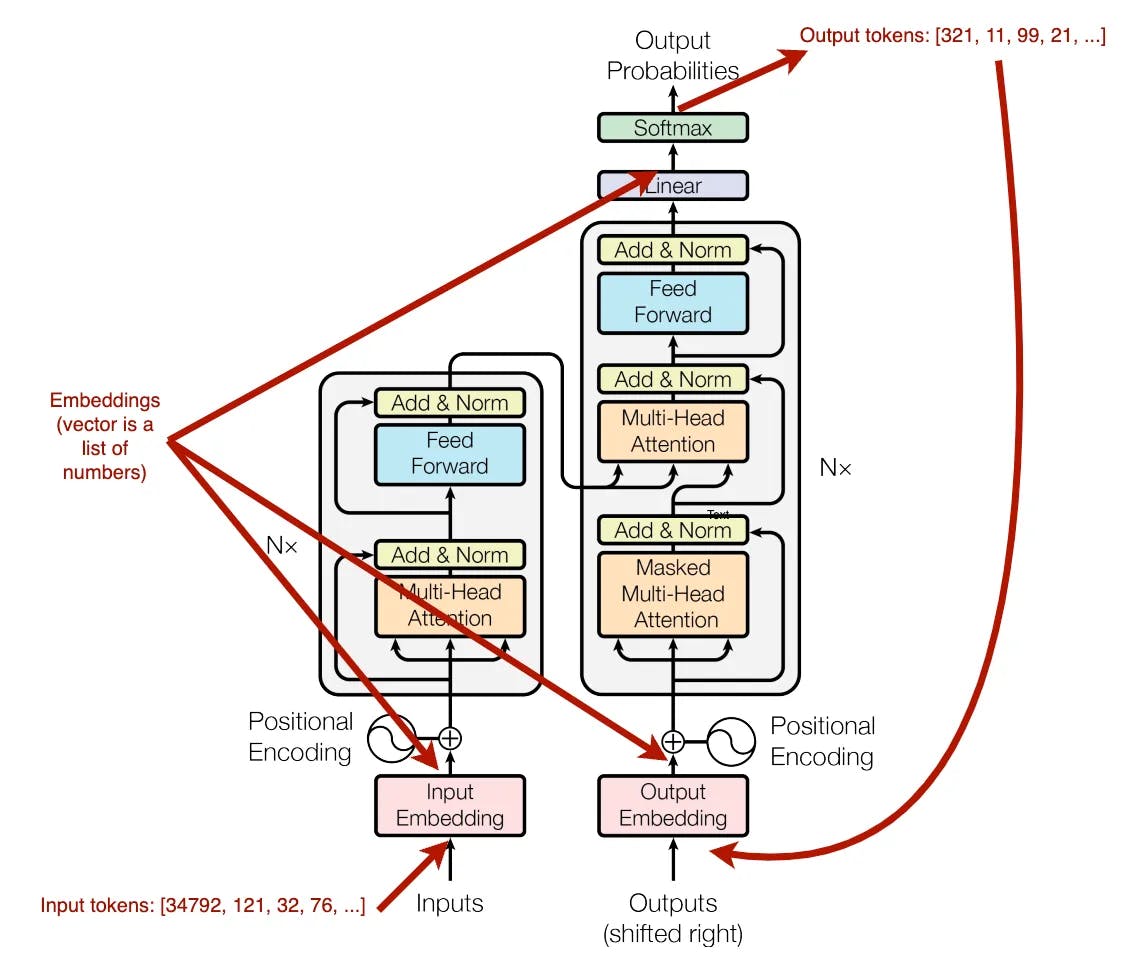
I’m going to cover the basics and provide you with a clear road map for understanding how these models absorb and process the complex world of human language.
What Are Embeddings?
Imagine trying to use simple pictures to express a complicated idea. Embeddings function similarly but with numerical values. They transform complicated text data into simpler numerical representations without losing the essence of the information. In NLP, this can be achieved by converting words, sentences, or even entire documents into numerical vectors(sets of numbers) that represent their relationships and meanings.
Why Are Embeddings Important in NLP?
Embeddings are like the secret sauce for many NLP tasks. They allow algorithms to perform tasks like accurately comparing the similarity of words and sentences by turning text into numbers. Applications like text classification, sentiment analysis, and machine translation depend on this feature. In basic terms, because of embeddings computers are capable of reading and comprehending human languages.
Types of Embeddings: From One-Hot to Contextual
- One-Hot Encoding: The journey of embeddings in NLP starts with the simplest form known as one-hot encoding, where each word is represented as a vector filled with zeros except for a single one in the position corresponding to the word in the vocabulary. However, this method has its limitations, primarily the inability to capture the semantic relationships between words.

