2024-8-14 22:58:25 Author: hackernoon.com(查看原文) 阅读量:3 收藏
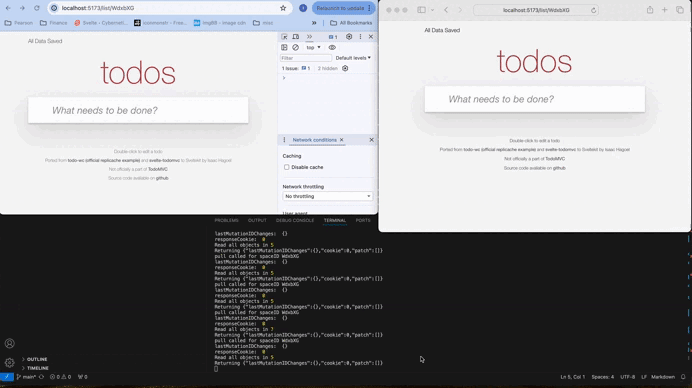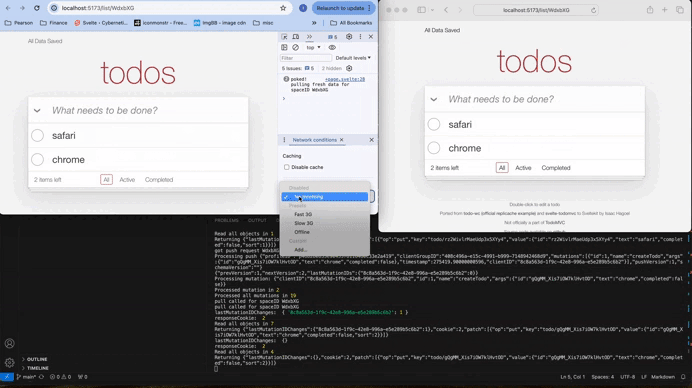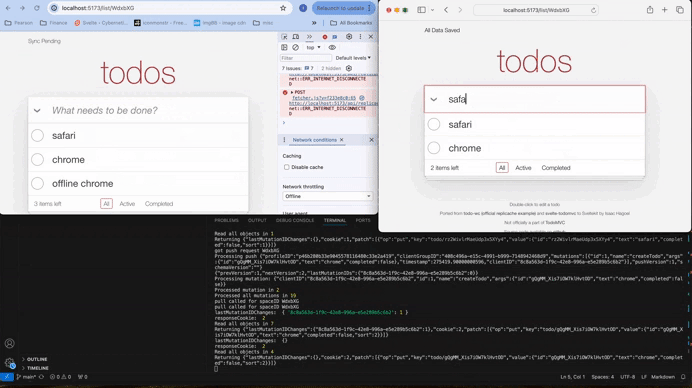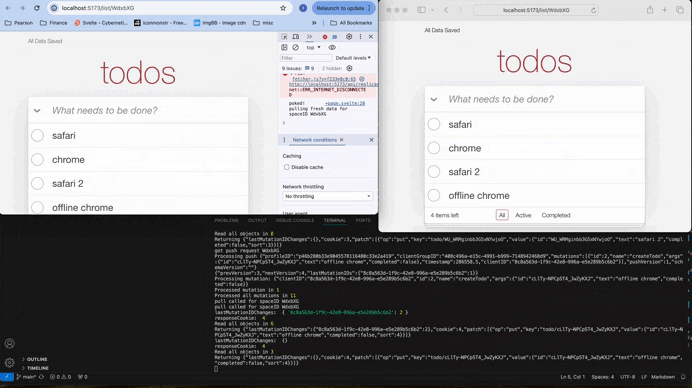
Look at the GIF below — it shows a real-time Todo-MVC demo, syncing across windows and smoothly transitioning in and out of offline mode. While it’s just a simple demo app, it showcases important, cutting-edge concepts that every web developer should know.
