2024-9-1 02:0:20 Author: hackernoon.com(查看原文) 阅读量:4 收藏
Authors:
(1) Athanasios Angelakis, Amsterdam University Medical Center, University of Amsterdam - Data Science Center, Amsterdam Public Health Research Institute, Amsterdam, Netherlands
(2) Andrey Rass, Den Haag, Netherlands.
Table of Links
- Abstract and 1 Introduction
- 2 The Effect Of Data Augmentation-Induced Class-Specific Bias Is Influenced By Data, Regularization and Architecture
- 2.1 Data Augmentation Robustness Scouting
- 2.2 The Specifics Of Data Affect Augmentation-Induced Bias
- 2.3 Adding Random Horizontal Flipping Contributes To Augmentation-Induced Bias
- 2.4 Alternative Architectures Have Variable Effect On Augmentation-Induced Bias
- 3 Conclusion and Limitations, and References
- Appendices A-L
2.4 Alternative Architectures Have Variable Effect On Augmentation-Induced Bias
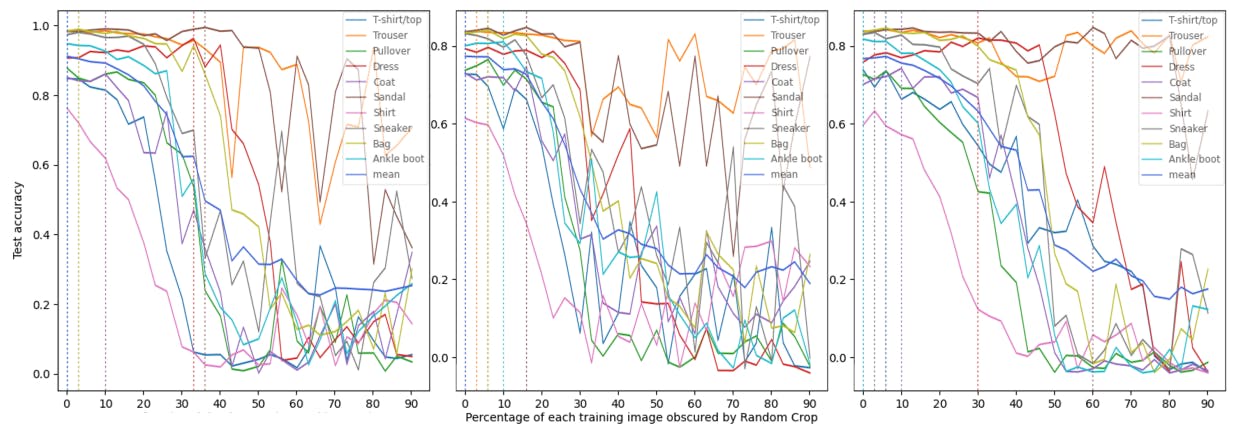
Having carried out a data-centric analysis of DA-induced class-specific bias, we dedicated the last series of experiments (see Figure 4) to a more model-centric approach to the phenomenon. Balestriero, Bottou, and LeCun (2022) illustrates that different architectures tend to agree on the label-preserving regimes for DA(α) - in other words, that swapping ResNet50 for a different model in the above experiments would not yield a notable difference in resulting class-specific and overall performance dynamics. To validate and expand on this claim, we recreated the experiment from Section 2.2 on the Fashion-MNIST dataset using another residual CNN, EfficientNetV2S, as well as a Vision Transformer in SWIN-Transformer.
The ”small” EfficientNetV2S (Tan and Le 2021) architecture was selected due to being a modern and time-efficient implementation of the EfficientNet family of models. The model was downloaded, tuned and optimized using a procedure matching previous sections. The EfficientNetV2S runs of this section’s experiments seemed to further validate the original assumption that the phenomenon appears to be modelagnostic (though data-specific), at least for the residual family of CNNs, as the different complexity and size of the architecture did have an effect on the speed of class-specific bias occurring as the random crop α was increased, but the general dynamics of how performance evolved were preserved. For example, as can be seen in Figures 4, deterioration in per-class accuracy begins to occur rapidly for ”Dress” at an α value of 30% for EfficientNetV2S, in contrast to 40% for ResNet50. For a full summary of the diverse α at which each class and mean test set performance reach their peak, see Appendix I.
With the previous section confirming the model-agnostic nature of the phenomenon as it pertains to residual CNNs, the final trial followed up by evaluating the performance of a SWIN Transformer, as the architecture is composed in a fundamentally different way, and can be adjusted to perceive images with a finer level of granularity via the patch size parameter. The model was prepared similarly to previous sections. As visible in Figure 4 and Appendix L, while the use of a Vision Transformer model did not entirely avert the overall class-specific bias trend as random cropping was applied more aggressively, it severely delayed

its heavier impacts, and even noticeably changed the behavior of certain classes (for example, maintaining the stability of the top performers in ”Trouser” and ”Sandal” even for very high values of α, while delaying ”Dress” and ”Coat”’s rapid deterioration in accuracy to 47% and 30% from 40% and 23%, respectively) in effect making the model-dataset combination more robust against the potential negative trade-offs data augmentation can bring. Despite this, and being similar in terms of computational requirements, its best performance achieved in practice was marginally lower than that of ResNet50 . While it does not outright disagree with Balestriero, Bottou, and LeCun (2022)’s model-agnostic proposition, the implications of this result are such that architectures for computer vision tasks can and should be chosen not just by best overall test set performance, but also based on other merits, such as robustness to bias and label loss resulting from aggressive data augmentations, especially in cases where such augmentations are expected to be applied en masse or without intensive monitoring, such as in MLOps systems with regular retraining.
While the above experiment does serve to illustrate the potential merit of applying alternative architectures in the context of regulating DA-induced class-specific bias, broader research is likely warranted. A natural direction of such an extension may be to continue with applying different families and instances of image-classifying neural network architectures to the task. One option is to expand the research utilizing SWIN Transformer by testing it on a further plurality of datasets with a wider variety of patch sizes, as the concepts of regulating the granularity with which the model learns to see details in images and the random cropping DA are conceptually adjacent. Following this, exploring the same problem with different Vision Transformers, such as the more lightweight MobileViT (Mehta and Rastegari 2021) or Google’s family of large ViT models (Zhai et al. 2022) is another step in that direction. Another possible direction to explore the model-specific degree of the phenomenon is to investigate how it pertains to Capsule Networks, first described in Sabour, Frosst, and Hinton (2017), as the architecture, once again, vastly differs from both Residual CNNs and Vision Transformers, and is generally considered to be less susceptible to variance from image transformations. This family of models is also very demanding to train, and would require a greater investment of resources or smaller scope than what our work had. As CapsNets are, at the time of writing, a very active area of research (Kwabena Patrick et al. 2022), we recommend this as a very valuable line of inquiry.
如有侵权请联系:admin#unsafe.sh