
2024-8-15 08:0:20 Author: hackernoon.com(查看原文) 阅读量:3 收藏
Table of Links
3. Method and 3.1. Hybrid Guidance Strategy
3.2. Handling Multiple Identities
4. Experiments
Text-to-image diffusion models. Diffusion models have recently come to the forefront of generative model research. Their exceptional capability to generate high-quality and diverse images has placed them at a distinct advantage over their predecessors, namely the GAN-based and autoregressive image generation models. This new generation of diffusion models, having the capacity to produce stateof-the-art synthesis results, owes much of its success to being trained on image-text pairs data at a billion scale. The integration of textual prompts into the diffusion model serves as a vital ingredient in the development of various text-to-image diffusion models. Distinguished models in this domain include GLIDE [38], DALL·E 2 [41], Imagen [45], and StableDiffusion [42]. These models leverage text as guidance during the image generation process. Consequently, they have shown considerable proficiency in synthesizing high-quality images that closely align with the provided textual description. Compared to previous efforts [29, 39, 51, 69] on face image synthesis based on Generative Adversarial Networks (GANs) [25], diffusion models exhibit greater stability during training and demonstrate enhanced capability in effectively integrating diverse forms of guidance, such as texts and stylized images.
However, textual descriptions for guidance, while immensely useful, often fall short when it comes to the generation of complex and nuanced details that are frequently associated with certain subjects. For instance, generating images of human faces proves challenging with this approach. While generating images of celebrities might be feasible due to the substantial presence of their photographs in the training data that can be linked to their names, it becomes an uphill task when it comes to generating images of ordinary people using these text-to-diffusion models.
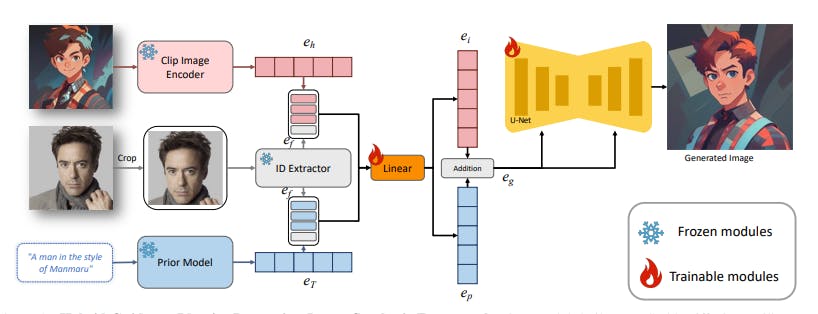
Subject-driven image generation. Subject-driven image generation seeks to overcome the limitations posed by text-to-image synthesis models. Central to this novel research area is the inclusion of subject-specific reference images, which supplement the textual description to yield more precise and personalized image synthesis. To this end, several optimization-based methods have been employed, with popular ones being Low-Rank Adaptation (LoRA), DreamBooth [43], Textual Inversion [14], and Hypernetwork [3]. These methods typically involve fine-tuning a pre-trained text-to-image framework or textual embeddings to align the existing model with user-defined concepts, as indicated by a set of example images. There are several other methods derived from these works such as Unitune [49], HyperDreamBooth [44], EasyPhoto [53], FaceChain [33], etc. [4, 23, 60]. However, these methods pose some challenges. For one, they are time-consuming due to the need for model fine-tuning, which also requires multiple reference images to achieve accurate fitting. Overfitting also becomes a potential issue with these optimization-based methods, given their heavy reliance on example images. In response to these challenges, recent studies have proposed various improved methods. DreamArtist [13], for instance, mitigates the problem of overfitting by incorporating both positive and negative embeddings and jointly training them. Similarly, E4T [15] introduced an encoder-based domain-tuning method to accelerate the personalization of text-to-image models, offering a faster solution to model fitting for new subjects. There are large numbers of similar methods which are encoder-based including Composer [21], ProFusion [68] MagiCapture [22], IP-Adapter [59], ELITE [52], DisenBooth [8], Face0 [50], PhotoVerse [9], AnyDoor [11], SingleInsert [54], etc. [24, 35, 56].
Alongside optimization-based methods, a number of tuning-free methods have been concurrently proposed, such as InstantBooth [47]. This method converts input images into a textual token for general concept learning and introduces adapter layers to obtain rich image representation for generating fine-grained identity details. However, it comes with the drawback of having to train the model separately for each category. Bansal et al.[6] put forward a universal guidance algorithm that enables diffusion models to be controlled by arbitrary guidance modalities without the need to retrain the network. Similarly, Yang et al.[57] propose an inpainting-like diffusion model that learns to inpaint a masked image under the guidance of example images of a given subject. Similar methods leveraged by inversion-based personalization including Cao et al. [7], Han et al. [17], Gu et al. [16], Mokady et al. [37]. Besides, Controlnet [67] is also an effective way to personalize. In addition, there are some solutions that use editing to achieve the purpose of maintaining identity, such as SDEdit [36], Imagic [26], etc. [18, 48]. Based on all the solutions mentioned above, the method of combining multiple objects while maintaining identity is also widely used in Break-a-scene [5], FastComposer [55], Cones [34] and MultiConceptCustomDiffusion [27].
Within the text-to-image community, one specific area of interest that has garnered significant attention is the generation of human images. Human-centric image generation, owing to its vast applicability and widespread popularity, constitutes a substantial proportion of posts in the community, such as Civitai [1]. In light of these considerations, our work primarily focuses on the preservation of human identity during the image generation process.

Few-shot Learning. It is a common practice in the field of few-shot learning literature to convert optimizationbased tasks into a feed-forward approach, which can significantly reduce computation time. Numerous previous studies in the realm of few-shot learning have adopted this approach to address computer vision tasks, including but not limited to classification [63–66], detection [58], and segmentation [10, 28, 30–32, 61, 62]. In this research, our objective aligns with this approach as we aim to integrate identity information into the generative process through a feed-forward module.
如有侵权请联系:admin#unsafe.sh