This is a Replicache demo app that I ported from an Express backend and web components frontend to SvelteKit to learn about the technology and concepts behind it. I want to share my learnings with you.
The source code is available on Github.

Context and motivation
Web applications face some fundamentally hard problems, problems most web frameworks seem to ignore. These problems are so hard that only very few apps actually solve them well, and those apps stand head and shoulders above other apps in their respective space.
Here are some such problems I had to deal with in actual commercial apps I worked on:
- Getting the app to feel snappy even when it talks to the server, even over slow or patchy network. This applies not only to the initial load time but also to interactions after the app has loaded. SPAs were an early and ultimately insufficient attempt at solving this.
- Implementing undo/ redo and version history for user generated content (e.g site building, e-commerce, online courses builder).
- Getting the app to work correctly when open simultaneously by the same user on multiple tabs/ devices.
- Handling long-lived sessions running an old version of the frontend, which users might not want to refresh to avoid losing work.
- Making collaboration features/multiplayer functionalities work correctly and near real-time, including conflict resolution.
I encountered these problems while working on totally normal web applications, nothing too crazy, and I believe most web apps will hit some or all of them as they gain traction.A pattern I noticed in dev teams that start working on a new product is to ignore these problems completely, even if the team is aware of them. The reasoning is usually along the lines of "we'll deal with it when we start actually having these problems." The team would then go on to pick some well-established frameworks (pick your favorite) thinking these tools surely offer solutions to any common problem that may arise. Months later, when the app hits ten thousand active users, reality sinks in: the team has to introduce partial, patchy solutions that add complexity and make the system even more sluggish and buggy, or rewrite core parts (which no one ever does right after launch). Ouch.I felt this pain. The pain is real.Enter "Sync Engine."
What the hell is a sync engine?
Remember I said that some apps address these issues much better than others? Recent famous examples are Linear and Figma. Both have disrupted incredibly competitive markets by being technologically superior. Other examples are Superhuman and a decade prior, Trello. When you look into what they did, you discover that they all converged on very similar patterns, and they all developed their respective implementations in-house. You can read about how they did it (highly recommended) in these links: Figma, Linear, Superhuman, Trello (series).
At the core of the system, there is always a sync engine that acts as a persistent buffer between the frontend and the backend. At a high level, this is how it works:
-
The client always reads from and writes to a local store that is provided by the engine. As far as the app code is concerned, it runs locally in memory.
-
That store is responsible for updating the state optimistically, persisting the data locally in the browser's storage, and syncing it back and forth with the backend, including dealing with potential complications and edge cases.
-
The backend implements the other half of the engine, to allow pulling and pushing data, notifying the clients when data has changed, persisting the data in a database, etc.
Different implementations of sync engines make different tradeoffs, but the basic idea is always the same.
Not a new idea but...
If you've been following trends in the web-dev world, you'd know that sync engines have been a centrepiece in several of them, namely: progressive web apps, offline-first apps, and the lately trending term: local-first software. You might have even looked into some of the databases that offer a built-in sync engine such as PouchDb or online services that do the same (e.g., Firestore). I have too, but my general feeling over the last few years has been that none of it is quite hitting the nail on the head. Progressive web apps were about users "installing" shortcuts to websites on their home screens as if they were native apps, despite not needing installation being maybe "the" benefit of the web. "Offline-first" made it sound like offline mode is more important than online, which for 99% of web apps is simply not the case. "Local-first" is admittedly the best name so far, but the official local-first manifesto talks about peer-to-peer communication and CRDTs (a super cool idea but one that is rarely used for anything besides collaborative text editing) in a world of full client-server web applications that are trying to solve practical problems like the ones I described above. Ironically, many tools that are part of the current "local-first" wave adopted the name without adopting all the principles.
The one that drew my attention and interest the most is called "Replicache." Specifically, I was intrigued by it exactly because it's NOT a self-replicating database or a black-box SaaS service that you have to build your entire app around. Instead, it offers much more control, flexibility, and separation of concerns than any off-the-shelf solution I have encountered in this space.
