
2024-8-19 08:0:0 Author: arthurchiao.github.io(查看原文) 阅读量:6 收藏
Published at 2024-08-19 | Last Update 2024-08-19
记录一些平时接触到的 GPU 知识。由于是笔记而非教程,因此内容不求连贯,有基础的同学可作查漏补缺之用。
- GPU 进阶笔记(一):高性能 GPU 服务器硬件拓扑与集群组网(2023)
- GPU 进阶笔记(二):华为昇腾 910B GPU 相关(2023)
- GPU 进阶笔记(三):华为 NPU (GPU) 演进(2024)
- GPU 进阶笔记(四):NVIDIA GH200 芯片、服务器及集群组网(2024)
水平及维护精力所限,文中不免存在错误或过时之处,请酌情参考。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
- 1 传统原厂 GPU 服务器:
Intel/AMD x86 CPU+NVIDIA GPU - 2 新一代原厂 GPU 服务器:
NVIDIA CPU+NVIDIA GPU - 3 GH200 服务器内部设计
- 4 GH200 服务器及组网
- 5 总结
- 参考资料
2024 之前,不管是 NVIDIA 原厂还是第三方服务器厂商的 NVIDIA GPU 机器,都是以 x86 CPU 机器为底座, GPU 以 PCIe 板卡或 8 卡模组的方式连接到主板上,我们在第一篇中有过详细介绍,
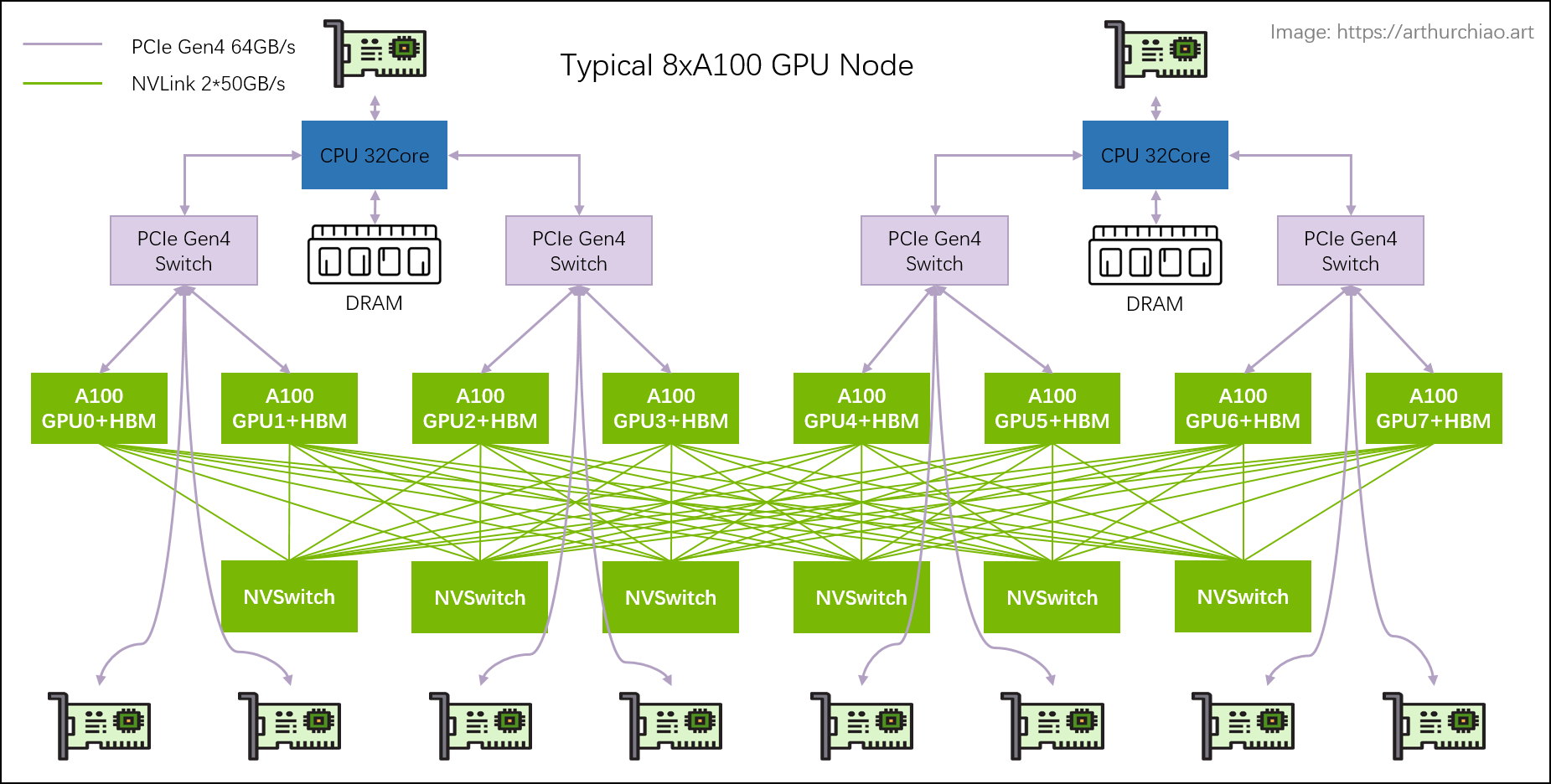
典型 8 卡 A100 主机硬件拓扑
这时 CPU 和 GPU 是独立的,服务器厂商只要买 GPU 模组(例如 8*A100),都可以自己组装服务器。 至于 Intel/AMD CPU 用哪家,就看性能、成本或性价比考虑了。
随着 2024 年 NVIDIA GH200 芯片的问世,NVIDIA 的 GPU 开始自带 CPU 了。
- 桌面计算机时代:CPU 为主,GPU(显卡)为辅,CPU 芯片中可以集成一块 GPU 芯片, 叫集成显卡;
- AI 数据中心时代:GPU 反客为主,CPU 退居次席,GPU 芯片/板卡中集成 CPU。
所以 NVIDIA 集成度越来越高,开始提供整机或整机柜。
2.1 CPU 芯片:Grace (ARM)
基于 ARMv9 设计。
2.2 GPU 芯片:Hopper/Blackwell/…
比如 Hopper 系列,先出的 H100-80GB,后面继续迭代:
H800:H100 的阉割版,- H200:H100 的升级版,
H20:H200 的阉割版,比 H800 还差,差多了。
算力对比:GPU Performance (Data Sheets) Quick Reference (2023)
2.3 芯片产品(命名)举例
2.3.1 Grace CPU + Hopper 200 (H200) GPU:GH200
一张板子:

NVIDIA GH200 芯片(板卡)渲染图。左:Grace CPU 芯片;右:Hopper GPU 芯片 [2]
2.3.2 Grace CPU + Blackwell 200 (B200) GPU:GB200
一个板子(模块),功耗太大,自带液冷:

NVIDIA GB200 渲染图,一个模块包括 2 Grace CPU + 4 B200 GPU,另外自带了液冷模块。 [3]
72 张 B200 组成一个原厂机柜 NVL72:

NVIDIA GB200 NVL72 机柜。 [3]
3.1 GH200 芯片逻辑图:CPU+GPU+RAM+VRAM 集成到单颗芯片

NVIDIA GH200 芯片(单颗)逻辑图。[2]
3.1.1 核心硬件
如上图所示,一颗 GH200 超级芯片集成了下面这些核心部件:
- 一颗 NVIDIA Grace CPU;
- 一颗 NVIDIA H200 GPU;
- 最多 480GB CPU 内存;
- 96GB 或 144GB GPU 显存。
3.1.2 芯片硬件互连
-
CPU 通过 4 个 PCIe Gen5 x16 连接到主板,
- 单个 PCIe Gen5 x16 的速度是双向 128GB/s,
- 所以 4 个的总速度是 512GB/s;
-
CPU 和 GPU 之间,通过 NVLink® Chip-2-Chip (
NVLink-C2C) 技术互连,- 900 GB/s,比 PCIe Gen5 x16 的速度快 7 倍;
-
GPU 互连(同主机扩跨主机):18x NVLINK4
- 900 GB/s
NVLink-C2C 提供了一种 NVIDIA 所谓的“memory coherency”:内存/显存一致性。好处:
- 内存+显存高达 624GB,对用户来说是统一的,可以不区分的使用;提升开发者效率;
- CPU 和 GPU 可以同时(concurrently and transparently)访问 CPU 和 GPU 内存。
- GPU 显存可以超分(oversubscribe),不够了就用 CPU 的内存,互连带宽够大,延迟很低。
下面再展开看看 CPU、内存、GPU 等等硬件。
3.2 CPU 和内存
3.2.1 72-core ARMv9 CPU
72-coreGrace CPU (Neoverse V2 Armv9 core)
3.2.2 480GB LPDDR5X (Low-Power DDR) 内存
- 最大支持 480GB LPDDR5X 内存;
- 500GB/s per-CPU memory bandwidth。
参考下这个速度在存储领域的位置:

Fig. Peak bandwidth of storage media, networking, and distributed storage solutions. [1]
3.2.3 三种内存对比:DDR vs. LPDDR vs. HBM
- 普通服务器(绝大部分服务器)用的是
DDR内存,通过主板上的 DIMM 插槽连接到 CPU,[1] 中有详细介绍; - 1-4 代的 LPDDR 是对应的 1-4 代 DDR 的低功耗版,常用于手机等设备。
- LPDDR5 是独立于 DDR5 设计的,甚至比 DDR5 投产还早;
- 直接和 CPU 焊到一起的,不可插拔,不可扩展,成本更高,但好处是速度更快;
- 还有个类似的是 GDDR,例如 RTX 4090 用的 GDDR。
- HBM 在第一篇中已经介绍过了;
下面列个表格对比三种内存的优缺点,注意其中的高/中/低都是三者相对而言的:
| DDR | LPDDR | HBM | |
|---|---|---|---|
| 容量 | 大 | 中 | 小 |
| 速度 | 慢 | 中 | 快 |
| 带宽 | 低 | 中 | 高 |
| 可扩展性 | 好 | 差 | 差 |
| 可插拔 | 可 | 不可 | 不可 |
| 成本 | 低 | 中 | 高 |
| 功耗 | 高 | 中 | 低 |
更多细节,见 [1]。
例如,与 8-channel DDR5(目前高端 x86 服务器的配置)相比,
GH200 的 LPDDR5X 内存带宽高 53%,功耗还低 1/8。
3.3 GPU 和显存
3.3.1 H200 GPU
算力见下面。
3.3.2 显存选配
支持两种显存,二选一:
- 96GB HBM3
- 144GB HBM3e,4.9TB/s,比 H100 SXM 的带宽高 50%;
3.4 变种:GH200 NVL2,用 NVLINK 全连接两颗 GH200
在一张板子内放两颗 GH200 芯片,CPU/GPU/RAM/VRAM 等等都翻倍,而且两颗芯片之间是全连接。
例如,对于一台能插 8 张板卡的服务器,
- 用 GH200 芯片:CPU 和 GPU 数量
8 * {72 Grace CPU, 1 H200 GPU} - 用 GH200 NVL2 变种:CPU 和 GPU 数量
8 * {144 Grace CPU, 2 H200 GPU}
3.5 GH200 & GH200 NVL2 产品参数(算力)

NVIDIA GH200 产品参数。上半部分是 CPU、内存等参数,从 "FP64" 往下是 GPU 参数。[2]
两种服务器规格,分别对应 PCIe 板卡和 NVLINK 板卡。
4.1 NVIDIA MGX with GH200:原厂主机及组网
下图是单卡 node 的一种组网方式:

NVIDIA GH200 MGX 服务器组网。每台 node 只有一片 GH200 芯片,作为 PCIe 板卡,没有 NVLINK。[2]
- 每台 node 只有一片 GH200 芯片(所以只有一个 GPU),作为 PCIe 板卡,没有 NVLINK;
- 每台 node 的网卡或加速卡 BlueField-3 (BF3) DPUs 连接到交换机;
- 跨 node 的 GPU 之间没有直连,而是通过主机网络(走
GPU->CPU-->NIC出去)的方式实现通信; - 适合 HPC workload、中小规模的 AI workload。
4.2 NVIDIA GH200 NVL32:原厂 32 卡机柜
通过 NVLINk 将 32 个 GH200 芯片全连接为一个逻辑 GPU 模块,所以叫 NVL32,

NVIDIA GH200 NVL32 组网。[2]
- NVL32 模块实际形态是一个机柜;
- 一个机柜能提供
19.5TB内存+显存; -
NVLink TLB 能让任意一个 GPU 访问这个机柜内的任意内存/显存;

NVIDIA GH200 NVL32 中 3 种内存/显存访问方式。[2]
- Extended GPU Memory (EGM)
- 一个机柜能提供
- 多个机柜再通过网络互连,形成集群,适合超大规模 AI workload。
本文粗浅地整理了一些 NVIDIA GH200 相关技术知识。
其他:
- Practical Storage Hierarchy and Performance: From HDDs to On-chip Caches(2024)
- NVIDIA GH200 Grace Hopper Superchip & Architecture, datasheet, 2024
- NVIDIA GB200 NVL72 Delivers Trillion-Parameter LLM Training and Real-Time Inference, 2024
![]()
![]()
如有侵权请联系:admin#unsafe.sh