More advanced types of embeddings have been developed to get around these limitations. Pre-trained embeddings, such as Word2Vec and GloVe, are able to capture word meanings and relationships by leveraging their co-occurrence in large data. Despite being a huge step forward, these models were unable to comprehend the context of words used in different sentences.
Now come contextual embeddings, the most advanced type of embedding technology, such as those produced by BERT, OpenAI, and other LLMs. These models allow for a dynamic representation of words based on the text around them by taking into account the complete context in which a word appears. The performance of NLP systems has significantly increased because of this technique in a variety of tasks.

How Embeddings Capture Meaning
The secret of embeddings’ enchantment is their ability to capture the core meaning of words and sentences in a way that is machine-readable. Through extensive text analysis, embeddings pick up relationships and patterns that mirror real-world word usage.
For example, words used in similar circumstances will have vector space embeddings that are near together. This closeness of 2 embedding vectors means that both the words or sentences belong to a similar category or have good similarity in them. By use of this technique, embeddings improve algorithms’ understanding of languages, ranging from synonyms and antonyms to complex connections such as analogies.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from gensim.models import KeyedVectors
import gensim.downloader as api
# Load a pre-trained word2vec model
model = api.load("word2vec-google-news-300")
# Function to convert words to vectors
def word_to_vector(word):
if word in model:
return model[word]
else:
print(f"Word '{word}' not in vocabulary!")
return None
# Example words
words = ["king", "queen", "man", "woman", "apple", "banana"]
# Convert words to vectors
word_vectors = {word: word_to_vector(word) for word in words}
# Extract vectors for PCA
vectors = np.array([vector for vector in word_vectors.values() if vector is not None])
# Perform PCA to reduce dimensions to 2 for visualization
pca = PCA(n_components=2)
reduced_vectors = pca.fit_transform(vectors)
# Plot the words in 2D space
plt.figure(figsize=(10, 7))
for word, (x, y) in zip(word_vectors.keys(), reduced_vectors):
plt.scatter(x, y)
plt.text(x + 0.01, y + 0.01, word, fontsize=12)
plt.title("Word Embeddings Visualization")
plt.xlabel("PCA Component 1")
plt.ylabel("PCA Component 2")
plt.grid(True)
plt.show()
The above code prints the vectors for all four words:
- Vector for ‘king’: [ 0.50451 0.68607 -0.59517 -0.022801 0.60046 -0.13498 -0.08813 0.47377 -0.61798 -0.31012 ]…
- Vector for ‘queen’: [ 0.37854 1.8233 -1.2648 -0.1043 0.35829 0.60029 -0.17538 0.83767 -0.056798 -0.75795 ]…
- Vector for ‘apple’: [ 0.52042 -0.8314 0.49961 1.2893 0.1151 0.057521 -1.3753 -0.97313 0.18346 0.47672 ]…
- Vector for ‘banana’: [-0.25522 -0.75249 -0.86655 1.1197 0.12887 1.0121 -0.57249 -0.36224 0.44341 -0.12211]…
These vectors can be visualised in a graph to show their relationships. For example, ‘king’ and ‘queen’ would be closer together, just as ‘apple’ and ‘banana’ would be, indicating their semantic similarity.

The ‘king’ and ‘queen’ vectors are located in one location, while the ‘banana’ and ‘apple’ vectors are located in another. Given that this is a 2-D graphic and that these vectors exist in far more dimensions, it might not tell anything. For instance, in dimensions ranging from 768 to 1024.
Let’s examine one more scenario.

