
本文最初发表于 https://vutr.substack.com。
介绍
如果你用过 Notion,你就会知道它几乎可以让你做任何事情–记笔记、计划、阅读清单和项目管理。
Notion 非常灵活,可以定制用户喜欢的模板。Notion 中的一切都是块,包括文本、图像、列表、数据库行甚至页面。
这些动态单元可以转换成其他块类型,也可以在 Notion 中自由移动。
Blocks are Notion’s LEGOs.
PG 统治一切
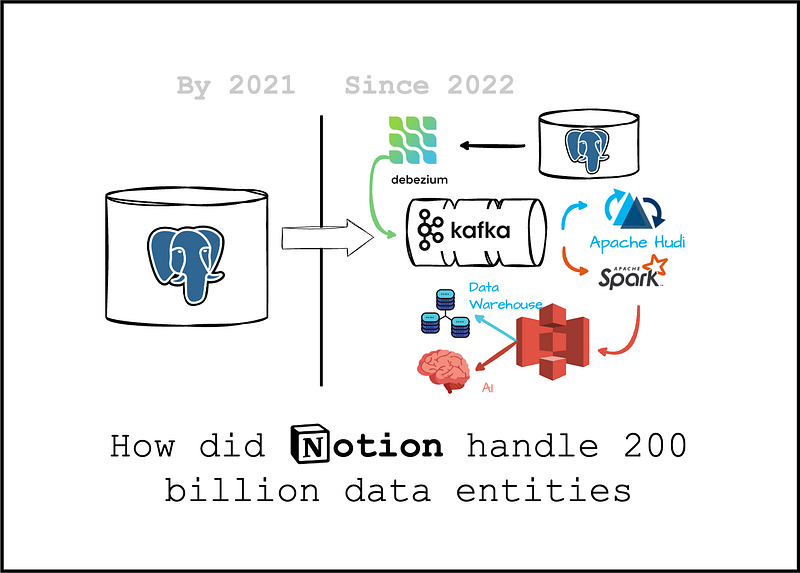
最初,Notion 将所有数据块存储在 Postgres 数据库中。
2021 年,他们拥有超过 200 亿个区块。
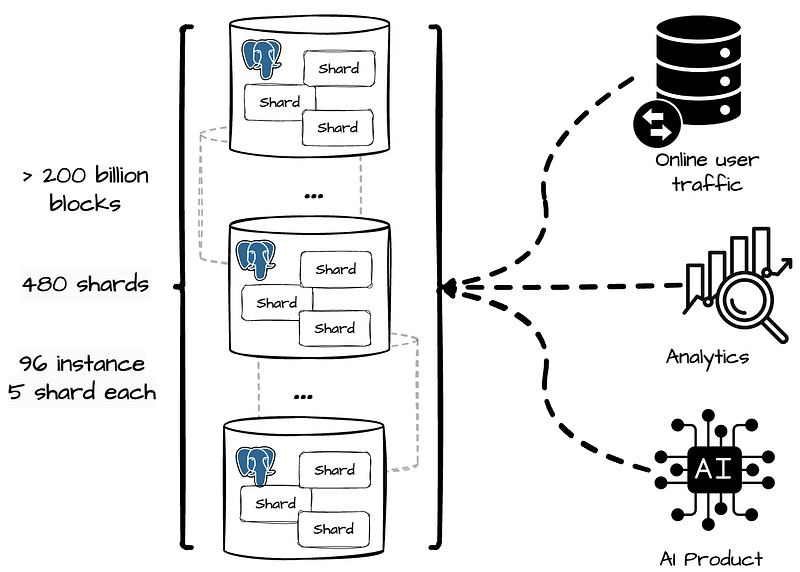
现在,这些区块已经增长到两千多亿个实体,2021 年之前,他们将所有区块都放在一个 Postgres 实例中。
现在,他们将数据库分割成 480 个逻辑分片,并将它们分布在 96 个 Postgres 实例上,每个实例负责 5 个分片。
在 Notion,Postgres 数据库负责处理从在线用户流量到离线分析和机器学习的所有事务。
认识到分析用例的爆炸性需求,特别是他们最近推出的 Notion AI 功能,他们决定为离线工作负载建立一个专用的基础架构。
Fivetrans 和 Snowflake
2021 年,他们开始了简单的 ETL 之旅,使用 Fivetran 将数据从 Postgres 采集到 Snowflake,每小时使用 480 个连接器将 480 个分片写入原始的 Snowflake 表。
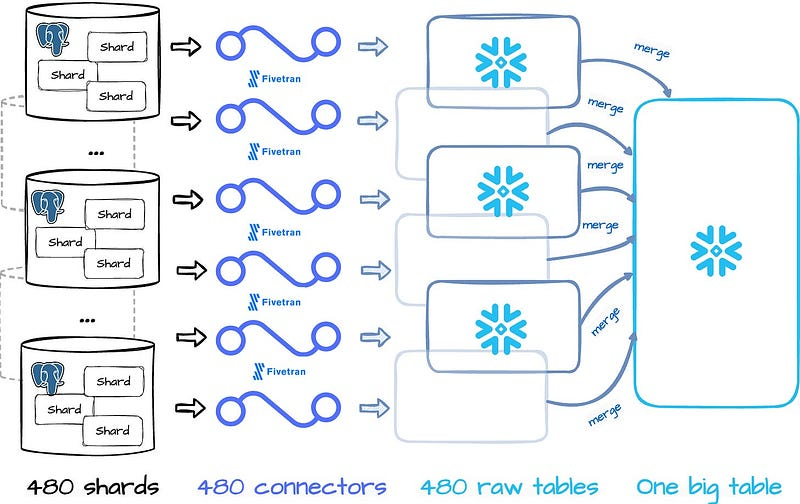
然后,Notion 会将这些表合并成一个大表,用于分析和机器学习工作负载。
但当 Postgres 数据增长时,这种方法就会出现一些问题:
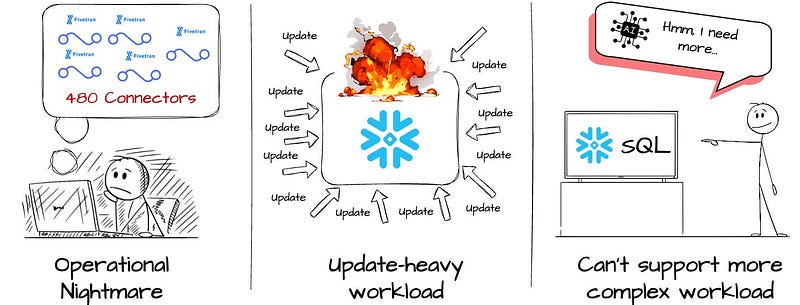
管理 480 个 Fivetran 连接器简直就是一场噩梦。
- Notions 用户更新数据块的频率高于添加新数据块的频率。这种大量更新的模式会降低 Snowflake 数据摄取的速度和成本。
- 数据消耗变得更加复杂和繁重(人工智能工作负载)
Notion 开始建设内部数据湖。
The Lake
他们希望建立一个能提供以下功能的解决方案:
- 可扩展的数据存储库,用于存储原始数据和处理过的数据。
- 为任何工作负载提供快速、经济高效的数据摄取和计算。特别是对于更新量大的块数据。
2022 年,他们启用了内部数据湖架构,该架构使用 Debezium 将数据从 Postgres 增量摄取到 Kafka,然后使用 Apache Hudi 将数据从 Kafka 写入 S3。
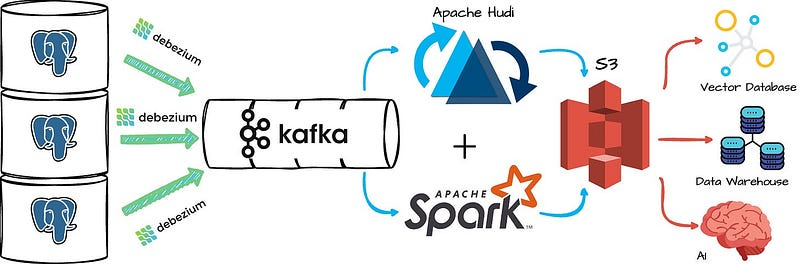
对象存储将作为消费系统的终端,为分析、报告需求和人工智能工作负载提供服务。
他们使用 Spark 作为主要数据处理引擎,处理湖泊顶部的数十亿个数据块。
从 Snowflake 迁移的数据摄取和计算工作负载可帮助他们大幅降低成本。
Postgres 的变化由 Kafka Debezium Connector 捕捉,然后通过 Apache Hudi 写入 S3。
Notion 之所以选择这种表格格式,是因为它能很好地应对更新繁重的工作负载,并能与 Debezium CDC 报文进行本地集成。
下面简要介绍一下他们是如何实现该解决方案的:
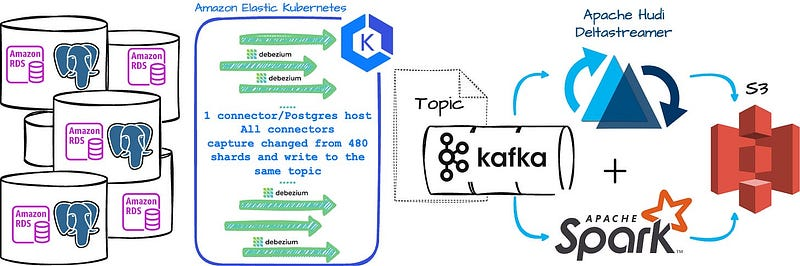
每台 Postgres 主机一个 Debeizum CDC 连接器。
- Notion 在托管的 AWS Kubernetes (EKS) 上部署了这些连接器
- 该连接器可处理每秒数十 MB 的 Postgres 行更改。
- 每个 Postgres 表有一个 Kafka 主题。
- 所有连接器都将从所有 480 个分片中消耗数据,并将数据写入该表的同一主题。
- 他们使用 Apache Hudi Deltastreamer(一种基于 Spark 的摄取作业)来读取 Kafka 消息并将数据写入 S3。
- 大多数数据处理工作都是用 PySpark 编写的。
- 他们使用 Scala Spark 处理更复杂的工作。Notion 还利用多线程和并行处理来加快 480 个分片的处理速度。
回报
- 2022 年,将数据从 Snowflake 迁移到 S3 为 Notion 节省了 100 多万美元,2023 年和 2024 年节省的费用将更为可观。
- 从 Postgres 到 S3 和 Snowflake 的总体摄取时间大幅缩短,小表的摄取时间从一天以上缩短到几分钟,大表的摄取时间则缩短到几个小时。
- 新的数据基础设施可提供更先进的分析用例和产品,从而在 2023 年和 2024 年成功推出 Notion AI 功能。
