes.

I'm not proud of the code, but it works and when I'm troubleshooting a problem I figure it's better to get something running vs. trying to make it pretty. Going through each position in the hash I found that there were no 0's in any even spot of the Strip40 hashes (zero-indexed). Or in the way we speak about it, there were no 0's in any odd spot (aka the 1st character, the 3rd character, the 5th character, etc).
This meant I was missing out on even attacking a large number of the Strip39 hashes since that 0 could have been stripped out of 19 other locations. Modifying my code was pretty easy and now I could start targeting all of the Strip39 hashes along with Strip38 hashes, all the way to Strip33. Below is an example of my Strip38 hash generation code:

Note: Some of the complexity in the hash generation was me trying to get fancy and update the target user to include information on which 0's were added to the hash. I was worried about how to convert these hashes back so I could submit them to Korelogic for points. Later on when I went to submit them though I found a much more elegant (and easy) solution. Since I had all the username/hashes loaded up in the Framework, I could simply generate a list of users/cracked-passwords using John the Ripper's show function. For example you can run:
- john --show --pot=[PATH TO YOUR POTFILE] [HASHLIST]
This will print all your cracked hashes along with the usernames associated with those hashes from the [HASHLIST]. Here is me running that command:

The first value in the username listed there is the JupyterLab Frameword's internal ID for a hash since I figured the same user might have multiple different hashes in a challenge set. If I had my act together I would have included the real username in the cracking files to aid in Single mode attacks, but this helped me read the results of the "john --show" command back in and associate the cracks with the truncated hashes Korelogic expected us to submit to them.

Once I had the cracked hashes back in the JupyterLab framework I could then use my normal scripts to generate a submission of newly cracked hashes to Korelogic.
Addendum: Cool Hashcat Fact
One thing I learned after the contest is that Hashcat will ignore the first five byes of a raw-SHA1 hash. This is a holdover of a modification to allow it to natively crack the original mangled LinkedIn dump, but it also means you could have used it to crack at least some of the Striphash challenges without really knowing what was going on under the hood. Here is a forum post talking about this [Link].
Quoting the example in the article:
SHA1(testing123) = 4c0d2b951ffabd6f9a10489dc40fc356ec1d26d5
But hashcat will find this hash for testing123:
hashcat -m 100 -a3 00000b951ffabd6f9a10489dc40fc356ec1d26d5 testing?d?d?d
00000b951ffabd6f9a10489dc40fc356ec1d26d5:testing123
More discussion was had about this in the after-the-contest Korelogic CMIYC Discord channel where it was revealed that most password crackers ignore a lot of the bits of different hash types when doing comparisons. In practice this isn't a problem (and it yields significant speed bonuses) since the chances of a random collision occurring are astronomically low. But now that Korelogic knows about that, well it's something to keep in mind for next year's contest!
Actually Running Cracking Sessions:
I know this entire blog post focused on setting up cracking sessions for targeting the Striphashes, but I haven't really talked about how to go about actually cracking them once all the plumbing has been taken care of. I'm going to defer that conversation to a later blog post since:
- This post is already too long
- I'm still learning about how these plaintexts were generated myself. Most of my attacks were not as successful as I expected they would be. I need to dig more into why that's the case.
Now I have a pretty good suspicion that the solution to cracking these hashes was scattered throughout all the hints and sub-challenges Korelogic released during the contest. While I didn't have time to dig into those hints/challenges during the contest, I can certainly investigate them now even though the contest is over. So that's a lot of words to say, I'll try to address this in a future blog post.
Conclusion:
I hope this was helpful. The striphashes weren't worth a lot of points, so spending time on these was more of a side-quest than trying to rank up in the contest itself. Still I had a lot of fun trying to figure this challenge out. In the upcoming weeks I will try to post more challenge focused blog entries (Next up: The RAdmin hash challenge) as well as a more general overall writeup of my experiences competing in the contest as a whole. I will also try to update the JupyerLab framework with the lessons learned from this contest. Some of the big items are John the Ripper log cleanup scripts (since the logs take too long to parse for my liking), better support for viewing cracked hashes, and better support for automatic hash submission. I'd also like to try out some 3rd party libraries for hash identification vs. using my own code for that. Anyways, it gives me an excuse to do something else than update my PCFG code which is something I've been procrastinating on for (cough) years ;p
如有侵权请联系:admin#unsafe.sh