What is Replicache?
Replicache is a library. On the frontend, it requires very little wiring and effectively functions as a normal global store (think Zustand or a Svelte store). It has a chunk of state (in our example, each list has its own store). It can be mutated using a set of user-defined functions called "mutators" (think reducers) like "addItem", "deleteItem," or anything you want, and exposes a subscribe function (I am simplifying, full API here).
Behind this familiar interface lies a robust and performant client-side sync engine that handles:
-
Initial full download of the relevant data to the client.
-
Pulling and pushing "mutations" to and from the backend. A mutation is an event that specifies which mutator was applied, with which parameters (plus some metadata).
-
When pushing, these changes are applied optimistically on the client, and rolled back if they fail on the server. Any other pending changes would be applied on top (rebase).
-
The sync mechanism also includes queuing changes if the connection is lost, retry mechanisms, applying changes in the right order, and de-duping.
-
-
Caching everything in memory (performance) and persisting it to the browser storage (specifically IndexedDB) for backup.
-
Since the same storage is accessible from all the tabs of the same application, the engine deals with all the implications of that—like what to do when there was a schema change but some tabs have refreshed and some haven't and are still using the old schema.
-
Keeping all the tabs in sync instantly using a broadcast channel (since relying on the shared storage is not fast enough).
-
Dealing with cases in which the browser decides to wipe out the local storage.
You might have noticed that this right here addresses a big chunk of the problems I listed at the top of this post. Being mutations-based also lends itself to features like undo/redo.
In order for all of this to work, it's your backend's job to implement the protocol that Replicache defines. Specifically:
- You need to implement push and pull APIs. These endpoints need to be able to activate mutators similarly to the frontend (though they don't have to run the same logic). The backend is authoritative, and conflict resolution is done by your code within the mutator implementation.
- Your database needs to support snapshot isolation and run operations within transactions.
- The Replicache client polls the server periodically to check for changes, but if you want close to real-time sync between clients, you need to implement a "poke" mechanism, namely a way to notify the clients that something has changed and they need to pull now. This could be done via server-sent events or websockets. It's an interesting API design choice—changes are never pushed to the client; the client always pulls them. I believe it is done this way for simplicity and ease of reasoning about the system. One thing for sure: it's good that they didn't make websockets mandatory because that would have made the protocol incompatible with HTTP (server-sent events stream over a normal HTTP connection), which would have required extra infrastructure and presented additional integration challenges.
- Depending on the versioning strategy, you might need to implement additional operations (e.g., createSpace).
If it sounds non-trivial to you, you are right. I don't think I fully wrapped my head around all the details of how it operates with the database. I'll need to do a follow-up project in which I totally refactor the database structure and/or add meaningful features to the example (e.g., version history) in order to get closer to fully grokking it. The thing is, I know how valuable this level of control is when building and maintaining real production apps. In my book, spending a week or two thinking deeply about and setting up the core part of your application is a great investment if it creates a strong foundation to build and expand upon.
Porting a non-trivial example
The best (and arguably only) way to learn anything new is by getting your hands dirty—dirty enough to experience some of the tradeoffs and implications that would affect a real app. As I was going over the examples on the Replicache website, I noticed there were none for Sveltekit. I have been a huge Svelte fan since Svelte 3 was released, but only recently started playing with Sveltekit. I thought this would be an awesome opportunity to learn by doing and create a useful reference implementation at the same time.
Porting an existing codebase to a different technology is educational because, as you translate the code, you are forced to understand and question it. Throughout the process, I experienced multiple eureka moments as things that seemed odd at first clicked into place.
