
2024-8-20 22:46:44 Author: securityboulevard.com(查看原文) 阅读量:6 收藏
This is the second post in a series on Identity-Driven Offensive Tradecraft, which is also the focus of the new course we will launch in October. In the previous post, I asked, “How does one discover and abuse new attack paths?” To start answering this question, I made two key arguments:
- Every Attack Path is identity-driven, meaning that it is motivated by, centered around, and strategically guided by the abuse of identity and access management (IAM)
- Every attack path must contain at least one attack vector that abuses a violation of the Clean Source Principle, which dictates that all security dependencies must be as trustworthy as the object being secured.
To level set, an attack path can be defined as a chain of control relationships with at least one violation of the Clean Source Principle
In this post, I will share a framework I developed for discovering known and unknown attack paths.
Does Clean Source Violation Necessarily Introduce an Attack Vector?
We’ve already established that attack paths are a chain of control relationships with at least one Clean Source Principle violation, but is the opposite also true? Does every Clean Source violation necessarily create an attack path? Logic suggests the answer is “no”, but let’s see why.
The reason lies in the “control” definition. In our context, we define “control” as a relationship that can contribute to compromising the target resource or impacting its operability. I previously explained that I chose the words “contribute to compromising or impacting” rather than “compromise or impact” because we sometimes need to abuse more than one security dependency to fully compromise or impact the target. For example, if multi-factor authentication (MFA) is enforced on an account, we must abuse both authentication factors to gain control.

Therefore, the conclusion was that a set of one or multiple security dependencies can control a resource that depends on it. I’ll note that not every control prerequisite is necessarily a security dependency. For example, you need to establish a connection to a remote host/service to control it, but a network connection is not a security dependency and shouldn’t be a security boundary, at least not in $CurrentYear.

Attack Path Criteria
Two criteria determine whether a set of security dependencies violating the Clean Source Principle introduce an attack path:
- We know how to weaponize the security dependency set to control the dependent resource (or, in other words, we have an attack primitive for abusing it)
- We know that the security dependency set is present in the environment, and the target resource depends on it. To clarify this point, we may learn how to abuse a piece of technology to gain control of resources; however, it does not introduce an attack path if the technology is not used in the environment or the target resources don’t depend on it directly or transitively
I’m not adding the Clean Source violation as a criterion because it is implied and I’ll address it later.
Both criteria are binary, so we can represent security dependencies in a 2×2 matrix:
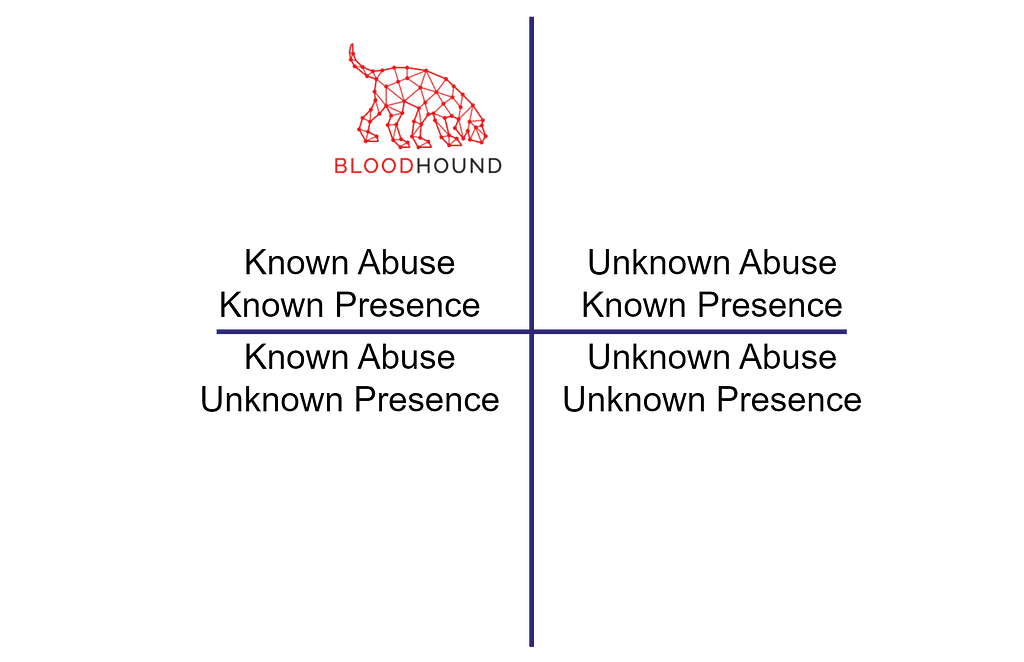
The top left quadrant is where we want to be: both criteria are met, so any Clean Source violation we identify is abusable. Paths BloodHound finds are in that quadrant — that’s the easy part. The challenge is bringing everything else into that quadrant. How do we achieve that?
Attack Path Discovery Framework

Define Target
There are generally two approaches for discovering attack paths:
- Analyzing outbound control — This approach seeks to understand the attacker’s reach given an initial position. I would describe it as exploratory or opportunistic
- Analyzing inbound control — This approach seeks to understand the ways to reach a specific resource, backtracking from a given target. I would describe this approach as intentional or objective-oriented
The latter is more suitable for this framework but requires a well-defined target or targets. As attackers, we would derive that from our red team objectives. The former can also serve a purpose, especially earlier on, for gaining situational awareness.
Map Security Dependencies
Performing reconnaissance, enumeration, and discovery helps discover what is present in an environment and identify the target’s direct and transitive security dependencies. This activity represents an upward shift from the bottom quadrants to the top quadrants.
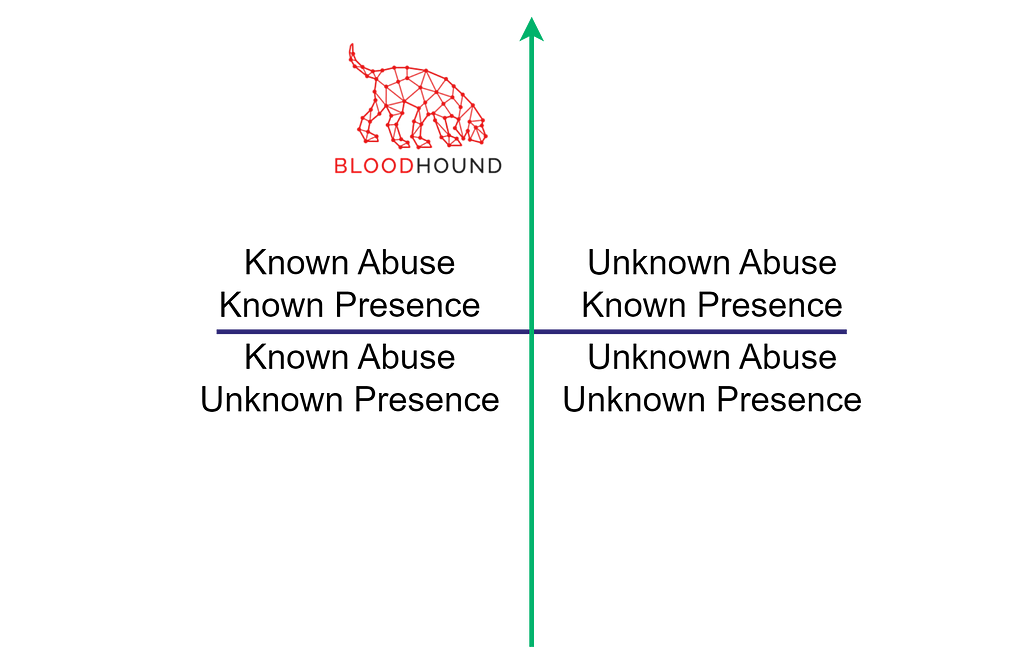
The bottom left quadrant represents known tradecraft, which is typically easier to discover. For example, we can run SharpHound and AzureHound to collect and ingest data into BloodHound. BloodHound can’t provide complete coverage of all known offensive tradecraft, so other enumeration tools and discovery techniques must be utilized.
