2024-8-22 00:0:26 Author: hackernoon.com(查看原文) 阅读量:3 收藏
Table of Links
3 End-to-End Adaptive Local Learning
3.1 Loss-Driven Mixture-of-Experts
3.2 Synchronized Learning via Adaptive Weight
4 Debiasing Experiments and 4.1 Experimental Setup
4.3 Ablation Study
4.4 Effect of the Adaptive Weight Module and 4.5 Hyper-parameter Study
6 Conclusion, Acknowledgements, and References
4 Debiasing Experiments
In this section, we present a comprehensive set of experiments to highlight the strong debiasing performance of the proposed method, validate the effectiveness of various model components, assess the impact of the proposed adaptive weight module, and examine the impact of hyperparameters.

4.1 Experimental Setup

Considering the Rawlsian Max-Min fairness principle [29], the goal of debiasing is to promote the average NDCG@20 for subgroups with low mainstream scores while preserving or even improving the utility for subgroups with high mainstream scores at the same time. Hence, we also anticipate an increase in the overall NDCG@20 of the model.
Baselines. In the experiments, we compare the proposed TALL with MultVAE and four state-of-art debiasing methods: (1) MultVAE [26] is the widely used vanilla recommendation model without debiasing. (2) WL [39] is a global method designed to assign more weights to niche users in the training loss of MultVAE.
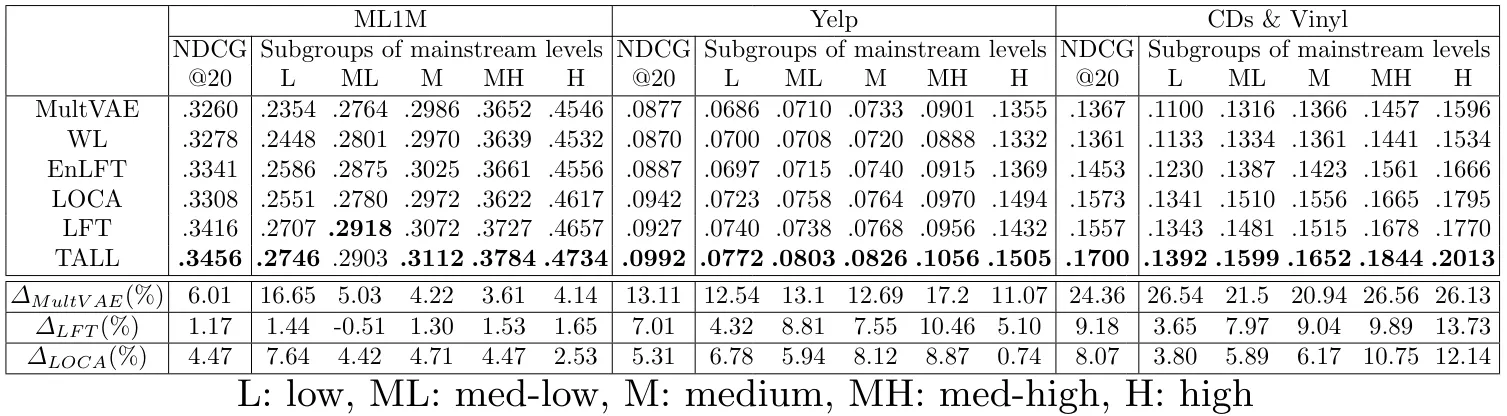
(3) LOCA [12] is a local learning model that trains multiple anchor models corresponding to identified anchor users and aggregates the outputs from anchor models based on the similarity between the target user and anchor users. (4) LFT [39] is the SOTA local learning model that first trains a global model with all data and then fine-tunes a customized local model for each user using their local data for the target user. (5) EnLFT [39] is the ensembled version of LFT, which is similar to LOCA but trains the anchor models by the approach of LFT.
To fairly compare the performance of different baselines and our proposed model, for all four debiasing baselines and our proposed TALL, we adopt the MultVAE as the base model (or the expert model in TALL). LOCA, EnLFT, and TALL have the same complexity with a fixed number of MultVAE in them. And owing to the end-to-end training paradigm, TALL takes less training time than other local learning baselines. Last, LFT has the largest complexity, which has an independent MultVAE for each user.
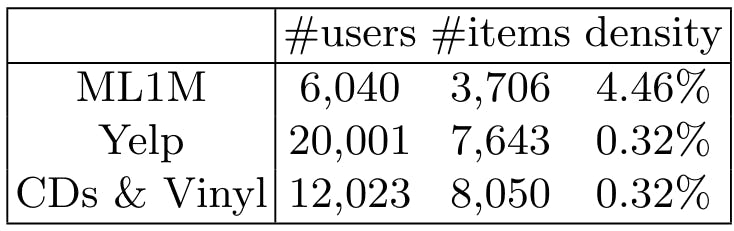
Reproducibility. All models are implemented in PyTorch and optimized by the Adam algorithm [20]. For the baseline MultVAE and the MultVAE component in other models, we set one hidden layer of size 100. And we maintain the number of local models at 100 for LOCA, EnLFT, and TALL for all datasets to ensure a fair comparison. All other hyper-parameters are grid searched by the validation sets. All code and data can be found at https:// github.com/ JP-25/ end-To-end-Adaptive-Local-Leanring-TALL-.
Authors:
(1) Jinhao Pan [0009 −0006 −1574 −6376], Texas A&M University, College Station, TX, USA;
(2) Ziwei Zhu [0000 −0002 −3990 −4774], George Mason University, Fairfax, VA, USA;
(3) Jianling Wang [0000 −0001 −9916 −0976], Texas A&M University, College Station, TX, USA;
(4) Allen Lin [0000 −0003 −0980 −4323], Texas A&M University, College Station, TX, USA;
(5) James Caverlee [0000 −0001 −8350 −8528]. Texas A&M University, College Station, TX, USA.
如有侵权请联系:admin#unsafe.sh