Learnings
Sveltekit
-
Sveltekit doesn't natively support WebSockets, and even though it does support server-sent events, it does so in a clumsy way. Express supports both nicely. As a result, I used svelte-sse for server-sent events. One somewhat annoying quirk I ran into is that since svelte-sse returns a Svelte store, which my app wasn't subscribing to (the app doesn't need to read the value, just to trigger a pull as I described above), the whole thing was just optimized away by the compiler. I was initially scratching my head about why messages were not coming through. I ended up having to implement a workaround for that behavior. I don't blame the author of the library; they assumed a meaningful value would be sent to the client, which is not the case with 'poke'.
-
SvelteKit's filesystem-based routing, load functions, layouts, and other features allowed for a better-organized codebase and less boilerplate code compared to the original Express backend. Needless to say, on the frontend, Svelte is miles ahead of web components, resulting in a frontend codebase that is smaller and more readable even though it has more functionality (the original example TodoMVC was missing features such as "mark all as complete" and "delete completed").
-
Overall, I love Sveltekit and plan to keep using it in the future. If you haven't tried it, the official tutorial is an awesome introduction.
Replicache
Overall, I am super impressed by Replicache and would recommend trying it out. At the basic level (which is all I got to try at this point), it works very well and delivers on all its promises. With that said, here are some general concerns (not todo app related) I have and thoughts related to them:
- Performance-related:
- Initial load time (first time, before any data was ever pulled to the client) might be long when there is a lot of data to download (think tens of MBs). Productivity apps in which the user spends a lot of time after the initial load are less sensitive to this, but it is still something to watch for. Potential mitigation: partial sync (e.g., Linear only sends open issues or ones that were closed over the last week instead of sending all issues).
- Chatty network (?) - Initially, it seemed to me that there was a lot of chatter going back and forth between the client and the server with all the push, pull, and poke calls flying around. On deeper inspection, I realized my intuition was wrong. There is frequent communication, yes, but since the mutations are very compact and the poke calls are tiny (no payload), it amounts to much less than your normal REST/GraphQL app. Also, a browser full reload (refresh button or opening the page again in a new tab/window after it was closed) loads most of the data from the browser's storage and only needs to pull the diffs from the server, which leads me to the next point.
- Coming back after a long period of time offline: I haven't tested this one, but it seems like a real concern. What happens if I was working offline for a few days making updates while my team was online and also making changes? When I come back online, I could have a huge amount of diffs to push and pull. Additionally, conflict resolution could become super difficult to get right. This is a problem for every collaborative app that has an offline mode and is not unique to Replicache. The Replicache docs warn about this situation and propose implementing "the concept of history" as a potential mitigation.
- What about bundle size? Replicache is 34kb gzipped, and for what you get in return, it's easily worth it.
- This page on the Replicache website makes me think that, in the general case, performance should be very good.
- Functionality-related:
- Unlike native mobile or desktop apps, it is possible for users to lose the local copy of their work because the browser's storage doesn't provide the same guarantees as the device's file system. Browsers can just decide to delete all the app's data under certain conditions. If the user has been online and has work that didn't have a chance to get pushed to the server, that work would be lost in such a case. Again, this problem is not unique to Replicache and affects all web apps that support offline mode, and based on what I read, it is unlikely to affect most users. It's just something to keep in mind.
- I was surprised to see that the schema in the backend database in the Todo example I ported doesn't have the "proper" relational definitions I would expect from a SQL database. There is no "items" table with fields for "id", "text", or "completed". The reason I would want that to exist is the same reason I want a relational database in the first place—to be able to easily slice and dice the data in my system (which I always missed down the line when I didn't have). I don't think it is a major concern since Replicache is supposed to be backend-agnostic as long as the protocol is implemented according to spec. I might try to refactor the database as a follow-up exercise to see what that means in terms of complexity and ergonomics.
- I find version history and undo/redo super useful and desirable in apps with user-editable content. With regards to undo/redo there is an official package but it seems to lack support for the multiplayer usecase (which is where the problems come from). As for version-history, the Replicache documentation mentions "the concept of history" but suggests talking to them if the need arises. That makes me think it might not be straightforward to achieve. Another idea for a follow-up task.