The bottom right quadrant represents unknown tradecraft. It could be commodity, off-the-shelf technologies that we, as operators or as a community, don’t know how to abuse. It could also be proprietary/bespoke technologies for the target organization. Discovering those can be more challenging, as it requires more manual research and reconnaissance, which could involve scouring internal documentation and analyzing artifacts. Moving from the bottom right quadrant to the top right quadrant is essentially learning how things work, which is what hacking used to be all about.
Relying solely on existing tooling would completely ignore the bottom right quadrant and likely guarantee missing attack paths. Custom-built solutions and less commonly used technologies are typically more prone to vulnerabilities. Also, even if the target organization uses only stock technologies, we still need to learn how they are used to map their security dependencies. Remember that security dependencies are found not only in technology but also in people and processes, and those are almost always unique to the target organization.
Weaponize for Control
The second criterion is knowing how to abuse the security dependencies to gain control of the dependent resource. Learning or developing the required attack primitives represents a leftward shift from the right quadrants to the left quadrants.
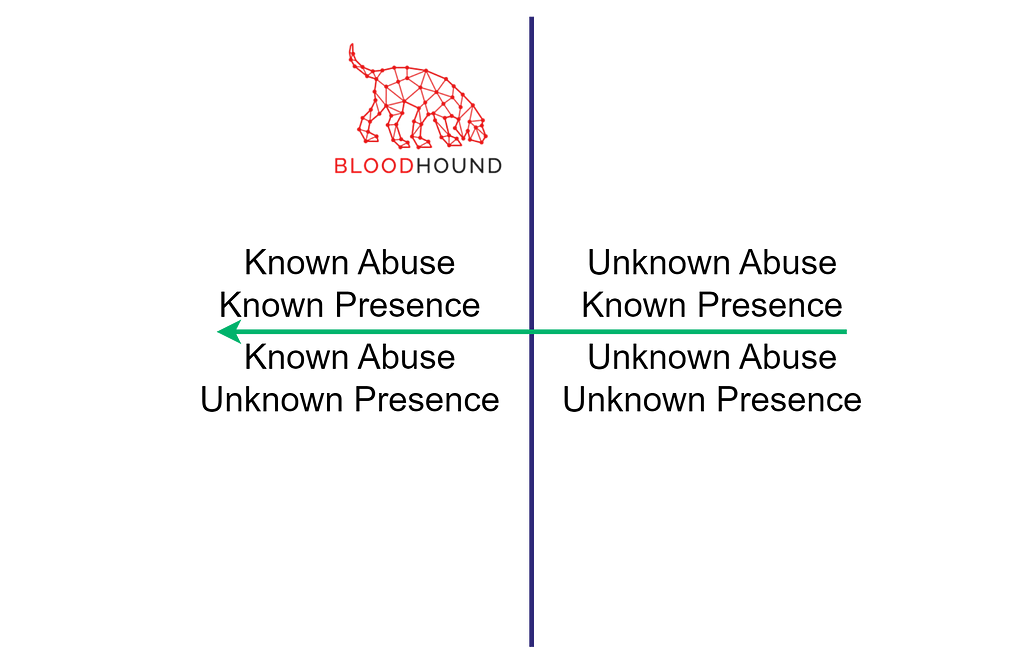
When targeting commodity, off-the-shelf technology, if new attack primitives are required, it is achieved through security research and tradecraft development. However, there is a plethora of known attacks against stock technologies and because the criterion is “knowing” how to abuse security dependencies to gain control, it can also be achieved through learning (did I mention we are launching a new course about identity-driven offensive tradecraft?). The bottom right quadrant represents such activities because we learn and develop tradecraft while not knowing if it is present in the target environment.
When targeting internally developed solutions, security assessments, red team operations, and penetration testing help discover attack primitives for abusing the technology and, as I mentioned, the people and processes. The top right quadrant represents this activity because we know the people, processes, and technology are present in the target environment, and we develop the required attack primitives with a specific target in sight.
Identify Clean Source Violations
Now that we have a clear view of the target’s security dependencies and know how to abuse them to gain control, we need to identify Clean Source violations. Remember, security dependencies always exist, but without a Clean Source violation, they are not an attack path. There is nothing wrong with Domain Admins having admin access to a domain controller (DC); that is expected behavior.

We’re looking for a security dependency that is less trustworthy than the dependent resource, so the obvious next step is to assign a trustworthiness level to every node. We’ll keep it simple by using only three levels:
- More trustworthy than the target, marked in green
- Less trustworthy than the target, marked in red
- Same as the target, marked in purple
Let’s consider the following scenario:
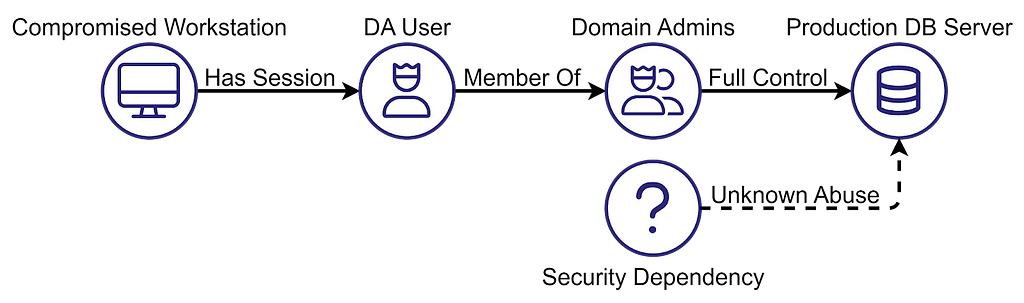
The Production DB Server is the target. It has two security dependencies: the Domain Admins group and another dependency that we don’t know how to abuse. Because we don’t know how to abuse it, it does not meet the attack path criteria, so we can disregard it. The DA User is a member of the Domain Admins group and has a session on a compromised workstation.
Now, we can assign trustworthiness levels to the dependencies. The trustworthiness should be assigned based on the security controls enforced on the dependency. Domain Admins are more trustworthy than the target and can be marked green. In line with the Clean Source Principle, security best practices dictate that Domain Admins must use Privileged Access Workstations (PAW) because normal workstations lack the security controls required to protect privileged accounts. Therefore, the Compromised Workstation can be marked red.
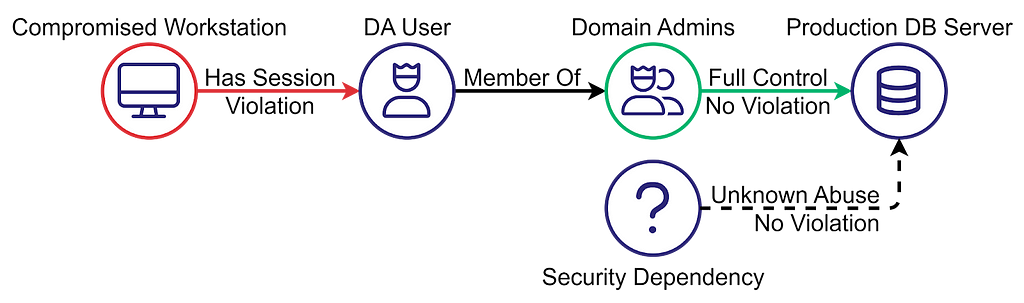
What about the DA User? You could argue that it is missing a security control preventing it from establishing a session on a less trustworthy workstation, and therefore it is less trustworthy than the Domain Admins group. Members of the Domain Admins group should log into Privileged Access Workstations (PAW) only. It could also be that, despite that, the DA User is still more trustworthy than the target. Regardless, the Compromised Workstation is less trustworthy, and it is sufficient for introducing an attack path.
Conclusion
Attack paths must include at least one clean source violation that we know how to abuse. Discovering attack paths requires acquiring capabilities to identify and abuse security dependencies to gain control of the dependent resources. Ultimately, assigning trustworthiness levels relative to a well-defined target allows for pinpointing Clean Source violations and identifying attack paths.
In the next post, we will apply this framework to a broadly used technology to demonstrate it.
Navigating the Uncharted: A Framework for Attack Path Discovery was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.
*** This is a Security Bloggers Network syndicated blog from Posts By SpecterOps Team Members - Medium authored by Elad Shamir. Read the original post at: https://posts.specterops.io/navigating-the-uncharted-a-framework-for-attack-path-discovery-c5a0a020a144?source=rss----f05f8696e3cc---4
如有侵权请联系:admin#unsafe.sh