2024 KCTF 大赛于8月15日正式开赛!比赛设置了多维度的评分体系,包括难度值、火力值和精致度积分,旨在引导竞赛的难度和趣味度,使其更具挑战性和吸引力。同时,也为参赛选手提供了更加公平、有趣的竞赛平台。
今天中午12点,第四题《神秘信号》已截止答题,【Li0kle】战队用时4小时19分1秒 抢先拿下此题,第二名来自【保护不保护保护】战队、第三名来自【Nepnep】战队。
*注意:签到题《逐光启航》持续开放,整个比赛期间均可提交答案获得积分
本题共有23支战队成功破解,围观人数达1500+。据参赛选手反馈,本题也是蛮有意思的,一起来看看设计思路和题解吧。
出题战队:one team
战队成员ID:穿甲葡萄籽
设计思路
1.程序是pyinstaller打包,还原主文件。
2.可以发现打包程序并无CrackMe的库。如此可推测,在import时动了手脚。对base_library.zip中的文件进行搜索,寻找_find_and_load_unlocked相关调用。可以发现,在codes.pyc中出现此调用。该文件是不应该出现这个调用的。
还原此pyc代码,可发现以下代码:
3.当import的库名称是CrackMe时,就加载base64库。并且把不需要的属性均去除,只留下main属性。找到base64对应的pyc,进行还原。
可发现以下代码:
4.这里是手动制作一个code类型,可通过dis对此code进行反编译。或输出为pyc文件再进行反编译。
得到一个自定义的base64编码函数:
5.随后根据这个函数,写出一个解码函数来。
6.随后对main.py中dZpK字符串进行解码。发现解码后的数据为乱码。并且input输入的数据和得到的结果不一致。
7.根据论坛地址:https://bbs.kanxue.com/thread-276493.htm,所提及的方式,可找到input所hook的函数地址。是一段shellcode,反汇编其算法,是一个简单亦或算法。
8.综合一下,即可算出验证码。
赛题解析
本赛题解析由看雪论坛学者【mb_mgodlfyn】提供,来自hzqmwne战队。
pyinstaller打包的二进制,用 pyinstxtractor 或 pyinstxtractor-ng 解包(一定要用最新版本,可以省去自己补pyc文件头的步骤)
解释器版本是Python3.8,看到 main.pyc 熟练的掏出 uncompyle6 和 decompyle3 反编译一下:
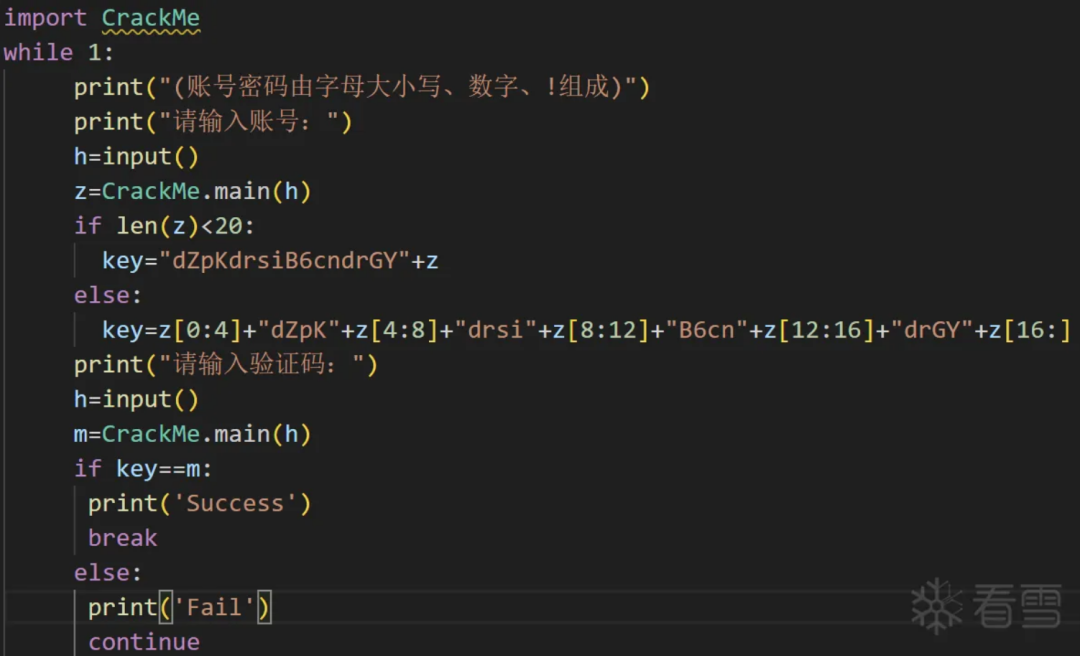
import CrackMewhile True:while True:print("(账号密码由字母大小写、数字、!、空格组成)")print("请输入账号:")h = input()z = CrackMe.main(h)if len(z) < 20:key = "dZpKdrsiB6cndrGY" + zelse:key = z[0:4] + "dZpK" + z[4:8] + "drsi" + z[8:12] + "B6cn" + z[12:16] + "drGY" + z[16:]print("请输入验证码:")h = input()m = CrackMe.main(h)if key == m:print("Success")breakprint("Fail")continue
看着很友好,但是,CrackMe模块在哪里呢?
各种失败的尝试:
对着解包后的文件各种find+grep没有找到任何包含"CrackMe"字样的东西(除了main.pyc)
试着反编译解包出来的pyiboot*和pyimod*文件,无果
(就差对着源码开始调试pyinstaller了)
官方群里看到有人说搜内存,想了想一是太麻烦,二是剧透嫌疑,决定先不搞
发现一个有意思的工具 pyrasite,能够调试器挂进程找到PyRun_SimpleString之类的函数直接注入代码开启一个交互式的shell(可惜,在本题试验没成功)
Process Monitor 看程序读写的文件,似乎都很正常……等等,有一个 _internal/_lzma.pyd ?
既然 _internel 目录下的 pyd 文件会被加载,那么不妨试试在这里做注入。
将 _internal/_lzma.pyd 文件删除,放一个 _internal/_lzma.py 文件,里面写上自己想执行的语句:
import sysprint(sys.modules)
import CrackMeprint(CrackMe)
输出:
<module 'base64' from '...\\main\\_internal\\base64.pyc'>CrackMe的真身竟然是base64?
找到解包出来的 base64.pyc ,反编译一下,果然在末尾有偷梁换柱:
a = main.__code__.replace(1, (), b'd\x01}\x01d\x02}\x02d\x03}\x03d\x04}\x04|\x00D\x00]\x1c}\x05|\x05d\x05A\x00}\x05|\x04|\x05\xa0\x00d\x06d\x07\xa1\x02\x17\x00}\x04q\x14|\x04}\x00t\x01d\x02t\x02|\x00\x83\x01d\x08\x83\x03D\x00]\x90}\x05|\x00|\x05|\x05d\x08\x17\x00\x85\x02\x19\x00}\x06d\x01\xa0\x03d\td\n\x84\x00|\x06D\x00\x83\x01\xa1\x01}\x07t\x01d\x02t\x02|\x07\x83\x01d\x0b\x83\x03D\x00]V}\x08|\x07|\x08|\x08d\x0b\x17\x00\x85\x02\x19\x00}\tt\x02|\t\x83\x01d\x0bk\x00r\xc2|\x02d\x0bt\x02|\t\x83\x01\x18\x007\x00}\x02|\td\x0cd\x0bt\x02|\t\x83\x01\x18\x00\x14\x007\x00}\t|\x01|\x03t\x04|\td\r\x83\x02\x19\x007\x00}\x01q~qF|\x01d\x0e|\x02d\r\x1a\x00\x14\x007\x00}\x01t\x01t\x02|\x01\x83\x01d\r\x1a\x00\x83\x01D\x00]L}\x05|\x01|\x05d\r\x14\x00\x19\x00}\n|\x01|\x05d\r\x14\x00d\x06\x17\x00\x19\x00}\x0b|\x01d\x00|\x05d\r\x14\x00\x85\x02\x19\x00|\x0b\x17\x00|\n\x17\x00|\x01|\x05d\r\x14\x00d\r\x17\x00d\x00\x85\x02\x19\x00\x17\x00}\x01q\xf8|\x01S\x00', (None, '', 0, 'ZQ+U7tSBEKVzyf5coCwb94Dd6raT0eLNin12Hp8mOxFuvMgIPlhRY3WjksqJAXG/', b'', 85, 1, 'little', 3, compile('', '', 'exec').replace(1, (), b'|\x00]\x10}\x01t\x00|\x01d\x00\x83\x02V\x00\x01\x00q\x02d\x01S\x00', ('08b', None), '', 19, 115, (), 0, b'', '', ('format',), 2, 0, 4, ('.0', 'byte'), **('co_argcount', 'co_cellvars', 'co_code', 'co_consts', 'co_filename', 'co_firstlineno', 'co_flags', 'co_freevars', 'co_kwonlyargcount', 'co_lnotab', 'co_name', 'co_names', 'co_nlocals', 'co_posonlyargcount', 'co_stacksize', 'co_varnames')), '', 6, '0', 2, '!'), '', 4, 67, (), 0, b'', '', ('to_bytes', 'range', 'len', 'join', 'int'), 12, 0, 7, ('data', 'encoded_str', 'padding', 'base64_chars', 'ww', 'i', 'chunk', 'binary_str', 'j', 'six_bits', 'a', 'b'), **('co_argcount', 'co_cellvars', 'co_code', 'co_consts', 'co_filename', 'co_firstlineno', 'co_flags', 'co_freevars', 'co_kwonlyargcount', 'co_lnotab', 'co_name', 'co_names', 'co_nlocals', 'co_posonlyargcount', 'co_stacksize', 'co_varnames'))main.__code__ = a
所以 CrackMe.main 就是 base64.main,而它的字节码也被替换掉了
稳妥起见,不去处理上面反编译的东西,而是直接在_lzma.py的hook中dump原始字节码:
import CrackMeimport marshalimport importlibcode = CrackMe.main.__code__marshal_data = marshal.dumps(code)pyc_data = importlib._bootstrap_external._code_to_timestamp_pyc(code)with open("crackme_main.marshal", "wb") as f:f.write(marshal_data)with open("crackme_main.pyc", "wb") as f:f.write(pyc_data)
(pyc_data参考自 https://stackoverflow.com/questions/73439775/how-to-convert-marshall-code-object-to-pyc-file )
得到的 crackme_main.pyc,uncompyle6和decompyle3都会报错,不过标准库的dis模块能正常反汇编。
人工翻译了一会……突然想起了 pycdc ,试了下效果非常完美(需要小修一下)(对反编译的代码重新生成pyc再dis对比,与dump出来的dis完全相同):
def main(data): # def是自己补上的encoded_str = ''padding = 0base64_chars = 'ZQ+U7tSBEKVzyf5coCwb94Dd6raT0eLNin12Hp8mOxFuvMgIPlhRY3WjksqJAXG/'ww = b''for i in data:i = i ^ 85ww = ww + i.to_bytes(1, 'little')data = wwfor i in range(0, len(data), 3):chunk = data[i:i + 3]# binary_str = ''.join((lambda .0: for byte in .0: format(byte, '08b'))(chunk)) 反编译出来这里的语法不太对binary_str = ''.join(format(byte, '08b') for byte in chunk)for j in range(0, len(binary_str), 6):six_bits = binary_str[j:j + 6]if len(six_bits) < 6:padding += 6 - len(six_bits)six_bits += '0' * (6 - len(six_bits))encoded_str += base64_chars[int(six_bits, 2)]encoded_str += '!' * (padding // 2)for i in range(len(encoded_str) // 2):a = encoded_str[i * 2]b = encoded_str[i * 2 + 1]encoded_str = encoded_str[:i * 2] + b + a + encoded_str[i * 2 + 2:]return encoded_str
写出逆向算法:
def rev(encoded_str):tmp = encoded_strtmp = "".join(tmp[2*i+1]+tmp[2*i] for i in range(len(tmp)//2))tmp = tmp.rstrip("!")trans = str.maketrans("ZQ+U7tSBEKVzyf5coCwb94Dd6raT0eLNin12Hp8mOxFuvMgIPlhRY3WjksqJAXG/", "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/");tmp2 = tmp.translate(trans)tmp2 += "=" * ((4-len(tmp2))%4)tmp3 = base64.b64decode(tmp2)data = bytes(c ^ 85 for c in tmp3)return data.decode()
事情看起来解决了?不,问题才刚刚开始。逆向出来的main函数,其参数data的类型显然需要是bytes,但是main.py调用的时候传递的是str,只好先按bytes传递,先用给的序列号做验证:
def ztokey(z):if len(z) < 20:key = 'dZpKdrsiB6cndrGY' + zelse:key = z[0:4] + 'dZpK' + z[4:8] + 'drsi' + z[8:12] + 'B6cn' + z[12:16] + 'drGY' + z[16:]return keyz = main(b"D7C4197AF0806891")key = ztokey(z)m = main(b"D7CHel419lo 7AFWor080ld!6891")print(z)print(key)print(m)print(rev(m))
D7DED6vCn6boDrp3W6v3Zr!!D7DEdZpKD6vCdrsin6boB6cnDrp3drGYW6v3Zr!!D7DEbBsZD6vCb53xn6bo2ZmODrp3b5YtW6v3Zr!!D7CHel419lo 7AFWor080ld!6891
rev的逻辑没有错误,问题出现在main.py里面,疑似ztokey时实际拼接的几个字符串常量与看到的不同。
先不去深究,根据上面输出的key和m的对应关系,猜测真正的ztokey2应该是这样:
def ztokey2(z):if len(z) < 20:key = 'bBsZb53x2ZmOb5Yt' + zelse:key = z[0:4] + 'bBsZ' + z[4:8] + 'b53x' + z[8:12] + '2ZmO' + z[12:16] + 'b5Yt' + z[16:]return keyz = main(b"KCTF")key = ztokey(z)key2 = ztokey2(z)print(z)print(key)print(key2)print(rev(key))print(rev(key2))
得到输出:
nBQ6P7!!dZpKdrsiB6cndrGYnBQ6P7!!bBsZb53x2ZmOb5YtnBQ6P7!!T'00-l5-0(kKCTFHello World!KCTF
最终提交答案为 Hello World!KCTF
拿到题第一时间看了下 _internel 目录下 python38.dll 发现带有官方的数字签名,如蒙大赦,感谢出题人没搞什么自己魔改解释器的恶心套路。
题目的未解之谜还有很多,继续通过_lzma.py的hook探索:
import CrackMeimport sysorigin_crackme_main = CrackMe.maindef hook_decompile_crackme_main(data):print(repr(data))r = origin_crackme_main(data)print(repr(r))return rCrackMe.main = hook_decompile_crackme_mainsys.modules["CrackMe"] = CrackMe
最后给sys.modules赋值是必须的,否则会出现异常:
Traceback (most recent call last):File "main.py", line 6, in <module>AttributeError: 'NoneType' object has no attribute 'main'
打印出 CrackMe.main 函数的实际输入输出,发现输入 "KCTF" 时,CrackMe.main 函数的输入是 b'QI8F',输出是 'QQMlP7!!'
输入值在此之前被修改过。输入和输出与逆向出来的算法能对应,至少说明逆向过程没有问题。
回忆一下main.py的片段:
...print("请输入账号:")h = input()z = CrackMe.main(h)...
那么只有两种可能:main.py是虚假的,或者,input被修改过。
hook一下input看看:
old_input = inputdef hook_input(*args, **kwargs):r = old_input(*args, **kwargs)print(repr(old_input), hex(id(old_input)), repr(r))return r__builtins__["input"] = hook_input
得到输出:
...请输入账号:KCTF<built-in function input> 0x18e4b220a90 b'QI8F'...
问题得到确认,builtin的input被修改过,它的返回值是经过变换的。但是,repr仍然标记为built-in,所以这里是如何实现的?
知己知彼还是非常重要的。每道题目放出前会习惯性的看一下出题人曾经在论坛发过的文章。出题人今年发了一系列python源码分析的文章,所以有预感第四题可能是python,而事实确实如此。
在此回顾下出题人的几篇文章:
[原创]向pyc注入shellcode或python代码
[原创]Python源码解析-PYC文件
[原创]Python源码解析-import过程
[原创]Python源码解析-builtin_function_or_method
第一篇讲了pyinstaller打包时篡改标准库注入代码
第二篇讲了替换函数的__code__属性改变其逻辑
第三篇讲了修改_frozen_importlib._find_and_load.__code__改变模块加载过程
第四篇讲了内存patch修改builtin函数(builtin函数没有__code__属性,通过内置id函数可以获得PyMethodDef结构的地址,PyMethodDef偏移16字节处是指向PyCFunction结构的指针,PyCFunction偏移8字节的地方是真正的C函数起始地址)
一和二已经观察到了,现在确认一下三和四。老方法通过_lzma.py的hook把_frozen_importlib._find_and_load.__code__的内容dump出来:
import _frozen_importlibtmp = importlib._bootstrap_external._code_to_timestamp_pyc(_frozen_importlib._find_and_load.__code__)with open("_frozen_importlib._find_and_load.__code__.pyc", "wb") as f:f.write(tmp)
然后用pycdc反编译:(有 WARNING: Decompyle incomplete ,可以用 pydas 看反汇编,缺少的地方不重要,先不去管)
a = 0if len(name) == 7 and name[0] == 'C' and name[1] == 'r' and name[2] == 'a' and name[3] == 'c' and name[4] == 'k' and name[5] == 'M' and name[6] == 'e':name = 'base64'a = 1module = sys.modules.get(name, _NEEDS_LOADING)
前面hook内置input函数时顺便打印了id(input)的值,挂上调试器按照文章的说法找到最终函数所在,dump内存,ida分析:
__int64 __fastcall sub_136EDA194A0(__int64 a1, __int64 a2){__int64 v2; // rdx__int64 v3; // rdxunsigned int m; // [rsp+30h] [rbp-238h]unsigned int i; // [rsp+34h] [rbp-234h]__int64 v7; // [rsp+38h] [rbp-230h]unsigned int v8; // [rsp+40h] [rbp-228h] BYREFint j; // [rsp+44h] [rbp-224h]int k; // [rsp+48h] [rbp-220h]_DWORD *v11; // [rsp+50h] [rbp-218h]char v12[16]; // [rsp+58h] [rbp-210h] BYREFchar v13[32]; // [rsp+68h] [rbp-200h] BYREFunsigned int *v14; // [rsp+88h] [rbp-1E0h]unsigned int v15; // [rsp+90h] [rbp-1D8h]_QWORD *v16; // [rsp+98h] [rbp-1D0h]__int64 v17; // [rsp+A0h] [rbp-1C8h]__int64 v18; // [rsp+A8h] [rbp-1C0h]_DWORD *v19; // [rsp+B0h] [rbp-1B8h]__int64 (__fastcall *v20)(__int64, __int64, __int64, signed __int64); // [rsp+B8h] [rbp-1B0h]void (__fastcall *v21)(__int64, __int64, _BYTE *, __int64, __int64, unsigned int *); // [rsp+C0h] [rbp-1A8h]__int64 (__fastcall *v22)(__int64, __int64, __int64, char *); // [rsp+C8h] [rbp-1A0h]__int64 (__fastcall *v23)(__int64, __int64, char *, __int64); // [rsp+D0h] [rbp-198h]_QWORD *v24; // [rsp+D8h] [rbp-190h]__int64 (__fastcall *v25)(__int64, __int64, _QWORD, _BYTE *); // [rsp+E0h] [rbp-188h]__int64 v26; // [rsp+E8h] [rbp-180h]_QWORD *v27; // [rsp+F0h] [rbp-178h]__int64 v28; // [rsp+F8h] [rbp-170h]__int64 v29; // [rsp+100h] [rbp-168h]__int64 v30; // [rsp+108h] [rbp-160h]__int64 v31; // [rsp+110h] [rbp-158h]_BYTE v32[112]; // [rsp+120h] [rbp-148h] BYREF_BYTE v33[216]; // [rsp+190h] [rbp-D8h] BYREFv26 = *(_QWORD *)(*(_QWORD *)(sub_136EDA19BA0() + 96) + 24LL);v24 = (_QWORD *)(v26 + 16);v16 = *(_QWORD **)(v26 + 16);v20 = 0LL;v21 = 0LL;v22 = 0LL;v23 = 0LL;v25 = 0LL;while ( v16 != v24 ){v27 = v16;v16 = (_QWORD *)*v16;v7 = v27[6];v28 = *(int *)(v7 + 60) + v7;v15 = *(_DWORD *)(v28 + 136);if ( v15 ){v14 = (unsigned int *)(v15 + v7);if ( v14[6] ){v19 = (_DWORD *)(v14[3] + v7);if ( (*v19 | ' ') == 'nrek' && (v19[1] | ' ') == '23le' && (v19[2] | ' ') == 'lld.' )// kernel32.dll{v18 = v14[7] + v7;v29 = v14[8] + v7;v17 = v14[9] + v7;for ( i = 0; i < v14[6]; ++i ){v11 = (_DWORD *)(*(unsigned int *)(v29 + 4LL * i) + v7);if ( *v11 == 'SteG' && v11[1] == 'aHdt' )// GetStdHav20 = (__int64 (__fastcall *)(__int64, __int64, __int64, signed __int64))(*(unsigned int *)(v18 + 4LL * *(unsigned __int16 *)(v17 + 2LL * i))+ v7);if ( *v11 == 'daeR' && v11[1] == 'snoC' )v21 = (void (__fastcall *)(__int64, __int64, _BYTE *, __int64, __int64, unsigned int *))(*(unsigned int *)(v18 + 4LL * *(unsigned __int16 *)(v17 + 2LL * i)) + v7);if ( *v11 == 'daoL' && v11[1] == 'rbiL' && v11[2] == 'Ayra' )// LoadLibraryAv22 = (__int64 (__fastcall *)(__int64, __int64, __int64, char *))(*(unsigned int *)(v18+ 4LL* *(unsigned __int16 *)(v17 + 2LL * i))+ v7);if ( *v11 == 'PteG' && v11[1] == 'Acor' )// GetProcAv23 = (__int64 (__fastcall *)(__int64, __int64, char *, __int64))(*(unsigned int *)(v18+ 4LL* *(unsigned __int16 *)(v17 + 2LL * i))+ v7);if ( v20 && v21 && v22 && v23 ){v30 = v20(a1, a2, v2, '\xFF\xFF\xFF\xF6');for ( j = 0; j < 100; ++j )v32[j] = 0;v8 = 0;v21(a1, a2, v32, v30, 50LL, &v8);for ( k = 0; k < 200; ++k )v33[k] = 0;v33[0] = 's';for ( m = 0; m < v8; ++m ){if ( v32[m] == '\r' || (char)v32[m] == '0x00' || v32[m] == '\n' ){v8 = m;break;}v33[m + 5] = (v32[m] ^ 0x77) + 21;}*(_DWORD *)&v33[1] = v8;strcpy(v12, "python38.dll");v31 = v22(a1, a2, v3, v12);strcpy(v13, "PyMarshal_ReadObjectFromString");v25 = (__int64 (__fastcall *)(__int64, __int64, _QWORD, _BYTE *))v23(a1, a2, v13, v31);return v25(a1, a2, v8 + 5, v33);}}}}}}return 0LL;}
注意到 v33[m + 5] = (v32[m] ^ 0x77) + 21
做个验证:
def convertinput(s):return bytes((ord(c) ^ 0x77) + 21 for c in s)assert convertinput("KCTF") == b'QI8F'assert main(convertinput("KCTF")) == "QQMlP7!!"assert main(convertinput("Hello World!KCTF")) == "dZpKdrsiB6cndrGYQQMlP7!!"
与先前的所有观察都能对应上,包括main.py里面的常量。
也能解释为什么胡乱输入偶尔会触发builtin input return NULL的System Error:
Traceback (most recent call last):File "PyInstaller\loader\pyiboot01_bootstrap.py", line 78, in <module>File "PyInstaller\loader\pyimod03_ctypes.py", line 96, in installFile "codecs.py", line 37, in funFile "...\main\_internal\ctypes\util.py", line 2, in <module>import shutilFile "codecs.py", line 37, in funFile "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlockedFile "<frozen importlib._bootstrap>", line 671, in _load_unlockedFile "PyInstaller\loader\pyimod02_importers.py", line 419, in exec_moduleFile "shutil.py", line 29, in <module>File "codecs.py", line 37, in funFile "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlockedFile "<frozen importlib._bootstrap>", line 671, in _load_unlockedFile "PyInstaller\loader\pyimod02_importers.py", line 419, in exec_moduleFile "lzma.py", line 27, in <module>File "codecs.py", line 37, in funFile "...\main\_internal\_lzma.py", line 105, in <module>print(input())SystemError: <built-in function input> returned NULL without setting an error
至于为什么忽略convertinput的转换也能找到正确的答案,回顾一下CrackMe.main函数的逻辑,依次是单字节异或、换表base64、相邻两字节交换。
那么,输出的每4个字节实际只受对应输入的3个字节影响。
而main.py里恰恰是对CrackMe.main输出以4字节为单位做重组,对于"KCTF"这样的短输入,甚至只是直接移动到末尾。
所以,最终的serial,一定是输入的name与"Hello World!"这个12字节的常量的组合。
事实上,convertinput可以改成任意的单字节映射,都不影响这个结论。
至此,题目最后的谜团只有对_frozen_importlib._find_and_load和input两处的修改是在何处初始化的。
估计是藏在了某个模块的初始化代码里,具体可能要追pyinstaller的初始化流程。不过,从上面SystemError的调用栈来看,这两处修改的位置相当早,至少在加载_lzma.py之前已经完成了。
今日中午12点,第五题 废弃星球
正式开赛
球分享
球点赞
球在看
点击阅读原文查看更多
如有侵权请联系:admin#unsafe.sh