- Collaborative text editing - the existing conflict resolution approach won't work well for collaborative text editing, which requires CRDTs or OT. I wonder how easy it would be to integrate Replicache with something like Yjs. There is an official example repo, but I haven't looked into it yet.
- Scaling-related:
- Since the server is stateful (holds open HTTP connections for server-sent events), I wonder how well it would scale. I've worked on production systems with >100k users that used WebSockets before, so I know it is not that big of a deal, but still something to think about.
- Other:
-
- In theory, Replicache can be added into existing apps without rewriting the frontend (as long as the app already uses a similar store). The backend might be trickier. If your database doesn't support snapshot isolation, you are out of luck, and even if it does, the existing schema and your existing endpoints might need some serious rework. If you're going to use it, do it from day one (if you can).
-
Replicache is not open source (yet! see the point below) and is free only as long as you're small or non-commercial. Given the amount of work (>2 years) that went into developing it and the quality of engineering on display, it seems fair. With that said, it makes adopting Replicache more of a commitment compared to picking up a free, open library. If you are a tier 2 and up paying customer, you get a source license so that if Replicache shuts down for some reason, your app is safe. Another option is to roll out your own sync engine, like the big boys (Linear, Figma) have done, but getting to the quality and performance that Replicache offers would be anything but easy or quick.
-
Crazy plot twist (last minute edit): As I was about to publish this post I discovered that Replicache is going to be opened sourced in the near future and that its parent company is planning to launch a new sync-engine called "Zero". Here is the official announcement. It reads: "We will be open sourcing Replicache and Reflect. Once Zero is ready, we will encourage users to move." Ironically, Zero seems to be yet another solution that automagically syncs the backend database with the frontend database, which at least for me personally seems less attractive (because I want separation of concerns and control). With that said, these guys are experts in this domain and I am just a dude on the internet so we'll have to wait and see. In the meanwhile, I plan on playing with Replicache some more.
-
Should a sync engine be used for everything?
No, a sync engine shouldn't be used for everything. The good news is that you can have parts of your app using it while other parts still submit forms and wait for the server's response in the conventional manner. SvelteKit and other full-stack frameworks make this integration easy.Obvious situations where using a sync engine is a bad idea:
-
Optimistic updates make sense only when client changes are highly likely to succeed (with rollbacks being rare) and when the client possesses enough information to predict outcomes. For instance, in an online test where a student's answer must be sent to the server for grading, optimistic updates (and hence a sync engine) wouldn't be feasible. The same applies to critical actions such as placing orders or trading stocks. A good rule of thumb is that any action dependent on the server and incapable of functioning offline should not rely on a sync engine.
-
Any app dealing with huge datasets that cannot be fit on user machines. For example, creating a local-first version of Google or an analytics tool processing gigabytes of data to generate results is impractical. However, in scenarios where partial synchronisation suffices, a sync engine can still be beneficial. For instance, Google Maps can download and cache maps on client devices to operate offline, without needing high-resolution maps for every location worldwide all the time.
A word on developer productivity and DX
My impression is that having a sync engine can make DX (developer experience) much nicer. Frontend engineers just work with a normal store that they can subscribe to updates, and the UI always stays up to date. No need to think about fetching anything, calling APIs or server actions for the parts of the app that are governed by the sync engine. On the backend, I can't say much yet. It seems like it won't be harder than a traditional backend but I can't say for sure.
Closing thoughts
It's exciting to imagine the future of web apps as planet scale, real-time multi-player collaboration tools that work reliably regardless of network conditions, while at the same time making these nasty problems I started this post with a thing of the past.I highly recommend fellow web developers to get themselves familiar with these new concepts, experiment with them, and maybe even contribute. Thanks for reading. Leave a comment if you have any questions or thoughts. Peace..
P.S with Aaron Boodman, the founder of the company that created Replicache, is great. Watch it and thank me later.
如有侵权请联系:admin#unsafe.sh