Although the vectors for ‘king’, ‘queen’, and’man’, ‘woman’ do not have identical values, they are present in a similar plane, as indicated by the position of the red and green arrows. In short, the vector for ‘Woman’ w.r.t. ‘Queen’ is extremely similar to the vector of ‘Man’ w.r.t. ‘King’.
The best part comes next. Suppose we are now in the embedding space.
In the above embedding space, if we know the distance and direction of Man’s vector w.r.t Women’s, we can use the same distance and direction to find where King’s vector w.r.t Queen.
These vector arithmetic processes on properly trained embeddings produce results that capture these relationships. Because of this, the embeddings are extremely powerful & magical!
Recent Advancements in Embeddings for NLP
The Evolution of Embeddings
The growing field of natural language processing (NLP) has gone through a notable shift from static to dynamic embeddings. At first, embeddings were static, which meant a single, constant vector was used to represent every word, independent of its context.
This method had drawbacks because it failed to sufficiently capture the many different meanings of words in various settings. However the introduction of dynamic embeddings marked a significant change. A far deeper understanding of language complexities is made possible by these more recent models, which provide representations that take the word’s context into account.
Breakthrough Models: BERT, GPT, and Beyond
Among the biggest developments in NLP are the introduction of models such as BERT (Bidirectional Encoder Representations from Transformers) and GPT. BERT changed how machines understand human language by reading text in both directions (left-to-right and right-to-left), providing a more complete knowledge of context. GPT, on the other hand, pushed the boundaries even further by producing human-like responses, showing the power of large language models in producing coherent and contextually relevant text. These models have raised the bar for what is possible in natural language processing, significantly improving tasks like the classification of texts, sentiment analysis, and machine translation.

# pip install transformers && pip install torch
from transformers import DistilBertTokenizerFast, DistilBertModel
tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
tokens = tokenizer.encode('This is a input.', return_tensors='pt')
print("These are tokens!", tokens)
for token in tokens[0]:
print("This are decoded tokens!", tokenizer.decode([token]))
model = DistilBertModel.from_pretrained("distilbert-base-uncased")
print(model.embeddings.word_embeddings(tokens))
for e in model.embeddings.word_embeddings(tokens)[0]:
print("This is an embedding!", e)
Transformer’s architecture has revolutionised embeddings in NLP. Transformers’ capacity to manage data sequences, as well as their attention processes, have allowed models to generate embeddings that focus on the most relevant parts of the text. This has resulted in a significant improvement in the quality and usefulness of embeddings, which can now capture deeper semantic meanings and linkages inside the text. Transformer designs have had a significant impact on embeddings, not only improving the performance of NLP tasks but also opening up new possibilities for comprehending and producing human language.
How Embeddings Contribute to Training Large Language Models
Embeddings are the backbone of a Large Language Model
Embeddings play an important role in the language model’s architecture. Embeddings simplify high-dimensional data, such as a language’s vocabulary, into a low-dimensional space. This not only simplifies the data but also maintains its semantic and grammatical consistency.

Embeddings help models understand the complex relations between words, accurately capturing their meanings and the context in which they’re used. The true magic is in how these dense vectors, which represent words, put similar words closer in the embedding space, offering a numerical measure of similarity. This foundational step is critical for developing advance models that are capable of understanding and producing human language with outstanding accuracy.
Scaling Up: Training Models with Billions of Parameters
As language models have become more complicated, they need an increasing number of parameters. The latest models have billions of parameters, representing both potential and challenges. The use of pre-trained embeddings is a good approach to these issues. Models can avoid the computationally hard and data-hungry process of creating these representations from start by using pre-trained embeddings on massive text datasets. This not only speeds up the training process but also provides the model with a thorough comprehension of language complexities from the very beginning. As a result, these pre-trained embeddings serve as a solid foundation, allowing models to modify and adjust these vectors through additional training, scaling up to meet the depth and complexity of human language.
Best Practices for Using Embeddings in NLP
Selecting the Right Type of Embedding for Your Task
Every embedding model has its own set of advantages and disadvantages, making the field rich and diverse. For example, certain embeddings are good at capturing language’s contextual subtleties, which makes them perfect for applications like sentiment analysis or machine translation that call for a deep comprehension of phrase structure and meaning. Some may be better at expressing single words, which is especially helpful for tasks like keyword extraction or text classification.

Here’s a breakdown to help you decide which model to use based on your needs.
Bag-of-Words (BoW)
- Use When: You need a simple and quick method for text representation. Ideal for small datasets where context is not crucial.
- Applications: Text classification, document similarity.
TF-IDF (Term Frequency-Inverse Document Frequency)
- Use When: You need to capture the importance of words in a document relative to a corpus. Best for cases where term frequency is important.
- Applications: Information retrieval, text classification, keyword extraction.
Word2Vec
- Use When: You need efficient word embeddings that capture semantic relationships between words. Good for larger datasets.
- Applications: Similarity tasks, clustering, text classification.
GloVe (Global Vectors for Word Representation)
- Use When: You need embeddings that capture global word co-occurrence statistics. Suitable for large corpora.
- Applications: Semantic similarity tasks, information retrieval.
FastText
- Use When: You need embeddings that can handle out-of-vocabulary words and subword information. Useful for languages with rich morphology.
- Applications: Text classification, sentiment analysis, language modelling.
ELMo (Embeddings from Language Models)
- Use When: You need to capture complex word meanings depending on context. Suitable for tasks requiring deep contextual understanding.
- Applications: Named entity recognition, sentiment analysis, coreference resolution.
COVE (Context Vectors)
- Use When: You need embeddings that leverage machine translation models for contextual information. Good for tasks requiring sentence-level context.
- Applications: Text classification, sentiment analysis, machine translation.
BERT (Bidirectional Encoder Representations from Transformers)
- Use When: You need state-of-the-art contextual embeddings that consider the entire sentence context. Ideal for diverse NLP tasks.
- Applications: Question answering, text classification, named entity recognition, sentiment analysis.
ALBERT (A Lite BERT)
- Use When: You need a lighter and more efficient version of BERT. Suitable for similar applications but with resource constraints.
- Applications: Similar to BERT with efficiency improvements.
GPT (Generative Pre-trained Transformer)
- Use When: You need to generate human-like text and require a strong contextual understanding. Good for generative tasks.
- Applications: Text generation, conversational AI, language modelling.
Cohere (and other advanced transformer models)
- Use When: You need highly advanced contextual embeddings with specialised capabilities. Suitable for cutting-edge NLP applications.
- Applications: Wide range of NLP tasks, including but not limited to those supported by BERT and GPT models.

Above is there list of top embedding models available on Hugging face and below is the code for how you can use them.
import torch
from sentence_transformers import SentenceTransformer
# Initialize torch settings
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Load the model from huggingface.
model_name = "WhereIsAI/UAE-Large-V1" # Just change model_name to use a different model!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Get the model parameters and save for later.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Print model parameters.
print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")
Fine-Tuning Pre-Trained Embeddings for Specific Applications
Pre-trained embeddings provide a substantial advantage by giving a solid foundation, particularly for individuals new to NLP. These embeddings, which have been trained on large text documents, contain a wealth of linguistic expertise that may be applied to your project right away. However, in order to fully use their potential, fine-tuning is necessary. This technique involves modifying the pre-trained embeddings to better match the specific characteristics and requirements of your application.
Fine-tuning can improve the performance of your NLP model by customising the embeddings to capture the vocabulary, context, and nuances specific to your domain. This could include training the embeddings on a specific dataset relevant to your industry or tailoring the training procedure to highlight specific characteristics of language use that are important for your application. By investing effort in fine-tuning, you may turn general-purpose embeddings into strong tools that drive the success of your NLP projects.
What can we expect in the future?
As Natural Language Processing (NLP) evolves, the next generation of embeddings promises to bring about even more advanced and comprehensive models. With the fast pace of development in embeddings, we can expect it to capture not only semantic and syntactic details of language but also additional dimensions such as practical analysis and discussion.

Future embeddings may use more advanced neural network architecture, combining multimodal input (such as text with visual or audio information) to produce richer, more thorough representations of language. Furthermore, ongoing research tries to improve the scalability and efficiency of embedding models, making them more useful in a broader range of applications and industries
Addressing Ethical Considerations in Embedding Training
With great power comes great responsibility. It becomes increasingly important to address ethical issues in the development and application of embeddings as they grow in strength and popularity. Making sure that embeddings do not reinforce or increase biases seen in the training data is one of the most important problems. Unfair and discriminatory results might result from biased embeddings, especially in sensitive applications like law enforcement tools or recruiting algorithms. Methods for identifying and reducing bias in embeddings are receiving more attention from researchers and practitioners in an effort to make sure that these models support diversity and fairness. Furthermore, there is an increasing focus on accountability and transparency when developing embedding models, which promotes the adoption of best practices that give ethical issues equal weight to technological performance.
如有侵权请联系:admin#unsafe.sh