2024-8-31 01:0:20 Author: hackernoon.com(查看原文) 阅读量:2 收藏
Authors:
(1) Suzanna Sia, Johns Hopkins University;
(2) David Mueller;
(3) Kevin Duh.
Table of Links
- Abstract and 1. Background
- 2. Data and Settings
- 3. Where does In-context MT happen?
- 4. Characterising Redundancy in Layers
- 5. Inference Efficiency
- 6. Further Analysis
- 7. Conclusion, Acknowledgments, and References
- A. Appendix
4. Characterising Redundancy in Layers
Recently, Sajjad et al. (2023) found that many layers in pre-trained transformers can be dropped with little harm to downstream tasks; moreover, it is well known neural MT transformer models are known have several redundant heads which are not necessary during test time (Voita et al., 2019b; Michel et al., 2019; Behnke & Heafield, 2021). However, it is not clear if the same trends hold for in-context MT models, and how that redundancy is related to task location versus task execution.
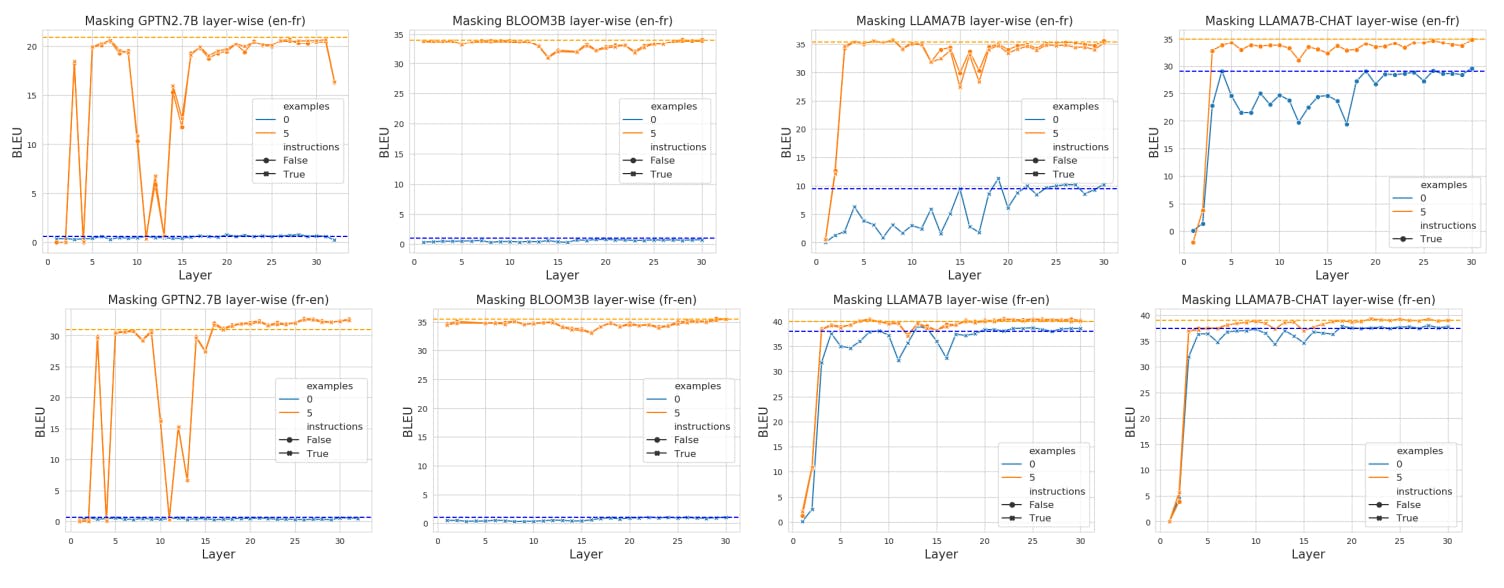
We study the contributions of individual attention-layers by performing a simple layer-wise masking of all self-attention heads for a single layer. When we mask layer j, we are masking the attention mechanism of layer j, that is the MLP of layer j acts directly on the output of layer j − 1, rather than the output of the attention-head of layer j. Doing so allows us to study how critical each layer is, where critical layers is loosely defined as those that have a large negative impact when masked.
We plot results for each layer all models, using the three combinations of {0 examples, no instructions}, {5 examples, instructions}, {5 examples, no instructions} in Figure 4. [3]
4.1. Are “Critical" Layers Task Locating Layers?
In Section 3, we observed that there are layers for task location. In this section, we observe evidence that there are critical layers which correspond to the task locating layers, providing support for our earlier observations.
For instance for LLAMA7B en → fr, even in the scenarios when examples are provided, we can see a dip in performance around layer 15 to 18. Refering back to Figure 2, we see that this is where most of the task location with large jumps in performance had occurred.
For GPTNeo, we obseve a large set of contiguous layers which significantly decrease performance at around layer 10 to 15. This also corresponds to where most of the task location (large jumps in performance) had occurred for this model in Figure 2.
We note that the critical layers in different models have varying degrees of severity. It is not immediately clear why GPTNEO has such critical layers and suffers compared to the other models, although we note that this is unlikely to be due to size or model architecture as BLOOM is also around the same size as GPTNEO and performs more similarly to LLAMA. We suspect that it could be due to training data or some other factor related to the training dynamics but leave this for future work.
With regard to redundancy, we find that layers can be more safely removed towards the end without a noticeable loss in performance. We observe that for the less stable models, the

model achieves close to baseline performance by layer-wise masking from ℓ15 for GPTNEO, ℓ26 for BLOOM and ℓ20 for LLAMA. This suggests that these later layers contain redundancy for translation.
Overall, observing redundancy in layers is not suprising, and our main contribution is characterising the differences between redundant and critical layers. To explain why models can have redundant layers, we refer to Clark et al. (2019) who identify a phenomena where attention heads attend almost exclusively to delimiter and separator tokens such as [SEP], periods and commas. This is thought to act as a “no-op" as the value of such tokens in changing the current hidden representation is very small. Note that it is then possible to mask entire Transformer layers and still achieve a sensible output due to residual connections in the Transformer architecture at every layer.
[3] The combination of {0 examples, no instructions} is not meaningful as the model only receives "Q: A:" as the input and is not expected to do the translation task.
如有侵权请联系:admin#unsafe.sh