摘要
本研究系统地比较了大型语言模型和传统基于约束的符号执行工具在生成定向测试输入方面的性能。通过研究发现,大型语言模型(如ChatGPT)可以在测试数据集上媲美甚至优于经过工程验证的基于约束的工具,如KLEE。但两类方法在不同的细分代码场景下也各有优劣。根据这些发现,我们提出了一种将两类技术结合使用的混合方法。该方法利用大语言模型的生成能力,辅以传统符号执行工具,在测试覆盖率提升方面取得了不俗的效果。
一、背景
自动化测试在过去几十年里备受瞩目,并取得了突出成就。一系列成熟的技术,如单元测试和覆盖引导式模糊测试,已经被广泛开发和验证,帮助软件从业者发现了许多关键的缺陷和漏洞。这些技术无疑为软件质量保驾护航,但现有方案也面临一个持续存在的挑战 - 如何进一步提高测试覆盖率?
为了解决这一难题,研究人员正在将基于约束求解的技术,如符号执行和动态符号执行等,融入传统的灰盒测试策略中。这种创新性的方法能够主动生成针对难以覆盖的代码分支的输入数据,大幅提升整体的测试覆盖水平。
随着大型语言模型(LLMs)的普及,研究人员将目光投向了这一前沿技术在自动化测试领域的应用。最近的工作着重于设计定制的提示语,以生成能够覆盖更多未覆盖目标分支的输入,这种想法与利用符号执行等技术的观点不谋而和。但是,大模型真的能有效理解代码语义并针对性地生成目标测试输入吗?另外,与传统的基于约束求解的方法相比具有显著优势吗? 这些问题尚未得到系统的探索与验证。
为了填补这一空白,本研究首次开展了大规模实证研究,来对比大语言模型和基于约束求解的方法在定向测试输入这一问题上的能力。通过严谨的实验设计和数据分析,我们旨在全面评估这两类技术在定向测试输入生成方面的性能,优缺点以及结合的潜力,为未来自动化测试方向的发展提供有价值的见解。
二、数据集
我们的数据集,验证框架以及论文预印版可以在这里获取:
https://github.com/CGCL-codes/PathEval
首先,为了解决缺乏标准数据集这一问题,我们提出了一种通过转换现有的代码生成数据集来构建求解定向测试输入数据集的方式。简单来讲,我们通过提取数据集中的测试用例,掩盖其中的测试用例的输入部分,并以其中的输出部分作为目标。接着,我们就可以驱动不同工具对能达成该目标(获得该特定输出)这一问题进行求解,从而考察其性能。我们对大模型代码任务最广泛使用的数据集(HumanEval),及其多语言扩展超集(HumanEval-X),进行了转换。成功构建了C++/Java/Python三种语言的,2000余样本的任务数据集。
接下来,我们深入研究了多种大语言模型工具(如ChatGPT和CodeLlama)以及基于约束的工具(如KLEE和Angr)在这一数据集上的表现。我们从不同的代码场景、编程语言、变量类型以及泛用性等角度,对各工具的性能进行了全面的分析和总结。
三、实验发现
我们发现了很多有趣的发现(更多请阅读我们的论文:https://github.com/CGCL-codes/PathEval/blob/main/PathEval_Preprint.pdf).
大模型的效果出人意料:在我们构建的数据集上,ChatGPT在表现上与广泛使用和研究的符号执行工具,KLEE相当。并且明显优于Python和Java语言的baseline(CrossHair和EvoSuite)。
大模型更加稳定和中庸: 大模型的求解能力相较于基于约束的工具更加稳定,但是却很难覆盖代码中的全部路径。相反,基于约束的工具表现出了更高的上限,但在某些情况却无法求解出任何路径。
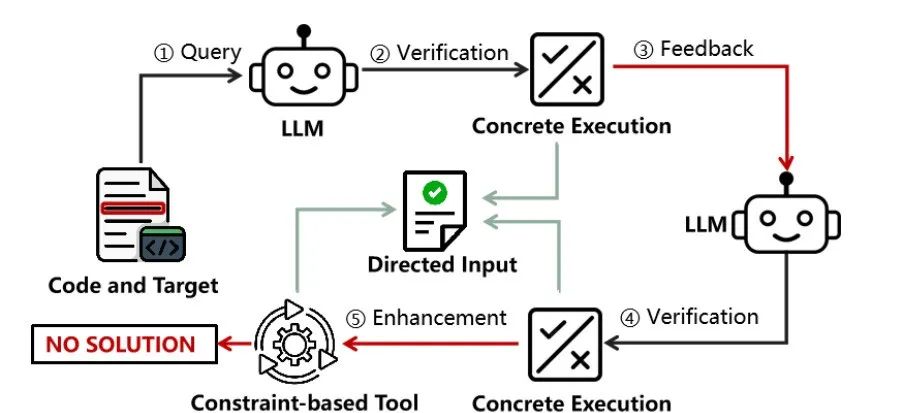
大模型和传统方法互有优劣: 大模型和传统约束求解工具的能力交叉很小,在不同的代码场景,输入类型等方面各有优劣。例如,在涉及外部知识的问题上,大模型通常有很好的效果,如生成一个合法的IP地址。但是,在另一些方面,比如在生成长字符串,长数组引索等问题上,大模型效果差于传统工具。这启发我们将两者进行结合,以获得更好的效果。
结合两者有更好的效果: 我们使用了一个流水线的方式将ChatGPT和KLEE等传统工具进行了结合,并且使用大模型的生成进一步优化了传统工具的变量符号化的声明。该工具相比于单独使用大模型或者传统工具,在求解能力上有1.4x-2.3x的提升,为未来的研究方向提供了思路。
四、研究团队
该论文发表在CCF-A类国际学术会议ASE 2024上,主要由华中科技大学网络空间安全学院课题组完成,论文信息如下:
@inproceedings{jiang2024towards,
title={Towards Understanding the Effectiveness of Large Language Models on Directed Test Input Generation},
author={Zongze, Jiang and Ming, Wen and Jialun, Cao and Xuanhua, Shi and Hai, Jin },
booktitle={39th {IEEE/ACM} International Conference on Automated Software Engineering,
{ASE} 2024, California, United States, October 27 - November 1, 2024},
year={2024}
}
华中科技大学ARTS3课题组(Advanced Research for Trustworthy and Secure Software Systems缩写)由文明副教授领导,主要开展系统软件安全、软件测试与分析、以及代码大模型等方面的研究工作,在系统软件、编程语言、软件工程等领域发表了CCF-A类文章50余篇,包括ASPLOS、EuroSys、OOPSLA、ICSE、FSE等,主持了国家自然科学基金青年项目、面上项目、以及多项企业合作项目,参与了湖北省尖刀攻关任务、湖北省重点研发项目等重要课题。近年来开展的针对基础核心软件系统的安全测试工作,已经成功在编译器、JVM 虚拟机、约束求解器等重要基础软件中发现了数百个重要缺陷或者漏洞,并在字节跳动、华为等企业开展了应用落地。课题组长期招收硕士博士以及博士后,具体可访问https://mingwen-cs.github.io/,或者直接联系文老师[email protected]。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh