2024-8-16 17:6:9 Author: mp.weixin.qq.com(查看原文) 阅读量:15 收藏
论文题目:TrafficGPT: Breaking the Token Barrier for Efficient Long Traffic Analysis and Generation
论文作者:Jian Qu, Xiaobo Ma, Jianfeng Li
发表会议/期刊:arXiv https://arxiv.org/pdf/2403.05822
发布时间:2024
主题类型:流量分析
笔记作者:young_fan
研究概述
预训练模型作为近年来主流的流量识别技术,存在能够通过大型未标记的数据集中学习稳定的数据,以此提高表示性能的优点。但是现有的预训练模型存在着诸如token长度限制等问题,这限制了它在现实中进行流量分析的实用性。在此背景下,本文设计了一种名为TrafficGPT的预训练深度学习模型,主要结构由Token化、预训练、微调三部分组成。该模型可以解决更长的流量分类问题,同时可以完成流量生成任务。
下图为本文提出的TrafficGPT模型的框架图,包含Token化、预训练、微调三部分。具体的,Token化部分将pcap文件分割为不同的流,将每个包进行标记,从而完成对整个流的标记。预训练部分中,模型使用先前生成的内容作为上文,从而生成后续词汇表示token,在训练过程中,自回归预训练采用交叉熵损失。需要注意的是,此处模型采用了作者所提出的线性注意力机制结合局部注意力策略,大大下降计算复杂度的同时保留了局部重要信息的捕捉能力,同时引入了令牌偏移来提高训练效率。在微调过程中,在流的token头部增加一个[cls]token,即表示模型即将承担分类任务,随后将[cls]与流token都输入到模型中。
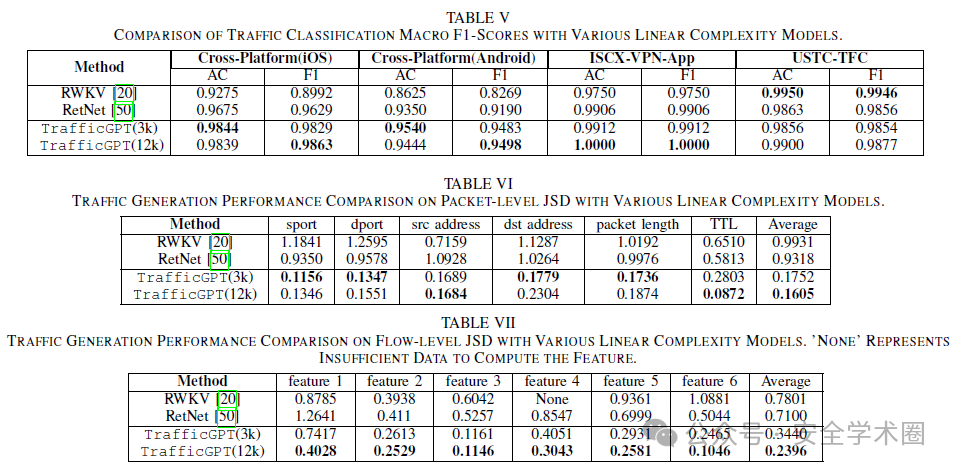
实验共分为两个部分,分类实验和生成实验。首先,文章在五个数据集(ISCX-Tor2016、USTCTFC2016、ISCXVPN2016、DoHBrw2020和CICIoT2022)上做了流量分类实验,并比较了不同Token长度下的分类性能。
流量生成实验选择了JS散度作为评价标准。
同时,对比了其他两种线性复杂度的模型在包和流的两个维度的性能。
贡献分析
贡献点1:论文针对传统Transformer中传统的自注意机制,提出了一种线性的注意机制,实现了将原有模型处理token列表的范围从512扩大到12032的同时提高了效率; 贡献点2:论文针对传统预训练模型使用的tokenToken化方法很难从模型生成的标记列表中准确重建pcap文件问题,提出了一种可逆的token标记方法,实现了模型在模拟真实的网络流量时的可靠性。
论文点评
本文所提出的模型在流量分类和流量生成方面均有优秀的表现,但是根据其内容中所述,还存在着以下问题:
模型在预训练过程中缺乏对概念任务的考虑可能会引入概念差距。作者提出可以采用多任务训练策略,从而对这一限制进行缓解并提高分类结果。比如在训练过程中结合分类学习和自动回归学习; 模型在标签化的时候将一个pcap文件分解为多个流分别进行标签化,而忽略了流之间的关系。加入流之间的关系也许可以提高综合表现; 关于本文使用的数据集,其中的数据主要由TCP/IP数据构成,并没有包含蓝牙、Zigbee等协议,使得模型支持的数据包并不全面,影响了模型的通用性与适用性。此处的改进方向应该从数据集处入手,增加含有其他协议的数据集。
除了本文作者提出的以上问题之外,本人在阅读时还考虑了以下问题:
传统的transformer的自注意机制已经被证明了其时间复杂度在输入长度上是二次的。而本文提出的线性注意机制是传统的自注意机制的近似算法,这种近似算法的拟合效果对实验会产生什么样的影响,文章中并没有提及。也就是说,牺牲算法多少的正确性换来的时间优化作者并没有在文中说明; 文章中提出的针对包的标签化方式中有一种token是十六进制token,根据作者在文章中的表示,这个token仅仅是报文内容的16进制表示。如果遇到较长的报文内容可能会对模型的时间复杂度产生影响。
论文文献
[1]. Qu J, Ma X, Li J. Trafficgpt: Breaking the token barrier for efficient long traffic analysis and generation[J]. arXiv preprint arXiv:2403.05822, 2024.
研究团队:马小博,教授/博导. 国家级青年人才. 陕西省杰出青年基金获得者. 仲英青年学者/思源学者. CCF YOCSEF西安主席. CCF高级会员/IEEE会员。长期致力于僵尸网络检测、加密流量分析、区块链安全研究。近5年,主持网络安全相关国家级项目8项,在USENIX Security、NDSS、IEEE/ACM TON、IEEE TDSC、INFOCOM等期刊会议发表论文30多篇,出版英文专著章节2部,授权及申请国家/国防发明专利近40项,成果在国家某工程、慧眼行动、国家重点研发计划“网络空间安全重点专项”应用示范类项目等取得重要应用。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh