
2024-8-23 20:26:15 Author: isc.sans.edu(查看原文) 阅读量:4 收藏
While trying to process some of my honeypot data, I ran into the following error in my Python script:
"Exception has occurred: ValueError
values should be unique if codes is not None"
I received the error while tring to merge two Pandas DataFrames [1]:
cowrie_data = cowrie_data.merge(df, on=["dates", "src_ip", "input", "outfile", "username", "password"], how="outer") When looking for solutions, I found very little information outside some documentation [2]. The data being joined was data from two different honeypots. It included Cowrie [3] data from 6 different JSON keys:
- dates (converted to "%Y-%m-%d" format from the "timestamp" key)
- src_ip (source IP address)
- input (commands submitted to Cowrie in SSH/telnet session)
- outfile (storage file paths for files uploaded/downloaded to the honeypot, usually malware)
- username (username submitted to Cowrie during SSH or telnet session authentication attempt)
- password (password submitted to Cowrie during SSH or telnet session authentication attempt)
I didn't know what data may be causing the issue, so I decided to tweak my "pd.merge" statement to merge the DataFrames, starting with only one row and expanding the dataset a row at a time until an error occured.
row_number = 0
while row_number < len(cowrie1) and row_number < len(cowrie2):
try:
data = cowrie1[0: row_number + 1].merge(cowrie2[0: row_number + 1], on=["dates", "src_ip", "input", "outfile", "username", "password"], how="outer")
except:
print(row_number)
print("row: ", cowrie1[0: row_number + 1])
print("row: ", cowrie2[0: row_number + 1])
break
row_number += 1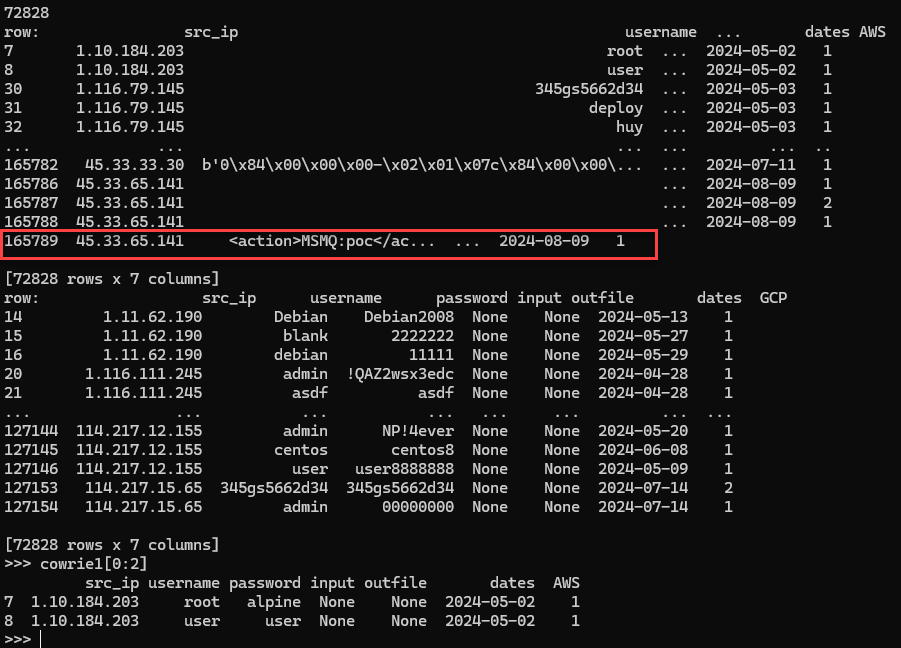
Figure 1: Contents of DataFrames attempted to be merged at the time an exception occurred.
An error eventually occurred, but the data didn't look unusual. However, when looking at the specific data field, I saw something unexpected.
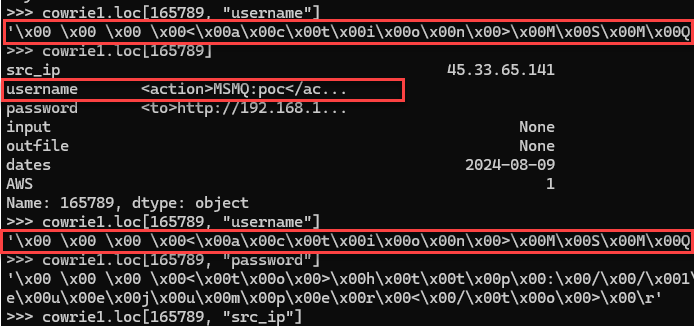
Figure 2: Samples of data that caused the exception.
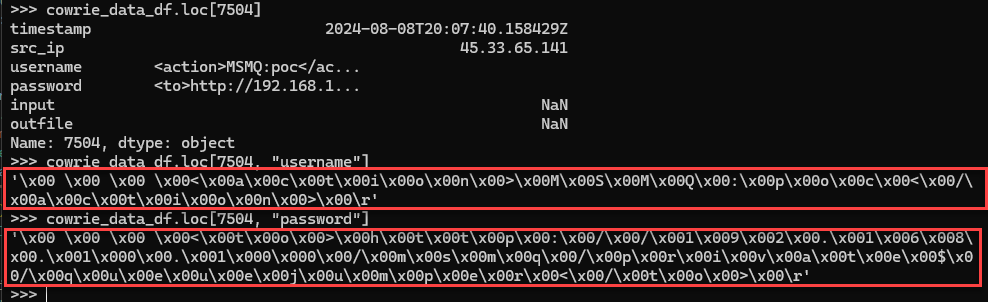
Figure 3: Samples of data that caused the exception from a different experiment.
How did the null bytes "\x00" get into the dataset? What did this look like in the original Cowrie JSON logs? This error was surprising since the scripts were used to proces about a month of data from half a dozen different honeypots. This error had never occured from that dataset, but presented when expanding the timeframe from a one month to a four month period. This script also exported the data to a SQLite file before joining the two DaraFrames. I was unable to find the data in the SQLite when searching for the null bytes. I was also unable to find the data when looking at the JSON logs. I used the raw timestamp, as seen in Figure 3, to help find the specific log data that generated the error.
Once I had the exact timestamp, I was able to find the log:
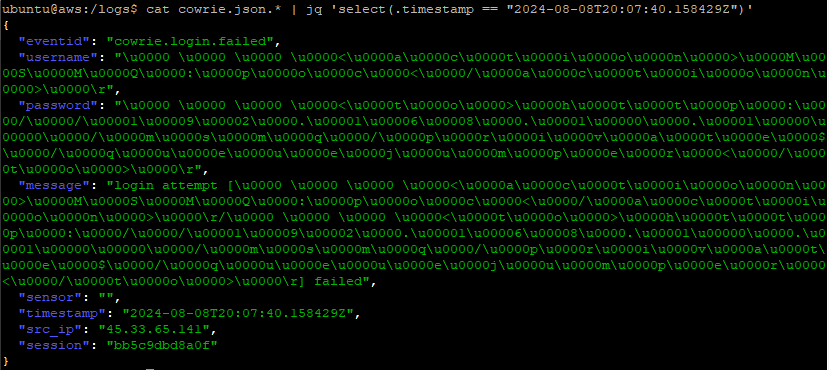
Figure 4: Raw Cowrie logs that eventually generated the python error
I now had my culprit and determined why I was never able to find the exact same string within the logs. Tthe same data in the SQLite database looked very different as well.

Figure 5: BLOB data shown in SQLite database
To resolve the error, I removed the null bytes using "replace".
log_data[each_key] = yielded_json[each_key].replace('\x00','') # added .replace('\x00','') on 8/17/24 to replace null bytes for pandas merge issues.PNG)
Figure 6: Data represented in SQLite database without null values.
Some takeaways:
- Data changes. The error may not occur today, but may in the future
- Use more logging
- Use more exception handling
- Test with a variety of data
I also hope that unlike my earlier attempts to troubleshoot, someone finds this article in their own Google search when they run into the same error.
[1] https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html
[2] https://pydocs.github.io/p/pandas/1.4.2/api/pandas.core.algorithms.safe_sort.html
[3] https://github.com/cowrie/cowrie
--
Jesse La Grew
Handler
如有侵权请联系:admin#unsafe.sh